

AI convenience rides on a river of data: text, clicks, images, voices, locations, and metadata you didn’t know existed. The core question is not whether AI uses data but how it collects it, what it infers, and whether people truly agree to that. In other words, the impact of AI on user consent and data collection is not academic. It decides whether your product earns trust or burns it.
This guide explains the impact of AI on user consent and data collection – how data gets collected and inferred, what the law expects, and how to design consent and privacy controls that actually work. You’ll get checklists, examples, and patterns you can implement.
Consent in the Age of AI: What Has Changed
Classic consent looked like a checkbox under a long privacy policy. That’s not enough anymore because AI:
- Collects more: Logs, sensors, wearables, transcripts, public posts, partner feeds, and third-party data brokers.
- Infers new information: Models can guess health risks, income level, political leanings, or personal habits from benign inputs.
- Repurposes data: Information gathered for support or analytics can be reused to train models, personalize experiences, or build new features.
- Aggregates and correlates: Multiple datasets merged together reveal more than each set alone.
- Automates decisions at scale: Consent mistakes or unclear scopes multiply across millions of predictions.
What “Good Consent” Looks Like
Strong consent aligns three things: comprehension, choice, and control.
- Comprehension: Plain language that explains what data you collect, why, and for how long. Tell users if you’ll use data to train models or make inferences.
- Choice: Granular toggles. Separate core functionality from extras like personalization, ads, and model training. No bundling.
- Control: Easy ways to view, edit, export, and delete data, plus a log of what the system did with it.
The Data Pipeline: From Collection to Inference
To design consent that holds up, map your AI data lifecycle:
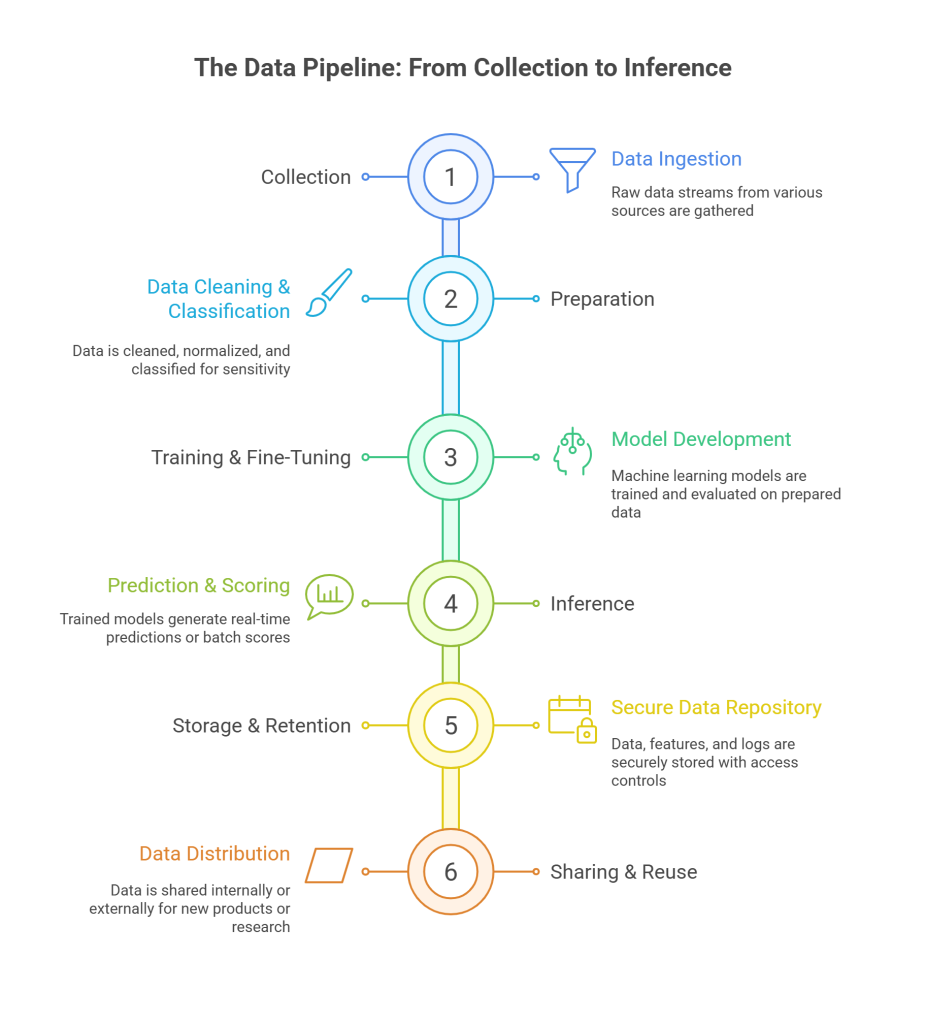
- Collection
- Inputs: forms, uploads, emails, chats, sensors, clickstreams
- Embedded data: EXIF in images, document metadata, timestamps
- Third-party sources: partners, public datasets, data brokers
- Preparation
- Cleaning, normalization, enrichment
- Classification of personal, sensitive, and special-category data
- Redaction or tokenization for regulated data types
- Training and Fine-Tuning
- Model selection, versioning, feature stores
- Data sampling and de-biasing
- Guardrails and evaluation
- Inference
- Real-time predictions or batch scoring
- Inputs can include previously collected data and embeddings
- Logging for safety, accuracy, and audit
- Storage and Retention
- Where raw data, features, and logs live
- Encryption, access control, and deletion deadlines
- Sharing and Reuse
- Internal teams, vendors, and APIs
- New products or research using “legacy” data
Data Types and Risk Levels
Not all data is equal. Prioritize transparency and controls for higher-risk categories.
| Data Type | Examples | Typical Risk | Strong Controls |
| Basic identifiers | Name, email, phone | Medium | Purpose-limited use, opt-out for marketing |
