

In the evolving landscape of artificial intelligence, Large Language Models (LLMs) have become essential for natural language processing tasks. They power applications such as chatbots, machine translation, and content generation. One of the most impactful implementations of LLMs is in Retrieval-Augmented Generation (RAG), where the model retrieves relevant documents before generating responses.
As enterprises increasingly rely on LLMs for mission-critical applications, ensuring their accuracy and effectiveness is paramount. This is where LLM evaluation metrics come into play. Evaluating LLM performance is crucial for fine-tuning models and optimizing RAG performance. In this blog, we explore key LLM evaluation metrics, the importance of rag evaluation metrics, and how to evaluate RAG performance using structured frameworks and benchmarks.
What are LLM Evaluation Metrics?
LLM evaluation metrics provide a structured way to measure the effectiveness of large language models in various tasks such as language translation, text summarization, and content generation. These metrics quantify how well an LLM performs, offering insights into areas that require improvement.
A robust LLM evaluation framework ensures that models deliver high-quality outputs by maintaining accuracy, coherence, and contextual relevance. Evaluation metrics are crucial for ensuring that LLMs meet the desired standards of accuracy, relevance, and efficiency in their applications. These metrics also serve as benchmarks for comparing different LLMs and refining their outputs for specific applications, including RAG systems.
Why LLM Evaluation Matters for RAG?
Building a RAG system requires continuous iteration, including parameters fine-tuning, retrieval optimization, and prompt engineering. Each adjustment influences the quality of generated responses. This makes rag evaluation metrics critical for assessing and improving the system’s accuracy and relevance.
Effective LLM evaluation metrics help:
- Benchmark LLM accuracy metrics to ensure high-quality retrieval and generation.
- Measure RAG performance metrics to optimize retrieval and response generation.
- Identify and address issues such as bias, misinformation, and hallucinations.
With the right LLM evaluation framework, developers can systematically improve RAG models, ensuring reliable and trustworthy outputs. These evaluations minimize errors and reduce bias in AI-generated content, enhancing the overall performance and utility of RAG systems.
Core LLM Evaluation Metrics
Core LLM evaluation metrics include accuracy, precision, recall, F1 score, BLEU, ROUGE, perplexity, human evaluation, latency, and efficiency.
1. Accuracy: Measures how often an LLM’s predictions match the correct answers. High accuracy improves LLM model evaluation and enhances RAG performance by delivering more precise responses. It is a straightforward metric for evaluating LLM model performance, particularly in classification tasks.
Importance in RAG: High accuracy in LLMs translates to more reliable and trustworthy generated responses, enhancing the overall performance of RAG.
2. Precision: Indicates the proportion of retrieved results that are relevant (The ratio of relevant results to the total results returned by the model.) High precision reduces noise in generated responses, making RAG outputs more useful.
Importance in RAG: High precision means that the LLM can generate responses that are accurate and relevant, reducing the noise and ensuring the quality of information.
3. Recall: Measures how many relevant results were retrieved out of the total relevant results available (The ratio of relevant results returned by the model to the total relevant results available.) High recall ensures comprehensive coverage of relevant data in an RAG system.
Importance in RAG: High recall ensures that the LLM is comprehensive in its responses, capturing all the relevant information necessary for the task.
4. F1 Score: The F1 score is the harmonic mean of precision and recall. A high F1 score signifies a balanced model that retrieves relevant data without excessive false positives or false negatives.
Importance in RAG: A high F1 score ensures that the LLM accurately captures relevant information while minimizing errors, which is crucial for maintaining the integrity of the generated content.
5. BLEU (Bilingual Evaluation Understudy Score): Assesses how similar generated text is to reference human-generated text. This is crucial for maintaining the accuracy of RAG-generated responses.
BLEU score evaluates the accuracy of generated text against reference text, commonly used in machine translation. It compares the n-grams of the generated text to reference texts and provides a score between 0 and 1.
Importance in RAG: Higher BLEU scores indicate better alignment with human-generated text, an essential aspect for maintaining the reliability of RAG outputs.
In RAG, BLEU scores help gauge the accuracy and relevance of the generated responses.

Explanation
- Pn: Modified precision for n-grams of length n.
- ∑C∈{Candidates}: Sum over all candidate translations.
- ∑n-gram∈C: Sum over all n-grams in a specific candidate translation C.
- Countclip(n-gram):Clipped count of the n-gram. This count is clipped to the maximum number of times the n-gram appears in any of the reference translations to prevent over-counting.
- ∑C′∈{Candidates}: Sum over all candidate translations (same as the first summation but re-stated for clarity).
- ∑n-gram′∈C′: Sum over all n-grams in a specific candidate translation C′′.
- Count(n-gram′): Count of the n-gram in the candidate translation.
6. ROUGE (Recall-Oriented Understudy for Gisting Evaluation): ROUGE Measures the overlap of n-grams between generated and reference texts, focusing on recall. High ROUGE scores indicate better summarization capabilities in LLM summarization metrics.
It’s particularly useful for summarization tasks within RAG systems, ensuring the generated summaries capture the essential information from the source text. Variations of the ROUGE score include:
- ROUGE-N assesses the overlap of n-grams to judge the quality of content reproduction.

