
Understanding the distinction between de-identification vs. anonymization is critical in today’s data-driven world. These processes are essential for safeguarding privacy while enabling the ethical use of data. Both techniques significantly meet regulatory standards such as GDPR anonymous data and HIPAA de-identified data requirements. However, their purposes and methods differ significantly.
Data privacy regulations have become stricter, making it crucial for organizations to adopt appropriate data protection strategies. De-identification and anonymization are two primary methods to ensure compliance while protecting individual privacy. Each approach offers unique benefits and challenges, making it essential to understand their differences.
What is De-Identification?
De-identification involves removing or masking identifiable elements from data. The process ensures compliance with privacy regulations while maintaining data utility.
Key Features
- Re-identification Possibility: De-identified data can be re-identified with additional information, making it suitable for controlled environments.
- Regulatory Compliance: Commonly used to meet HIPAA de-identified data
De-identification strikes a balance between privacy and usability. It allows organizations to analyze and share data while minimizing privacy risks. However, safeguards must be in place to prevent unauthorized re-identification.
Examples of De-Identification Techniques
- Masking: Obscures specific data points, such as names or phone numbers.
- Data Suppression: Removes sensitive fields entirely.
- Tokenization: Replaces identifiers with tokens that can be reversed under strict controls.
These methods allow organizations to share data securely while retaining its analytical value. They are widely used in healthcare and finance industries where data privacy is paramount.
Interested Read: Data Tokenization Guide
Challenges in De-Identification
While de-identification reduces the risk of privacy breaches, it is not foolproof. Sophisticated attackers can potentially re-identify data by combining it with external datasets. Organizations must implement robust security measures to mitigate this risk, such as encryption and access controls.
What is Anonymization?
Anonymization is the process of irreversibly removing identifiable elements from data. Unlike de-identification, it ensures that data cannot be linked back to individuals.
Key Features
- Irreversible Process: Once anonymized, data cannot be re-identified.
- GDPR Compliance: Meets the stringent requirements for GDPR data anonymization.
Anonymization provides the highest level of privacy protection. It eliminates the risk of re-identification, making it suitable for public data sharing and open data initiatives.
Examples of Anonymization Techniques
- Aggregation: Combines data points to create summaries, such as average age.
- Generalization: Broadens specific data values to reduce identifiability, like changing a birth date to a birth year.
- Noise Addition: Introduces random variations to data to obscure individual details.
These techniques ensure maximum privacy but may limit data usability for detailed analysis. They are ideal for scenarios where privacy is the top priority.
Challenges in Anonymization
Achieving proper anonymization can be complex. Over-anonymizing data may render it less valid for analysis while under-anonymizing increases privacy risks. Advanced techniques like differential privacy and synthetic data generation are often required to balance these trade-offs.
Key Differences Between De-Identification Vs Anonymization
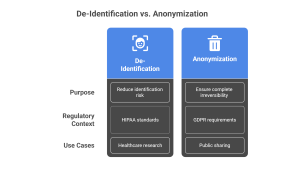
Purpose and Scope
- De-Identification: Focuses on reducing identification risk while retaining the option for re-identification in controlled scenarios.
- Anonymization: Ensures complete irreversibility, prioritizing privacy over data utility.
The choice between these methods depends on the intended use of the data and the level of privacy required.
Regulatory Context
- HIPAA Standards: Emphasize de-identification for handling protected health information (PHI).
- GDPR Requirements: Highlight anonymization, distinguishing it from personal data under anonymization vs de-identification GDPR
Regulatory frameworks play a significant role in determining which method to use. Organizations must align their practices with relevant laws to avoid penalties.
Use Cases
- De-Identified Data: Used in healthcare research where re-identification might be necessary for longitudinal studies.
- Anonymized Data: Suitable for public sharing, ensuring no risk of privacy breaches.
Both methods have specific applications, making it essential to choose the right one based on the data’s purpose and sensitivity.
Regulatory Implications
GDPR Perspective
The GDPR anonymous data standard differentiates anonymized data from personal data. Anonymized data falls outside GDPR’s scope, offering more flexibility in usage. In contrast, de-identified vs anonymized data under GDPR is still considered personal data if re-identification is possible.
GDPR encourages organizations to adopt anonymization for maximum privacy protection. However, achieving proper anonymization can be challenging, requiring advanced techniques and thorough validation.
HIPAA Perspective
Under HIPAA, de-identified data HIPAA guidelines outline specific methods for protecting PHI. The safe harbor method and expert determination are commonly used to achieve compliance while enabling data sharing.
