

As more businesses integrate AI into their workflows, it opens the door to unprecedented security and privacy risks. Amidst LLM’s immense power and unmatched capabilities, concerns around security and privacy often take a backseat.
While some businesses deliberately ignore privacy concerns, the most common cause of this lack of concern is a gap in understanding the nature of the risks. This knowledge gap, combined with heightened regulatory scrutiny and changing compliance landscape, is leaving business leaders to manage risks in the grey.
A question often left unanswered – should you trust LLMs with sensitive data? The simple, shortest answer is – no. However, the explanation is more complex than a yes or no. Let’s break this down.
How LLMs interact with data: the privacy perspective
LLMs depend on datasets like emails, codes, product documents, and website content to continuously learn and improve. The bigger and more diverse the dataset, the more fluent and flexible the model becomes. It learns by crunching probabilities based on the data fed into it: which word is likely to follow another, what patterns emerge across contexts, and how meaning shifts with phrasing.
Even after training, LLMs rely on prompts/ inputs to generate better outputs. In short, it cannot function without data to learn, specialize, and respond well.
Now that we have established the significance of data for LLMs, let’s understand why this is a privacy problem.
Data fed into these systems can be broadly classified into two types: sensitive and non sensitive. When users interact with AI, in most cases, they don’t distinguish between sensitive and non sensitive data. The problem is, neither does AI.
Once AI ingests data, it is stored in its memory forever and cannot be unlearned. It cannot be removed, erased, or edited – think of it as a black hole of information. From a privacy perspective, this is a disaster.
Why should you be concerned? Common AI privacy problems
As LLMs ingest more data, they become the single largest repository for all types of sensitive information, including financial records, patient health information, intellectual property, and more.
Data usage without permission
One of the challenges of working with AI is data privacy risk, referring to the loss of control over personal or sensitive data. Users have no control or consent over how their personal information is collected, processed, stored, used, shared, or inferred.
Using individual data for purposes other than what was initially agreed on or disclosed is a direct violation of multiple regulations like DPDP and GDPR.
For example, a surgical patient in California discovered that her photos were used for training an AI dataset. She claimed to have given permission only for taking the photos, not using it on an open platform.
AI systems, by design, consume vast and often sensitive datasets, generalize patterns, and produce outputs that may leak or infer private information – even without direct identifiers. This compromises the right of individuals to determine when, how, and to what extent information about them is communicated to others.
Data exfiltation
For malicious actors, LLMs are a gold mine. A successful attempt at breaking into an LLM database is a jackpot. In this case, they don’t even need to break into servers – exploitation techniques like prompt injection, model manipulation, or insecure APIs to trick AI into leaking sensitive information.
If a model has access to internal documents or is connected to your knowledge base, attackers could engineer prompts to extract details like financial projections, customer records, or proprietary algorithms. In many cases, hackers have been known to use prompts that coerced LLM powered visual assistants to share private documents.
Data surveillance bias
Surveillance bias in the context of AI and privacy refers to the systematic distortion of outcomes or decisions caused by uneven data collection or observation. It is used to monitor individuals or groups without their consent.
The data collected from the surveillance is used to train or feed models. Since the dataset is skewed towards certain populations or behavior patterns, those groups are overrepresented, resulting in over enforcement or over prediction.
Data surveillance causes unintentional damage when used indiscriminately. For example, if a workplace uses AI to monitor productivity by recording keystrokes, emails, or meeting transcriptions across certain locations, the model will disproportionately learn from their behavior.
Now, if the AI flags more issues in the groups it sees more often, those groups are further scrutinized, creating a feedback loop. The surveillance bias becomes self-reinforcing: the more you watch someone, the more “evidence” you find – not because they’re riskier, but because they were heavily observed.
Real case studies of AI privacy violations that made headlines
It is not uncommon to believe that the whistleblowers of AI risks are fearmongering. This is a misconception as there are multiple cases of security incidents that make the headlines. Here are some of the most infamous cases:
Case study 1: Facebook and Cambridge Analytica
In 2014, Cambridge Analytica, a political data firm, obtained data from 87 million Facebook users not by hacking, but through an app that masqueraded as a personality quiz. Users gave consent to access their own data. The app also vacuumed up data on their friends, who never opted in.