| Behavioral & telemetry | Clicks, session logs, device IDs | Medium–High | Clear analytics notice, short retention |
| Location | GPS, Wi-Fi triangulation | High | Precise opt-in, on-device processing where possible |
| Biometric | Faceprints, voiceprints | High | Explicit opt-in, strict storage, local compute preferred |
| Special category | Health, religion, union status | Very High | Explicit consent, de-identification by default |
| Inferred traits | Credit risk, mood, political preference | Very High | Transparent explanations, opt-out, human review |
How AI Changes “Notice and Choice”
Traditional privacy notices talk about what you collect. AI requires explaining what you can infer and how that inference affects users. Examples:
- “We analyze your support chats to improve responses and to train our language model. You can opt out of model training without affecting your support service.”
- “We estimate your churn risk from usage patterns. If the model’s confidence is low, a human reviews the case before making any decision.”
- “We personalize product suggestions using your purchase history and browsing behavior. Turn this off anytime in Settings.”
Law and Policy: The Big Principles You Must Respect
This article isn’t legal advice, but the main themes across modern privacy laws line up:
- Lawful basis: Have a legal ground for each data use. Consent is one, but not the only one.
- Purpose limitation: Don’t use data for new purposes without new consent or a compatible basis.
- Data minimization: Collect only what you need.
- Accuracy: Keep data used for decisions up to date.
- Storage limitation: Keep data only as long as necessary.
- Integrity and confidentiality: Protect data with appropriate security.
- Rights: Let people access, correct, delete, port, and object.
AI-driven inference increases your duty to explain logic, significance, and consequences when automated decisions have legal or similarly significant effects. That is central to the impact of AI on user consent and data collection: people must understand the decision pipeline, not just the intake form.
Designing a Consent Model That Scales
1) Granular Toggles
Offer separate switches for:
- Core service operation
- Analytics and product improvement
- Personalization
- Advertising
- Model training and evaluation
- Data sharing with partners
2) Contextual Timing
- Ask at the moment of collection, not weeks earlier.
- Use progressive consent: start with minimal data, ask for more when value is clear.
3) Duration and Renewal
- Set defaults like “expires in 12 months” for non-essential uses.
- Reconfirm when you introduce a new feature or materially change the purpose.
4) Proof and Audit
- Store consent records with user ID, scope, timestamp, and policy version.
- Log how the system honored consent in pipelines and exports.
- Protecto can attach policy decisions to each data flow, creating an audit trail
Data Minimization: Your Best Friend
Every field you collect is a liability unless it’s essential. Try these patterns:
- Edge processing: Run voice-to-text or basic analytics on device, sending only necessary outputs.
