

Earlier, the definition of “consent” was limited to banners that collect cookies. Today, modern LLMs ingest emails, tickets, docs, chats, and logs. They create embeddings, reference snippets with retrieval, and sometimes fine-tune on past conversations. If you do not wire user consent into each of those steps, you either violate laws, lose user trust, or both.
That is why user consent is revolutionizing LLM privacy practices. The decision a user makes in a settings page now needs to follow their data through ingestion, indexing, retrieval, inference, storage, and deletion. Consent is no longer a sentence in your privacy policy.
What changed: why the old consent model breaks with LLMs
The old model assumed data flowed into a few databases with clear schemas. You showed a dense policy, captured a one-time “I agree,” and that was that. LLMs broke those assumptions.
- Unstructured intake. Your model sees raw PDFs, email signatures, chat logs, transcripts, and screenshots with EXIF. Consent must apply before you parse and vectorize.
- Derived artifacts. A single document becomes dozens of chunks, embeddings, caches, and evaluation sets. Consent must travel with those derivatives.
- Dynamic reuse. Retrieval chooses context at query time. Even if training is clean, retrieval can surface something a user did not agree to share.
- Agents with tools. When an agent can read files or call APIs, a missing consent check turns into a data leak with one prompt.
A consent-first architecture. From checkbox to control plane
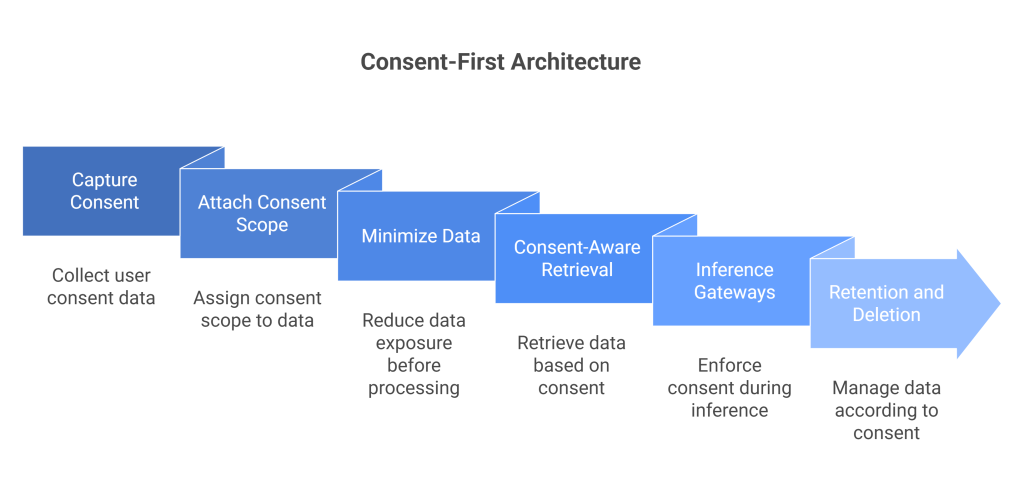
1) Capture consent you can compute on
Your consent UI should create a record with scope, timestamp, version, and purpose codes. Split essential processing from optional uses like personalization or model training. Store the record in a way that downstream systems can query. That makes consent machine-readable instead of legal-only.
2) Attach consent scope at ingestion
When new data arrives, enrich it with consent metadata. If the user opted out of training, their content should be labeled “no-train” at the very first step. If the user opted out of personalization, tag the record accordingly so retrieval cannot use it to tailor answers.
With Protecto, consent scope is checked at ingestion. Records get tagged before redaction and vectorization. If a record is out of scope, the system can block ingestion or route it to a masked-only path.
3) Minimize before models see anything
Consent limits what you may do. Minimization limits what you need to do. Redact direct identifiers and secrets at ingestion, then tokenize the few fields you must keep. Generate embeddings only from sanitized content. This preserves utility while preventing identity bleed.
4) Consent-aware retrieval
Most leaks come from retrieval. The fix is to filter candidates with consent, access, region, and sensitivity tags before similarity search returns context. If the purpose is support, retrieval should ignore chunks tagged for legal or analytics. If a user has opted out of personalization, avoid using their history to tailor answers. When candidates tie, prefer the safer chunk.
5) Inference gateways that honor consent at runtime
Route all prompts through a gateway that knows the user’s consent state. The gateway should block or rewrite inputs that conflict with preferences, choose a safer model route when consent is narrow, and scrub outputs that might reveal out-of-scope details. It should also log every decision for audits.
6) Retention and deletion that follow consent
Consent revocations should start clocks and deletions automatically. That means purging raw text, embeddings, caches, and evaluation sets. Emit a receipt that lists object IDs and stores removed. This “proof” mindset is covered in “How Cutting-Edge LLM Privacy Tech Is Transforming AI.”
What “good” consent looks like in an LLM app
Picture a support assistant. A user can:
- Read a one-paragraph notice that states the purpose.
- Toggle whether their tickets help improve models.
- See an estimate of data retention and a quick link to delete past tickets.