Explanation
- ROUGE-N: Measures the overlap of n-grams between the candidate text (model output) and the reference text (ground truth). It captures recall, i.e., how much of the reference text is covered by the candidate text.
- count_match(gram_n): The number of n-grams in the candidate text that match n-grams in the reference text. This is the numerator.
- count(gram_n): The total number of n-grams in the reference text. This is the denominator.
- ROUGE-L uses the longest common subsequence to evaluate the fluency and structure of the text.
Importance in RAG: High ROUGE scores indicate high-quality generation, which is crucial for RAG systems.
7. Perplexity: Perplexity is a fundamental metric for evaluating language models. It measures how well a model predicts a sample. Lower perplexity indicates better performance, meaning the model is more confident in its predictions.
Importance in RAG: For RAG systems, perplexity helps in assessing the fluency and coherence of the generated responses.
8. Human Evaluation: Despite the advancements in automated metrics, human evaluation remains essential. It involves assessing the model’s output for coherence, relevance, and fluency by human judges.
9. Latency: Latency refers to the time it takes for an LLM to produce an output after receiving an input. This metric is crucial for applications requiring real-time or near-real-time responses, such as chatbots, virtual assistants, and interactive AI systems.
10. Efficiency: Efficiency encompasses the computational resources required to run an LLM, including memory usage, processing power, and energy consumption. Evaluating efficiency is vital for understanding the cost and feasibility of deploying LLMs at scale.
LLM Evaluation Frameworks and Benchmarks
To ensure standardized evaluations, various LLM evaluation benchmarks and frameworks have been developed. These LLM evaluation frameworks help assess LLM performance metrics comprehensively. Notable frameworks include:
1. GLUE (General Language Understanding Evaluation)
- Description: Provides multiple NLP tasks to assess LLM accuracy metrics and retrieval performance in RAG applications.
- Relevance to RAG: Provides a comprehensive evaluation of the model’s language understanding capabilities, essential for effective retrieval and generation in RAG.
2. SuperGLUE
- Description: An advanced extension of GLUE, offering more complex tasks to evaluate LLM model accuracy in real-world applications.
- Relevance to RAG: Ensures that the model can handle complex and nuanced language tasks, improving the quality of RAG outputs.
3. SQuAD (Stanford Question Answering Dataset)
- Description: Measures how well LLMs retrieve and generate accurate answers, making it relevant for evaluating RAG accuracy metrics.
- Relevance to RAG: Measures the model’s ability to retrieve and generate accurate answers, crucial for RAG applications involving QA tasks.
RAG Evaluation Metrics
In Retrieval-Augmented Generation systems, evaluating both retrieval and generation components is crucial. Below are essential rag evaluation metrics:
- Retrieval Accuracy: Indicates how effectively the system retrieves relevant documents or information, directly impacting response quality. High retrieval accuracy indicates that the system can find and use the most pertinent information for generating responses.
- Relevance Score: Measures how contextually appropriate the retrieved information is. High relevance ensures precise, context-aware responses. t ensures that the retrieved documents or passages are contextually appropriate and useful for generating accurate responses.
- Response Coherence: Response coherence assesses the logical flow and consistency of the generated response. In RAG systems, it’s essential to ensure that the integration of retrieved information with generated text is seamless and coherent.
- Content Coverage: Content coverage measures how comprehensively the generated response covers the relevant aspects of the query. It ensures that the response addresses all critical points and provides a complete answer.
- Latency and Efficiency: Latency measures the time taken by the system to generate a response, while efficiency evaluates the computational resources used. In RAG systems, optimizing both latency and efficiency is crucial for real-time applications.
How to Evaluate LLM Performance in RAG
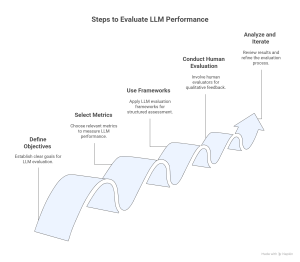
Evaluating LLM performance in RAG involves a combination of the above metrics and frameworks. To ensure reliable RAG systems, follow these steps for comprehensive evaluation:
- Define Evaluation Objectives
- Determine the specific goals and requirements of your RAG application, such as accuracy, fluency, relevance, and coherence.
- Select Appropriate Metrics
- Use a combination of core and advanced LLM evaluation metrics, such as BLEU, ROUGE, and retrieval accuracy.
- Leverage LLM Evaluation Frameworks
- Employ benchmarks like GLUE, SuperGLUE, and SQuAD to comprehensively evaluate your model’s performance across various tasks.
- Conduct Human Evaluation
- Complement automated metrics with human evaluation to gain qualitative insights into the model’s performance.
- Analyze and Iterate
- Regularly refine the model based on evaluation outcomes, improving RAG accuracy metrics over time.
Conclusion
A strong LLM evaluation framework is essential for optimizing RAG performance. By leveraging core LLM evaluation metrics, structured benchmarks, and human assessment, enterprises can build reliable and high-performing RAG applications. Whether measuring LLM accuracy metrics or refining retrieval performance, evaluating and optimizing these systems ensures high-quality AI-driven interactions.
By implementing the right rag evaluation framework, you can enhance your LLM-powered applications, ensuring they deliver precise, relevant, and efficient results for enterprise and consumer use cases.