- Aggregation: Keep counts or trends, discard raw events.
- Pseudonymization and tokenization: Replace direct identifiers with reversible tokens for authorized processes.
- Selective retention: Keep features, not raw source data.
- Prompt redaction: Before sending content to an LLM, strip names, emails, and IDs.
The Gray Zone: Inferences and Derived Data
AI systems generate derived data from user inputs. Is that covered by consent? Usually it should be, especially when the inference drives decisions about people. Treat inferences with the same care as the raw inputs:
- Document which features feed each inference.
- Show users what the system inferred and why, when feasible.
- Provide a simple opt-out from personalization or automated decisions.
- For sensitive inferences, require explicit opt-in or use de-identified modeling.
Children, Sensitive Users, and High-Stakes Contexts
Some users and contexts demand extra care:
- Children and teens: Verifiable parental consent where required; default to minimal tracking; clear language.
- Health and finance: Use de-identified or masked data; human review for impactful decisions.
- Employment and education: Avoid opaque models for high-stakes determinations; give appeals and alternatives.
- Biometric data: Favor on-device templates, short retention, and strict vendor agreements.
Building the Privacy-by-Design Stack
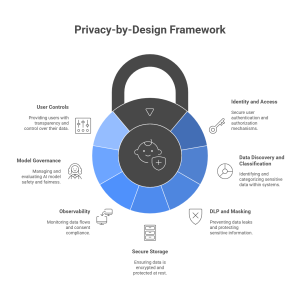
Marry policy with engineering. A practical stack looks like this:
- Identity and access: SSO, MFA, role-based access, least privilege.
- Data discovery and classification: Inventory data stores and tag sensitive elements.
- DLP and masking: Block secrets, redact PII before prompts and training sets.
- Secure storage: Encryption at rest, key management, segregated environments.
- Observability: Logs for data flows, consent checks, model inputs/outputs, and retention.
- Model governance: Versioning, evals, bias checks, safety filters, prompt-injection defense.
- User controls: Settings page to view/export/delete, plus a transparency dashboard.
Patterns for Transparent AI
Let users see enough to trust you:
- Data cards: Short summaries that list data sources, features, training windows, and known limitations.
- Decision notices: “This recommendation was generated by an AI system using your recent activity.”
- Confidence and sources: Provide citations or confidence levels for explanations.
- Feedback channels: Let users correct wrong inferences and report harmful outcomes.
- Model change logs: Notify users when a major model update affects personalization or decisions.
Small transparency gestures reduce confusion and support informed consent.
Case Snapshots: Doing Consent Right
1) Email Assistant for Sales
- Goal: Draft and summarize emails.
- Approach: Process on enterprise infrastructure; redact PII before training; opt-in for training distinct from base usage.
- Outcome: Users accept targeted consent prompts because value is clear. Protecto masks contact info in training corpora.
2) Fitness App With Wearable Data
- Goal: Recommend routines based on steps and heart rate.
- Approach: Edge analytics on device; encrypted sync; explicit opt-in for sharing with partners; dashboard to see all collected metrics.
- Outcome: Higher retention after shipping a “Why this recommendation?” explanation.
3) Support Chat Triage
- Goal: Classify and route tickets using LLMs.
- Approach: Customer data minimized; sensitive fields tokenized; training restricted to de-identified text with separate consent.
- Outcome: Accuracy improves while privacy risk drops; Protecto enforces tokenization at ingestion.
Engineering Playbook: From Intake to Inference
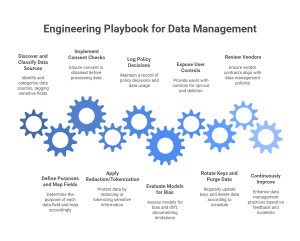
- Discover and classify data sources; tag sensitive fields.
- Define purposes and map each field to a purpose. If the purpose is unclear, drop or mask.
- Implement consent checks at the edge and in pipelines. No consent, no processing.
- Apply redaction/tokenization before storage, training, or prompts.
- Log policy decisions and keep an audit trail of data uses.
- Evaluate models for bias and drift; document limitations.
