

Large language models are no longer side projects. Sales teams rely on them for emails, support teams for ticket summaries, legal for first-draft reviews, and product teams for search and personalization. That ubiquity changes the risk math. Sensitive information flows through prompts, fine-tuning sets, retrieval indexes, analytics stores, and vendor logs. Regulators now expect the same discipline for LLM pipelines that they expect for core systems handling customer data. In practical terms, LLM Privacy Compliance Steps must be baked into how you collect data, prepare it, query it, and dispose of it.
Three forces make this year different. First, AI workloads are touching higher-risk data like health, finance, and identity. Second, model architectures have matured, which means executives expect production performance, not pilots. Third, audits are shifting from policy checklists to evidence. You’ll be asked to show how your pipeline masked PII, which sources fed a particular answer, and when cached vectors were deleted after a user requested erasure. Paper promises won’t cut it.
Turn Privacy Principles Into Engineering Rules
The classic privacy pillars still apply: lawful basis, purpose limitation, data minimization, integrity and confidentiality, and user rights. The difference with LLMs is where you implement them. For structured systems, controls sit at database boundaries. For LLMs, the riskiest points are earlier and later: when unstructured data is ingested, and when an answer leaves the model. That’s where your LLM Privacy Compliance Steps must be most concrete.
Think of your stack as five control zones:
- ingestion and preprocessing,
- storage and indexing,
- training and fine-tuning,
- inference and retrieval,
- retention and deletion.
Each zone needs specific, testable rules. Below, you’ll find the steps that make those rules real.
Step 1: Map the Data Your LLM Can Possibly Touch
You cannot protect what you haven’t cataloged. Start with a sweep across wikis, file shares, ticketing systems, CRM, product logs, and any partner data you import. Capture three attributes for each source: sensitivity (PII, PHI, PCI, secrets), provenance (who owns it and how it was obtained), and intended use (training, retrieval, analytics, or none).
Do not stop at files. Paint the full path: who can upload content, which services transform it, whether metadata hides inside (EXIF, tracked changes, author names), and where embeddings, caches, and evaluation logs are stored. A privacy control plane such as Protecto automates this discovery so you’re not chasing folders by hand.
Step 2: Tie Each Field To a Purpose and Legal Basis
A lawful basis is not a banner on your homepage; it is a mapping from specific data to specific uses. For each field that enters your pipeline, state why it is needed and on what ground you rely. Operational necessity covers core functions, but training models on user data, personalization, and partner sharing usually require consent or a compatible basis with guardrails.
Record these mappings in a form engineers can use. A small YAML policy is better than a slide deck. When the RAG pipeline fetches a document chunk, your runtime should already know whether that chunk is allowed for this user, in this region, for this purpose. If the purpose doesn’t match, the chunk simply never becomes a candidate for retrieval.
Step 3: Make User Choice Real, Not Decorative
Choice belongs in the product, not buried in legal text. Provide a control center where users can opt in to personalization and model training separately, see what categories of data you hold, and change their preferences without sending an email to support. Add just-in-time notices when new data is captured, and explain consequences in plain language.
For enterprise deployments, mirror those choices with admin policies. Business units often need different defaults. Sales may accept personalization on communications; legal will not. Record the decision with timestamp and policy version, so later you can prove that a prompt or training sample respected the user’s settings. If you need turnkey enforcement, Protecto can verify consent scope at ingestion and inference and attach the result to each record.