This was made possible by Facebook’s API policies at the time, which allowed developers broad access to user and friend data. Ultimately, this oversight would later cost Facebook $5 billion in fines. It became perhaps the most well-known case of AI privacy violation due to:
- The AI systems were trained and deployed using data from people who never gave explicit consent, violating core principles of data minimization and purpose limitation.
- AI was used to infer private attributes like political leanings or sexual orientation from seemingly harmless behavior such as likes, clicks, and quiz answers. Users never knew or approved these high-risk inferences.
- The ad targeting mechanisms used AI models to deliver manipulative messages. These models operated in black boxes and users had no visibility, no control, and no ability to challenge how they were being profiled or targeted.
The consequences? Massive fines, global investigations, and calls for reform (including GDPR enforcement and U.S. congressional hearings). Post this incident, Facebook’s brand took a long-term hit and raised alarms about AI in election interference.
Case study 2: Clearview AI Facial Recognition
Clearview AI, a U.S. based facial recognition company, scraped over 3 billion images from social media platforms like Facebook, LinkedIn, and Twitter.
All this happened without users’ knowledge or consent to train an AI facial recognition model offered to law enforcement, private companies, and authoritarian regimes. Why was this a clear case of AI privacy violation?
- Clearview violated platform terms and user privacy by scraping public-facing images and using them to build biometric profiles.
- Individuals in the dataset never agreed to have their images used for facial recognition or surveillance purposes.
- The AI was used in policing contexts without oversight, raising civil liberties and mass surveillance concerns.
The consequences included a declaration by UK and Australian governments that ruled the data collection illegal and ordered data deletion. Italy and France fined Clearview millions of euros for GDPR violations. Platforms like Facebook, Twitter, and LinkedIn issued cease-and-desist letters. Ultimately, Clearview was banned from selling to private entities in the U.S. and restricted in multiple jurisdictions.
Case study 3: Google DeepMind & NHS
In 2015, Google DeepMind partnered with the UK’s National Health Service (NHS) to develop an AI app called Streams to detect acute kidney injury. While the intention was noble, the way patient data was handled sparked outrage and scrutiny. Here are of ways it violated privacy:
- 1.6 million patient records were shared with DeepMind by the Royal Free London NHS Foundation Trust without proper patient consent.
- Data included sensitive information like full names, medical histories, HIV status, and mental health records.
- The data was used not just for testing, but to actively develop and improve an AI product beyond the scope of the original agreement.
In 2017, the UK Information Commissioner’s Office (ICO) ruled that data sharing was illegal under UK data protection law. The NHS apologized publicly and faced reputational damage. This case triggered public debate over health data ethics, corporate partnerships, and AI governance in public healthcare.
Finding the right balance between privacy and productivity
Developers and businesses understand the implications of these concerns – on one hand, it is not possible to ignore or dismiss them. On the other hand, the capabilities of GenAI won’t improve beyond a certain point without data. This does not mean you miss out on the benefits of AI tools.
Protecto is designed to balance privacy and productivity in AI applications by reducing risks without hindering data utility. Here’s how it achieves this:
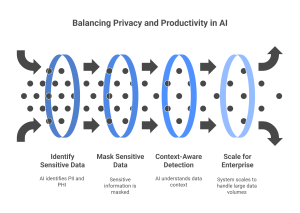
- Intelligent Data Masking: Protecto identifies and masks sensitive information, such as PII PHI, within AI prompts and responses, allowing AI models to operate on data without exposing sensitive details.
- Context-Aware Detection: Unlike traditional tools that rely on keyword matching, Protecto employs AI-aware masking techniques that understand the context of data. This approach reduces false positives and ensures that only genuinely sensitive information is masked, preserving the usefulness of the remaining data.
- Enterprise-Scale Support: Designed for scalability, Protecto offers dynamic auto-scaling and multi-tenant support, handling millions of data records daily with minimal latency. It integrates seamlessly with cloud and on-premise infrastructures.
Want to know how we helped businesses like yours protect their sensitive data? Schedule a demo to see how Protecto’s data protection platform can help.