HIPAA’s focus on de-identification reflects its emphasis on balancing privacy with data utility. This approach supports healthcare innovation while safeguarding patient information.
Pros and Cons of De-Identification and Anonymization
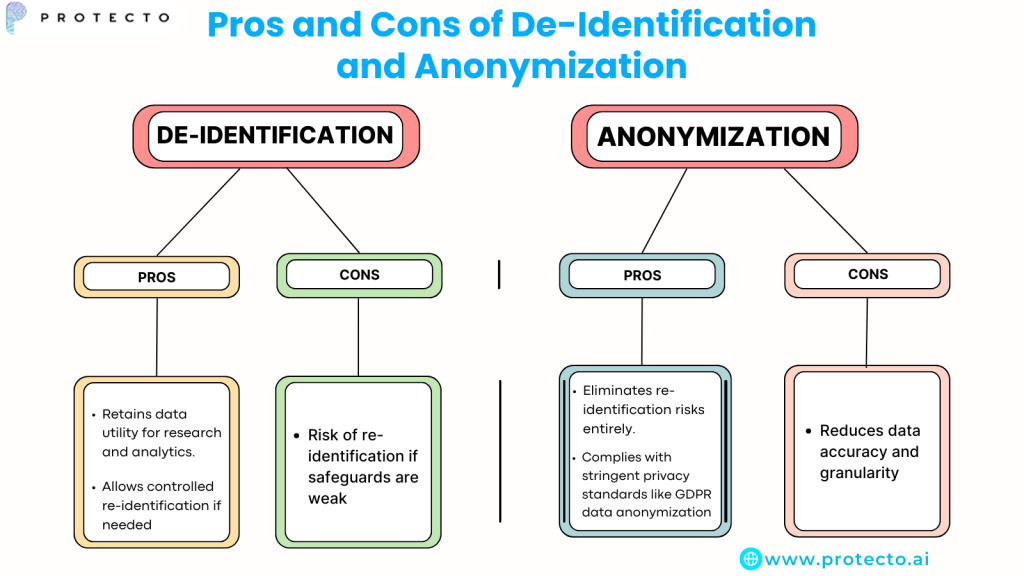
De-Identification
Pros:
- Retains data utility for research and analytics.
- Allows controlled re-identification if needed.
Cons:
- Risk of re-identification if safeguards are weak.
De-identification offers flexibility but requires robust security measures to prevent misuse. It is ideal for scenarios where data needs to be analyzed or shared within a controlled environment.
Anonymization
Pros:
- Eliminates re-identification risks.
- Complies with stringent privacy standards like GDPR data anonymization.
Cons:
- Reduces data accuracy and granularity.
Anonymization prioritizes privacy but may limit the data’s analytical value. It is best suited for public data sharing and open collaboration initiatives.
Real-World Applications
De-Identification
- Healthcare Research: Enables analysis of de-identified patient data while protecting privacy.
- Internal Analytics: Supports organizational decision-making without exposing sensitive information.
- Clinical Trials: Allows researchers to track patient outcomes over time while maintaining confidentiality.
De-identification is widely used in industries like healthcare, where data utility and privacy must be balanced. It allows researchers to derive insights while minimizing privacy risks.
Interested Read: Healthcare Data Masking: Tokenization, HIPAA, and More
Anonymization
- Public Data Sharing: Facilitates open data initiatives without compromising privacy.
- Open Data Projects: Encourages collaboration by ensuring data cannot be traced back to individuals.
- Educational Research: Supports public health and social science studies by providing fully anonymized datasets.
Anonymization is essential for scenarios where data will be shared with external parties or the public. It ensures compliance with privacy regulations while enabling innovation.
Choosing the Right Approach
Selecting between de-identification vs. anonymization depends on several factors:
- Data Sensitivity: Highly sensitive data may require anonymization.
- Intended Use: Research projects may benefit from de-identification, while public sharing necessitates anonymization.
- Regulatory Requirements: Aligning with laws like GDPR and HIPAA ensures compliance.
- Technological Capabilities: Advanced tools and techniques may influence the feasibility of proper anonymization.
Understanding these factors helps organizations choose the appropriate method for their needs. A thoughtful approach can balance data utility with privacy protection.
Conclusion
Recognizing the differences between de-identification vs. anonymization is essential for protecting privacy and meeting regulatory standards. Organizations can balance data utility with robust privacy safeguards by adopting the right approach. Protecto offers advanced solutions to help businesses navigate these challenges effectively. Secure your data with Protecto today.


