

If your company is shipping chatbots, copilots, or decision systems, you have probably heard the question many times: what is data privacy in AI, and how do we do it right. The answer is simpler than it looks. Data privacy in AI is a set of controls, policies, and practices that limit what personal or sensitive data you collect, how you use it, where you store it, and who can access it. When those habits are part of the build, AI products move faster, customers feel safer, and audits become routine.
As AI adoption grows, organizations are increasingly prioritizing data privacy and security in AI to reduce compliance risks, prevent data leaks, and build customer trust.
What is Data Privacy in AI
Data privacy in AI refers to the set of rules, designs, and technical controls that protect people when AI systems process their information. It covers the full life of data, from collection to deletion. It aims to prevent harm, such as identity theft, embarrassment, bias, or unwanted tracking, and to meet laws and contracts.
Said another way, AI privacy is about answering four questions at any moment
- What data do we have
- Why do we have it
- Who can access it
- How do we protect and delete it when asked
If you can answer those four questions with evidence, you are already far ahead.

Types of Data and Why Sensitivity Matters
Not all data carries the same privacy and security risk in AI systems. Treat the following categories with special care.
| Data type | Examples | Why it is sensitive | Typical protection |
|---|---|---|---|
| Identifiers | Name, email, phone, device ID | Enables direct contact or linking | Tokenization, masking, access limits |
| Financial | Card numbers, account IDs, transactions | Enables fraud and theft | Strong encryption, tokenization, scope control |
| Health, PHI | Diagnoses, prescriptions, lab results | Risk of harm and strict legal rules | Redaction, strict RBAC, audit logs |
| Biometrics | Face, voice, fingerprints, gait | Cannot be changed if leaked | Explicit consent, storage limits |
| Location | GPS trails, check ins, home address | Patterns reveal daily life and habits | Aggregation, k anonymity, residency controls |
| Children’s data | Accounts and usage by minors | Extra protections by law | Parental consent, data minimization |
| Metadata | Timestamps, referrers, IPs, device info | Can re identify users when combined | Minimize capture, aggregation, retention limits |
| Secrets | Access keys, tokens, credentials | Direct path to compromise | Secret managers, detection, redaction |
To understand how organizations classify and protect sensitive data, explore sensitive vs non sensitive PII
Where Risk Appears in the AI Lifecycle
Privacy risks cluster at a few steps. Understanding these stages helps organizations apply the strongest AI privacy controls where they matter most.
| Stage | What happens | Typical risks | Best control to apply |
|---|---|---|---|
| Ingestion | Collect logs, forms, tickets, call transcripts | Overcollection, hidden PII, unclear purpose | Classify on ingest, minimize, mask or tokenize |
| Preprocessing | Clean, label, split, embed | Leaks of identifiers into features or vector DBs | Tokenize IDs, redact entities in text |
| Training and tuning | Train base, fine tune, or reinforce | Weak legal basis, poor documentation | Dataset registers, data exclusion or masking |
| Retrieval and RAG | Index files and query knowledge bases | Indexing unredacted PII, verbatim returns | Redact before indexing, retrieval filters |
| Inference | Prompts, tools, and agent calls | Prompt injection, oversharing in output | Pre prompt scanning and output filters |
| APIs and integrations | Send or receive results | Response fields that overshare, egress risk | Response schemas, scopes, region routing |
| Logging and telemetry | Store traces and events | Secrets or PII in logs, long retention | Log redaction, shorter retention, secure stores |
| Monitoring and retraining | Drift checks and updates | Reintroducing sensitive data over time | Continuous classification, CI policy checks |
If you only have time for a few moves, do these first
- Tokenize or mask at ingestion
- Redact before prompts and before indexing for RAG
- Enforce API response schemas and scopes
- Keep lineage across the whole pipeline
A platform like Protecto can automate all four in one place, which reduces manual work and mistakes.
Myths and Facts
| Myth | Fact |
|---|---|
| AI needs raw personal data to be accurate | In most cases, tokenization or redaction keeps enough signal for training and analytics |
| Anonymized data cannot be traced back | Combined with other sources, many datasets can be re identified, especially with location and metadata |
| Policies and training are enough | You need technical enforcement in code, gateways, and pipelines, not only documents |
| Logs are harmless | Logs often capture secrets and personal data, so they need redaction and short retention |
| Banning tools is the safest path | Targeted guardrails let you enable safe use, which is faster and more scalable than blanket bans |
Real World Patterns to Learn From
You do not need a long list of brand names to learn the lesson. The failures repeat across sectors.