- Expose user controls for opt-out and deletion; verify with automated tests.
- Rotate keys and purge data on schedule; validate deletion with sampling.
- Review vendors and ensure contracts match your policy.
- Continuously improve based on feedback and incidents.
Communicating With Users: Words That Work
- Be specific. “We analyze your app activity to recommend features.”
- Name the model use. “We train our language model on de-identified support tickets unless you opt out.”
- Offer alternatives. “You can use the core service without personalization.”
- Set expectations. “We keep analytics data for 12 months, then aggregate and delete.”
- Invite feedback. “Tell us if a recommendation felt off; it helps improve the system.”
Clarity is good marketing. People reward honesty with attention and loyalty.
Third Parties and Data Sharing
Modern AI stacks rely on vendors: cloud hosts, analytics tools, labeling services, model providers, vector databases, and plugin ecosystems. For each vendor:
- Confirm lawful bases and scopes in your data processing agreements.
- Demand security standards, breach notice timelines, and deletion SLAs.
- Require they don’t repurpose your users’ data to train their open models without explicit agreement.
- Test that revocations cascade to vendors.
- Log every export and access with purpose codes.
When You Don’t Need Consent
Consent isn’t the only lawful basis. For purely necessary processing to deliver a requested service, consent may be redundant. Examples:
- Storing a shipping address to fulfill an order
- Processing a search query to show results
- Basic security logging for fraud prevention
Once you add personalization, targeted ads, or model training on user data, you’ve left the safe harbor of necessity. Gain clear consent or use de-identified data that cannot be linked back.
Handling Deletion, Portability, and Corrections
User rights are not a formality. Build them into your architecture:
- Deletion: Erase raw data, embeddings, and downstream caches. Include backups on a rolling schedule.
- Portability: Provide exports in machine-readable formats with clear field names.
- Correction: Let users update inaccuracies in profiles and inferences.
- Proof: Generate a short receipt showing what you deleted or exported and when.
Security Is Part of Consent
Users consent to you using data, not to you losing it. Pair consent with security basics:
- Encryption in transit and at rest
- Key management with rotation and least privilege
- Secrets management, not hardcoded credentials
- Strong identity controls, SSO, MFA, and conditional access
- Environment isolation for testing vs production
- Prompt-injection defenses and output filters for LLMs
- Continuous monitoring and tabletop breach drills
Frequently Asked Questions
Do I need consent to train models on support tickets?
If tickets contain personal data, yes in many jurisdictions unless you fully de-identify them. Best practice: de-identify by default and give an opt-out for training.
Is de-identified data always safe to use?
Only if you remove direct and indirect identifiers and prevent re-linking. Keep a documented risk assessment. Tools like Protecto can automate masking and tokenization to reduce re-identification risk.
What if a user revokes consent after we trained a model?
If feasible, retrain from fresh data or maintain training sets that exclude revoked records. At minimum, stop future use and delete their raw data and features.
Can we rely on “legitimate interests” instead of consent?
Sometimes for low-risk analytics, but not for sensitive categories, profiling with significant effects, or model training on personal data without safeguards. Err on the side of clarity and opt-in.
How do we handle partner data?
Treat it as if you collected it yourself. Verify the partner’s consent terms, scopes, and proof. Don’t commingle data sets with different legal grounds.
Protecto: Operationalizing Consent-Aware Data Practices
If you need help turning policy into practice, Protecto provides a privacy control layer for AI data flows:
- Automated discovery and classification: Find PII, PHI, PCI, secrets, and sensitive patterns across data lakes, event streams, and knowledge bases.
- Real-time masking and tokenization: Redact sensitive elements before storage, training, or LLM prompts. Reversible tokens allow authorized workflows without exposing raw data.
- Policy engine and DLP: Enforce purpose-based rules and block unauthorized exports, partner shares, or prompts.
- Consent enforcement hooks: Check consent scope at ingestion and inference, attach decisions to each record, and create an audit trail.
- Observability and proof: Dashboards and logs for deletions, data lineage, retention expirations, and vendor access.
- Developer-friendly integration: SDKs and gateways fit into RAG pipelines, feature stores, and inference endpoints with minimal code changes.

