
The healthcare industry, despite being highly regulated, is one of the most targeted for breaches, necessitating tight measures. While these measures are necessary, they often restrict the free flow of information, critical for analysing patient outcomes and improving internal operations.
Tokenization has long been a reliable method for masking protected health information (PHI). But not all tokenization is created equal.
Why random tokenization without context is a risk
Tokenizing sensitive data protects it from risks and helps to comply with regulations. But adding a layer of disguise over its actual nature creates a number of new problems. Let’s understand them.
Context is key
Be it human or AI behind analysis, lack of context into data type degrades its quality and correctness. For example, if “John Doe” is replaced with “X1Y2Z3” in one record and “P9Q8R7” in another, the system or your team has no way to know these both refer to the same person. While generating insights, these tokens may be treated as different patients, risking incorrect outcomes, which may impact treatment quality.
Training takes a backseat
In a bid to prioritize privacy and compliance, companies are hurting AI capabilities. AI systems work by linking bits of data across multiple sources to analyse patterns. If the same data looks different across sources, it will draw incorrect conclusions, impacting the ability to improve over time.
Incorrect auditing
Finally, this lack of consistency also hurts auditing. If compliance teams need to trace every action involving “John Doe,” inconsistent tokens prevent accurate tracking. If the tokens are inconsistent or meaningless, you may not be able to map back to the original values for authorized users or auditors when needed. This can result in gaps during audits or investigations.
How Protecto solved this with contextual, deterministic tokenization
One of Protecto’s existing customers, a healthcare data analysis company, requested specific tokenization requirements for their use case. Their team had to analyse certain data sets manually – including sensitive information such as PII or PHI.
They wanted to demonstrate strong security practices to customers. But adopting security without affecting the quality of analysis was a challenge.
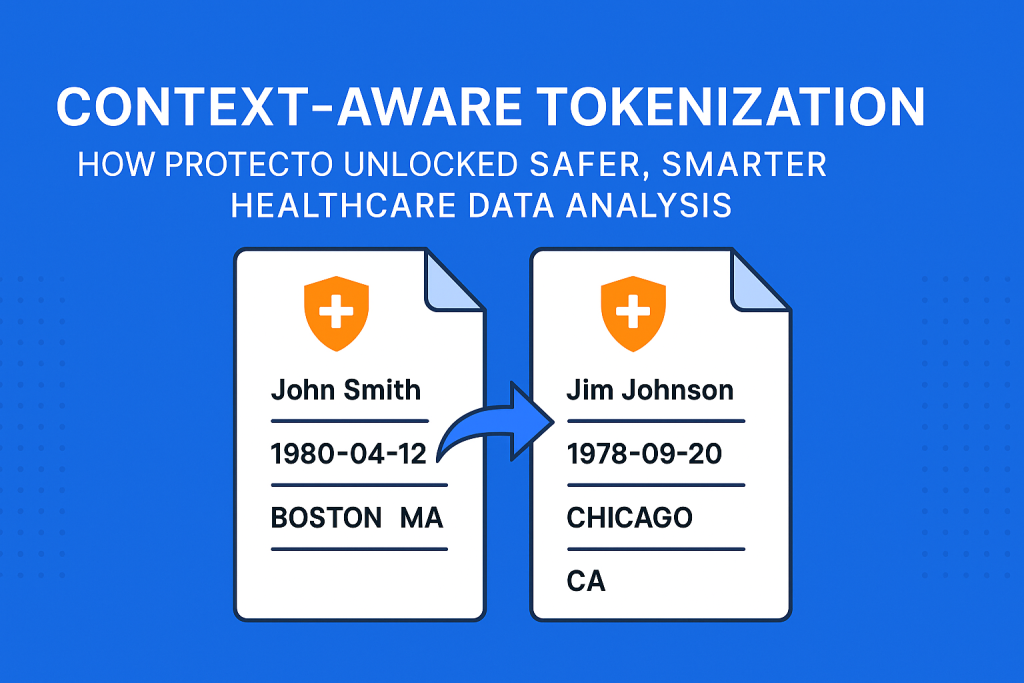
To address this challenge, Protecto enhanced the “mask with token” and “mask with format and token” approaches with context-aware replacement. Instead of meaningless placeholders, sensitive values are now swapped with realistic, context-preserving tokens.
For example,
- Names like “John” become realistic alternatives such as “Jim.”
- Dates are swapped for another valid date in the same format (YYYY-MM-DD).
- State names are replaced with another valid abbreviation, such as “California” becoming “TX.”
- City names are replaced with another real city, such as “Bengaluru” becoming “Delhi.”
After using smart tokenization, the healthcare company was able to balance security and productivity. Previously, the analytics team had no context of the data they handled, resulting in incorrect, incomplete, and often inaccurate reports.
Now, the team could intuitively and accurately analyse large data sets. They had full visibility into the context of what they were looking at. This visibility allowed them to ensure security without compromising on the quality of their service.
This subtle change has a big impact. Now, anonymized datasets retain readability and usefulness, while staying fully compliant with HIPAA and other healthcare regulations.
At Protecto, we recently developed an enhancement for healthcare data pipelines that makes tokenization smarter, more realistic, and more useful for both human teams and AI tools. By introducing context-aware replacement tokens, we are taking tokenization into the future.
Real-World Use Case
Healthcare businesses process massive volumes of PHI and PII for its healthcare clients. Their analysts need to extract actionable insights from structured datasets while ensuring privacy is never compromised. With traditional tokenization, context loss was creating friction for teams who needed to process, audit, and derive meaning from the data.
With Protecto’s enhanced tokenization, these teams can now:
- Review datasets that remain natural-looking, reducing cognitive load.
- Perform manual audits without confusion from random strings.
- Enable AI tools to analyze data without compromising accuracy.
For example, instead of seeing “xx123” in place of a patient name, analysts now see “Jim,” making patterns easier to detect while still protecting the original identity.
Why Context Matters for AI and Analytics
AI thrives on context. When PHI is replaced with context-aware tokens, AI systems can continue recognizing patterns and relationships. For example, deterministic tokenization ensures that “John Doe” is consistently replaced with “Jim Smith” across datasets. This allows algorithms to understand when multiple references point to the same individual, without ever exposing the real identity.
This also applies to dates, states, and cities—maintaining realistic structures allows for meaningful trend analysis, such as time-series studies, geographical clustering, and patient journey mapping.
Why This Is the Future of Tokenization
Random placeholders might hide sensitive values, but they also erase meaning. In healthcare, meaning is everything—accurate insights drive better patient outcomes, improved healthcare economics, and smarter operational decisions.
Context-aware tokenization bridges the gap between privacy and utility. It ensures compliance with strict regulations like HIPAA while still empowering teams and AI systems to work effectively. As AI becomes more embedded in healthcare workflows, maintaining both privacy and context will be non-negotiable.
Protecto’s work shows what’s possible: safer, smarter data protection that doesn’t sacrifice usability. This is the direction tokenization must take, and we’re proud to be leading the way.
Final Thoughts
At Protecto, our mission is to help enterprises innovate with AI while maintaining ironclad privacy. By evolving tokenization into a context-aware system, we’re proving that privacy and utility don’t have to be at odds. In healthcare, where lives and compliance are at stake, this advancement is not just a technical update—it’s a critical step forward.