- Employees paste code, keys, or client data into public chatbots
Fix with pre prompt redaction, secret scanning, and enterprise LLM tenants that do not retain data - Fitness and location apps publish heatmaps that reveal sensitive sites or home patterns
Fix with aggregation thresholds, k anonymity, and strict defaults for private zones - Healthcare chatbots log patient notes or send data to third party analytics without proper contracts
Fix with PHI redaction before any logging, vendor allow lists, and no retention clauses - Bugs expose chat titles, snippets, or billing data between tenants
Fix with isolation testing, output filters, and schema checks that prevent oversharing - Prompt injection pulls private context or tool outputs from an assistant
Fix with instruction hierarchies, tool allow lists, and output scanning that strips sensitive entities
A privacy control plane like Protecto helps with each fix. It redacts inputs and outputs, enforces egress rules, and records the decisions for audits.
Laws and Frameworks in Plain Language
You do not need to memorize every clause. Translate rules into a short set of controls that engineers can build and auditors can verify.
| Rule set | Core idea | What you implement |
|---|---|---|
| GDPR and similar laws | Lawful basis, purpose limits, rights | Record legal basis, tag purpose at ingest, build access and deletion paths |
| EU AI Act | Risk based obligations and oversight | Document datasets and tests, add notices, keep human checks for high impact uses |
| HIPAA and health privacy | Special protection for PHI | Redact PHI in text, limit access by role, maintain audit logs for each view |
| State privacy laws | Notice, profiling rules, biometrics limits | Clear notices, opt outs where required, limited biometric processing |
| Cross border rules | Residency and transfer controls | Keep data local if required, tokenize or encrypt before transfer, restrict vendor regions |
Once these controls are in place, most audits become an exercise in exporting evidence. Protecto can provide that evidence, since it logs policy versions and data lineage for each request.
Privacy Enhancing Technologies Explained Simply
Start with the lightest tool that gives real protection. Add more advanced methods where risk or regulation requires it.
- Deterministic tokenization
Swap identifiers with repeatable tokens so joins and analytics still work. Guard the token vault and restrict re identification. - Contextual redaction
Detect and remove sensitive entities in free text, such as names, addresses, medical record numbers, or access keys, both at ingestion and pre prompt. - Masking
Hide parts of a value, for example last four digits of a card number, to reduce exposure while keeping format. - Differential privacy
Add controlled noise to aggregates so no single person can be picked out from the results. Use for reports and external sharing. - Federated learning
Train models across multiple data holders without centralizing raw data. Useful across regions or partner networks. - Encryption and secure enclaves
Protect data at rest and in transit. Use trusted execution environments for sensitive computations. - Role and attribute based access control
Limit access to the smallest set of people and systems needed for a task. Tie roles to purpose, not just to teams.
Platforms such as Protecto standardize tokenization and redaction, which cover a large share of practical risk, and then provide audit trails that prove those controls were in place.
A Working Architecture for Privacy by Design
You can design privacy controls into the path data takes through your AI stack. Here is a simple map you can adopt or adapt.
