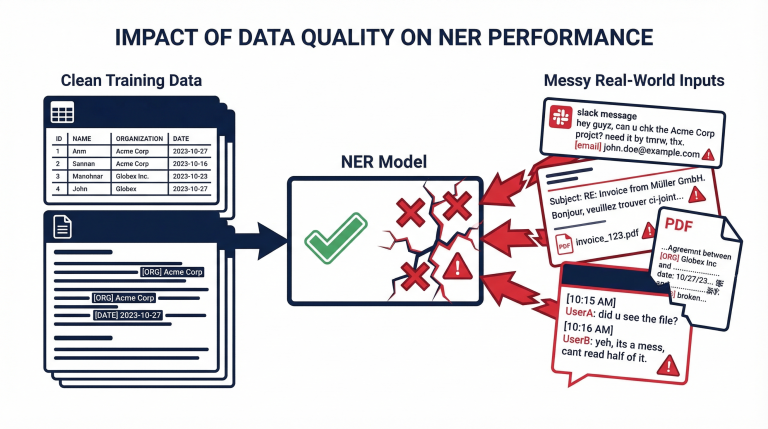
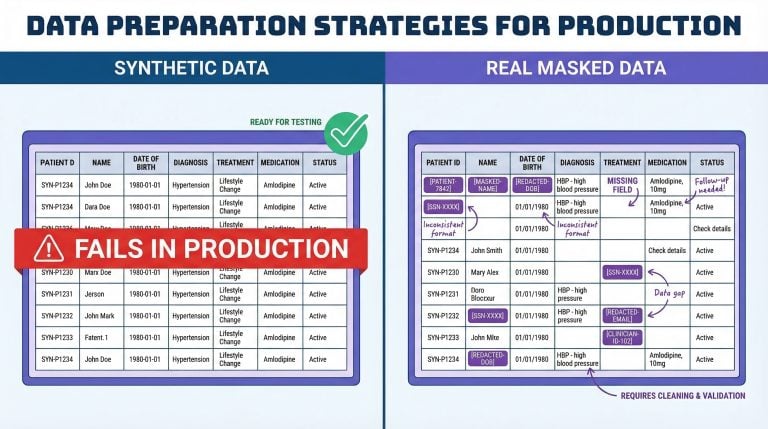
Prompt injection is often treated as a prompt engineering problem. It is not. When untrusted data is allowed to shape model behavior without clear boundaries, the system becomes fragile. This post explores why defending at the prompt layer is fundamentally reactive, and how shifting protection to the data layer creates a more durable, principled security model for AI systems....