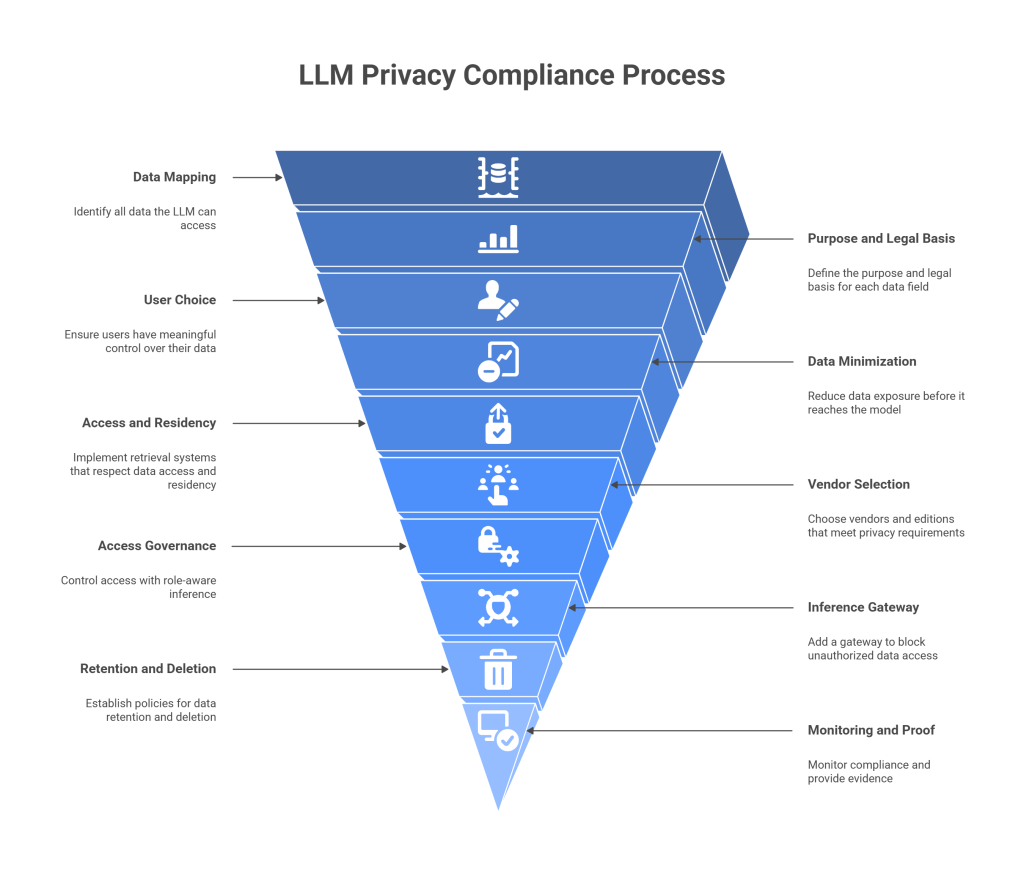
Step 4: Minimize Before Anything Touches a Model
Minimization is the most effective risk reducer. Strip names, emails, phone numbers, account numbers, API keys, and geotags before a model sees them. Replace direct identifiers with deterministic tokens stored in a vault. Keep the mapping in a separate, access-controlled system. Most LLM tasks don’t need raw identity to produce value. They need structure, language, and context.
Hard cases exist. Sometimes an answer must include a real account number or appointment time. Choose a pattern in which the model operates purely on masked text, then a post-processor re-links authorized identifiers only for users with permission. This pattern lets you keep privacy by default while still returning the details that users legitimately need.
Step 5: Build Retrieval That Respects Access and Residency
Retrieval-augmented generation (RAG) is the backbone of enterprise LLMs, and it’s also where leaks happen. Protect both sides of RAG: what you ingest, and what you retrieve.
At ingestion, sanitize documents. Remove headers with personal details, redact sensitive strings, flatten tracked changes, and normalize formats to strip hidden metadata. Tag each chunk with ownership, access control lists, and region. At retrieval, filter candidates by those tags before similarity search runs. When possible, keep regional indexes separate to avoid accidental cross-border access.
Finally, rerank candidates with a privacy lens. If two chunks match the query equally well and one is sensitive, prefer the safer chunk. A control layer like Protecto can enforce these constraints at both ingestion and retrieval without rewriting your entire application.
Step 6: Choose Vendors and Editions That Sign What You Need
Not all model endpoints are created equal. Consumer plans often use your prompts to improve services. Enterprise editions typically disable training on your inputs, offer data residency choices, and provide stronger admin controls. Pick the edition that matches your risk tolerance, then lock the promises into your agreements: data-use restrictions, retention limits, breach notice timelines, and deletion SLAs.