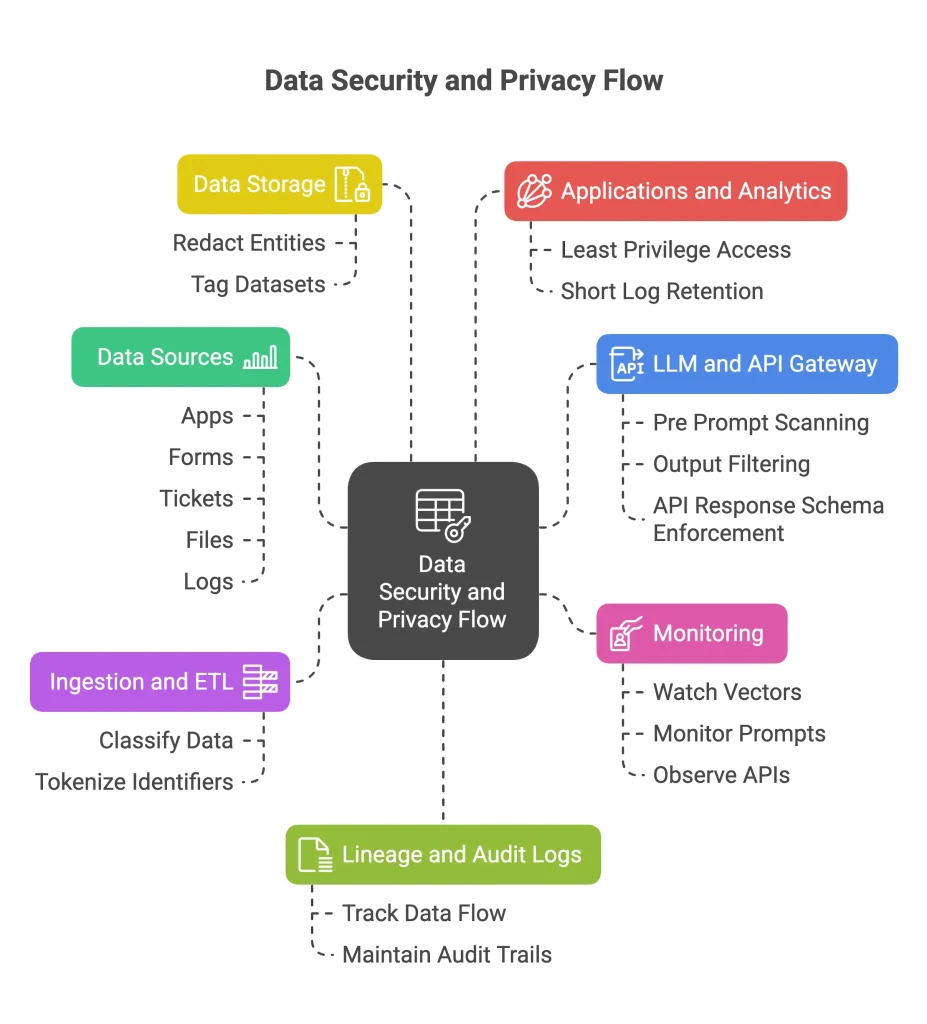
Protecto can serve as the control plane across these steps. It provides SDKs for pipelines, a gateway for LLMs and APIs, and dashboards for lineage and alerts.
A 30, 60, 90 Day Rollout Plan
Days 0 to 30, visibility and quick wins
- Connect discovery to your warehouse, lake, logs, and vector stores
- Tokenize top ten sensitive fields across the most used tables
- Enable pre prompt redaction for any public LLM calls and add secret scanning on paste
- Enforce response schemas and scopes on customer and billing APIs
- Run a shadow AI scan to find unapproved tools and unknown data paths
Days 31 to 60, governance and guardrails
- Write policy as code for purposes, residency, and disallowed attributes, then enforce in CI and at runtime
- Move to enterprise LLM tenants with no retention and tool allow lists
- Add lineage across ETL, embeddings, and model outputs, and export events to your SIEM
- Enable anomaly detection for vector queries and API egress patterns
- Run a data access and deletion drill and record time to complete
Days 61 to 90, proving and scaling
- Gate releases with impact assessments for high risk use cases and re run after material changes
- Add bias checks for models that affect credit, employment, housing, or health
- Extend controls to audio, image, and video so multimodal inputs receive the same protection
- Publish an internal trust dashboard that shows coverage, violations, and mean time to respond
- Update vendor contracts to include no retention modes, regional controls, and audit rights
Protecto can accelerate all three phases with prebuilt policies, SDKs, gateways, and audit exports.
Metrics
Pick a few metrics that match your risk profile. The targets below are realistic for most programs within two quarters.
| Area | Metric | Target |
|---|---|---|
| Discovery | Percent of critical datasets classified for PII, PHI, biometrics | Above 95 percent |
| Prevention | Percent of sensitive fields masked or tokenized at ingestion | Above 90 percent |
| Edge safety | Percent of risky prompts blocked or redacted | Above 98 percent |
| API guardrails | Response schema violations per ten thousand calls | Fewer than 1 |
| Monitoring | Mean time to detect a privacy event | Under 15 minutes |
| Response | Mean time to respond for high severity events | Under 4 hours |
| Rights handling | Average time to complete access and deletion requests | Under 7 days |
| Governance | Models with lineage and completed impact assessments | 100 percent |
Protecto can measure or evidence each metric so your reports reflect actual system behavior, not manual guesses.