- Click “Why this answer” to view source snippets and how their own data did or did not influence the result.
Behind the scenes:
- Ingestion masks names, emails, and IDs.
- Each chunk carries tags for owner, region, purpose, sensitivity, and consent scope.
- Retrieval filters candidates by those tags.
- The inference gateway logs consent checks and policy hits.
- Deletion purges raw and derived artifacts and posts a receipt to the user’s account history.
If this sounds like a lot of plumbing, it is. This is why teams deploy a control plane. Protecto specializes in this layer, so engineering teams keep building features while consent logic stays consistent.
Common traps when teams try to “add” consent later
- Banner theater. You show a banner, but the system ignores it. If consent does not drive data flow, it is not real.
- Output-only filters. You scrub the final answer, but embeddings still contain identity. Ingestion masking must come first.
- One shared index. You mix regions, owners, and consent scopes in a single vector store. Retrieval cannot enforce rules it cannot see.
- Unscoped agents. An agent can read any file and call any tool. A single injected instruction turns into a leak.
- Deletion gaps. You delete files, but not vectors, caches, or eval sets. Users notice. Auditors do too.
How consent drives safer choices about training vs retrieval
There is a temptation to fine-tune models on everything. Consent pushes you to be selective. If a user opts out of training, you have two options. Respect the choice and use retrieval instead, or build a de-identified corpus with strong tests against re-identification. In many enterprise cases, retrieval is safer. It lets you enforce access and consent at query time. It also makes deletion straightforward.
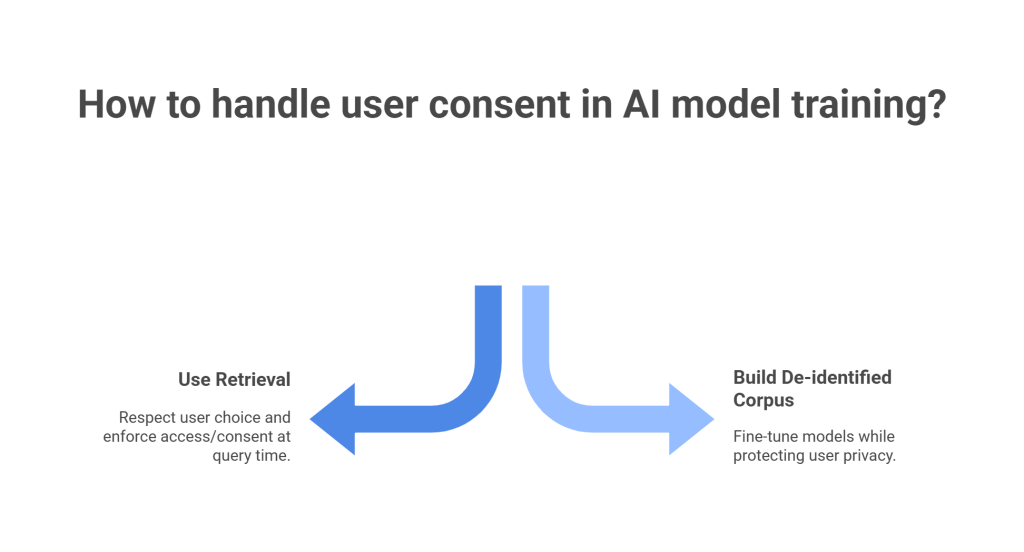
For workloads that truly need training, de-identify first. Keep corpora separate. Keep a short “data card” with sources, masking coverage, and consent mix. Exclude any record without clear authority. For an overview of training safety patterns, see “How LLM Privacy Tech Is Transforming AI.”
The legal angle. Short and practical
This article is not legal advice, but you will see common demands across modern privacy laws. Clear lawful basis, purpose limitation, data minimization, security safeguards, user rights, and explainability when automated decisions matter. Consent is not the only lawful basis, but it is the easiest to understand and the most visible to users. When in doubt, de-identify and minimize. When you must rely on consent, make it real, revocable, and enforced by code.
How Protecto operationalizes consent-first LLM privacy
If you want the benefits without building everything yourself, Protecto acts as a privacy control plane for LLM workflows.
- Consent-aware ingestion. Protecto checks consent scope on arrival, tags records with purpose and region, and blocks or routes content that is out of scope.
- Automated discovery and masking. It detects PII, PHI, PCI, secrets, and domain-specific patterns in text, PDFs, spreadsheets, images, and code. It masks or tokenizes before chunking and embeddings.
- Policy-aware retrieval. Filters candidates by consent, access, sensitivity, and region before similarity search. It prefers safer ties and logs provenance.
- Inference gateway with DLP. Screens prompts and outputs, enforces role and region routes, sanitizes untrusted content to resist prompt injection, and logs every decision.
- Deletion orchestration and receipts. Purges raw data, embeddings, caches, and vendor artifacts. Generates auditable receipts linked to user requests.
- Dashboards and audit bundles. Exports masking coverage, retrieval denials, consent mixes in training sets, and deletion SLAs. This matches the evidence checklists in “Mastering LLM Privacy Audits.”