For every downstream vendor in your stack, require a data processing addendum that mirrors your promises to users. Confirm how they log requests, whether support staff can view content, where data is stored, and how fast they delete derivative artifacts like embeddings. If your policies say 30 days, your vendor cannot keep vectors for 180.
Step 7: Govern Access With Role-Aware Inference
Identity is the front line of privacy. Use SSO, enforce MFA, and provision via SCIM rather than hand-created accounts. Build roles that match actual jobs: support, sales, finance, engineering, legal. Tie those roles to purpose codes that control which data can be retrieved and which tools an agent can invoke.
When a user sends a prompt, pass the role and purpose code to the inference gateway so it can choose the right route: a public model for generic drafting, a private endpoint for sensitive prompts, or a masked-only path for regulated workflows. Log every decision with user ID, role, route, and outcome. These logs become your receipts during audit.
Step 8: Add an Inference Gateway That Can Say “No”
Do not let apps talk to models directly. A gateway screens prompts and outputs for policy violations, secrets, PII, and unsafe patterns. It blocks or rewrites risky content, selects the right model based on sensitivity and region, and appends context like user role and consent flags. Output filters scrub anything that slips through.
The same gateway should defend against prompt injection when your app reads untrusted content. Strip hostile instructions, remove hidden markup, and confine agents to approved tools with explicit arguments. The gateway is also your observability point: it’s where you count policy hits, track latency, and capture the end-to-end lineage of each answer. Protecto provides this layer across model providers so you can manage policy in one place.
Step 9: Retention, Deletion, and the Hard Parts People Forget
Deletion is where compliance goes to die if you don’t plan early. Define retention clocks for raw documents, transformed text, embeddings, caches, and logs. Clocks start at different times. A support ticket may be kept for a year; the embedding derived from it might warrant a shorter window. Keep the rules simple enough to implement and strict enough to matter.
When a user requests erasure, purge the source and every derivative: vectors, chunk stores, search caches, model-specific caches, and analytics tables. Produce a deletion receipt that lists what was removed and when. Design your training workflows so you can exclude revoked records from future runs. Even when you can’t untrain a current model, you can stop using revoked data going forward and remove it from evaluation and tracking sets. Platforms like Protecto orchestrate multi-store deletion and store the proofs you’ll need later.
Step 10: Monitor What Matters and Prove It
Compliance earns trust when it’s measurable. Track a small set of metrics you can improve every week:
- The share of prompts containing sensitive elements that were masked or blocked
- The rate of retrieval denials due to access or region rules
- average time to honor deletion requests across all stores
- redaction coverage for high-risk sources before ingestion
- incidents and mean time to remediation
Publish these in a privacy dashboard for internal stakeholders. Treat misses like operational defects, not legal problems. If a report shows low masking coverage for a new data source, fix the connector and watch the metric improve. Auditors appreciate steady curves more than slogans.
Avoid the Traps That Sink AI Privacy
Don’t rely on output filters alone. If you only scrub the answer, the model has already “seen” the sensitive content. Mask early, then filter again at the end. Don’t centralize every document without tagging ownership and access; you’ll create a one-click breach. Don’t forget the invisible stores: embeddings, eval datasets, developer logs, and analytics exports. Don’t treat consent like a banner; it must drive runtime decisions. And don’t make the safe path slower than the shadow path. When the official route is easier and faster, people follow it.
Where Tooling Fits Without Locking You In
You can build all of this yourself. Many teams do for a while, then discover they’ve created a privacy product inside their product. A neutral control plane reduces that burden. Protecto centralizes discovery across file systems and data lakes, masks and tokenizes sensitive elements at ingestion, enforces DLP and policy at inference, and coordinates deletion across stores with auditable receipts. Because it’s model-agnostic, you can change providers or add private endpoints without rewriting policy logic.
Even if you adopt a platform, keep ownership of your policies. Write them as code in your repos, manage them with the same rigor as infrastructure, and version them like any artifact. Tools should execute your rules, not define them.