Team Roles and Operating Model
Good privacy programs are cross functional, with clear ownership.
- Product and data science
Define use cases, acceptable inputs, and user disclosures. Own explanation features. - Engineering and MLOps
Implement classification, tokenization, redaction, schemas, and monitoring. Keep SLAs for detection and response. - Security and privacy
Write policy, maintain policy as code, lead impact assessments and vendor reviews, and run tabletop exercises. - Legal and compliance
Translate laws into plain controls and help validate evidence for audits and customer reviews. - Executive sponsors
Set objectives, approve budgets, and make it clear that privacy helps speed rather than slows it.
Protecto supports all groups with a single control plane and a single set of dashboards, which improves context and reduces handoffs.
Vendor and Partner Checklist
Use this list when you assess AI vendors, model hosts, analytics tools, and data partners.
- Data retention default off or short, with clear deletion paths
- Residency options by region, with documented sub processors
- Purpose scope defined and contractually limited
- Encryption at rest and in transit, with key management you control
- PII and PHI redaction or masking before logs, training, or retrieval
- Enterprise LLM modes such as no retention and isolated tenants
- Exportable evidence for enforcement events and lineage
- Support for access, correction, and deletion within set timelines
- Incident response times you can accept and test
If a partner cannot meet these points, consider an enforcement layer. Protecto can sit in front of vendors to filter prompts, mask responses, and prevent unapproved egress.
How Protecto Helps
Protecto is an AI privacy control plane designed to strengthen data privacy and security in AI systems. It reduces exposure by placing precise controls where risk begins, adapts policies to region and purpose at runtime, and produces the evidence your customers and auditors expect.
- Automatic discovery and classification: Scan warehouses, lakes, logs, and vector stores to find PII, PHI, biometrics, and secrets. Tag data with purpose and residency so enforcement is automatic.
- Masking, tokenization, and redaction: Apply deterministic tokenization for structured identifiers and contextual redaction for free text at ingestion and before prompts. Preserve analytics and model quality while removing raw values. A secure vault allows narrow, audited re identification when business processes require it.
- Prompt and API guardrails: Block risky inputs and jailbreak patterns at the LLM gateway, filter outputs for sensitive entities, and enforce response schemas and scopes for APIs. Add rate limits and egress allow lists to prevent quiet leaks.
- Jurisdiction aware policy enforcement: Define purpose limits, allowed attributes, and regional rules once. Protecto applies the right policy per dataset and per call, and logs each decision with policy version and context.
- Lineage and audit trails: Trace data from source to transformation to embeddings to model outputs. Answer who saw what and when, speed up investigations, and complete access and deletion requests on time.
- Anomaly detection for vectors, prompts, and APIs: Learn normal behavior and flag enumeration or exfil patterns. Throttle or block in real time to contain risk.
- Developer friendly integration: SDKs, gateways, and CI checks make privacy part of the build. Pull requests fail on risky schema changes, prompts are redacted automatically, and dashboards report real coverage and response times.
With Protecto, privacy becomes a daily habit inside your AI stack, not a quarterly scramble. That habit lets teams deliver features quickly, protect people, and pass audits with less effort.
FAQs
-
What is data privacy in AI?
Data privacy in AI refers to the set of rules, designs, and technical steps that protect individuals when AI systems process their information, encompassing the entire lifecycle from collection to deletion.
-
How does AI data privacy work?
AI data privacy works by applying controls such as tokenization, masking, encryption, and access restrictions to sensitive data processed by AI systems.
-
Why is data privacy important in AI systems?
Data privacy in AI is crucial for preventing harm, such as identity theft, bias, and unwanted tracking, while meeting legal requirements and building customer trust.
-
What types of data are most sensitive in AI?
The most sensitive data types include identifiers (names, emails), financial data, health information (PHI), biometrics, location data, children’s data, and access credentials.
-
Where do privacy risks occur in AI development?
Privacy risks appear at key stages: data ingestion, preprocessing, training, retrieval/RAG, inference, APIs, logging, and monitoring/retraining phases.
-
How can organizations implement data privacy in AI?
Organizations should implement tokenization/masking at ingestion, redact before prompts and indexing, enforce API response schemas, and maintain lineage across pipelines.

