

Modern stacks push personal and regulated data through microservices, data lakes, event streams, vector stores, and LLM prompts. Encryption still matters, but it protects containers, not behaviors. As soon as an app decrypts a record, risk comes roaring back.
Advanced data tokenization solves this by replacing raw values with structured surrogates while keeping the real values under control. Done right, tokenization shrinks the breach blast radius, clarifies cross-border flows, and makes deletion and audits tractable.
This guide collects what actually works in production today, the design choices that matter, and the trends shaping tokenization in 2025, including how LLMs and retrieval systems change the requirements.
Tokenization in one minute: what it is and isn’t
- Tokenization: swap a sensitive value (card number, email, national ID, access key) for a token that preserves format and sometimes order. The mapping between token and original lives in a controlled vault.
- Encryption: transforms data using a key. Decrypt and you get the original back anywhere the key is allowed.
- Hashing: one-way transformation, good for checking equality, not for restoring values.
- Pseudonymization: an umbrella term that includes tokenization and other techniques that reduce direct identifiers.
Why organizations blend techniques: encrypt storage for defense in depth, tokenize to limit who ever needs to see raw values, and hash where you only need matching.
The core design choices that decide success
Deterministic vs non-deterministic
- Deterministic tokens always produce the same token for the same input within a scope. Perfect for joins, identity stitching, and deduplication.
- Non-deterministic tokens change each time. Better for one-off disclosures or when linkability itself is a risk.
Best practice: default to deterministic per namespace (for example, per tenant or per region) so you can join safely without enabling unwanted cross-domain linking.
Vaulted vs vaultless
- Vaulted designs store the original values in a secure service and return a token. Simple to reason about, strong control, but adds latency and an availability dependency.
- Vaultless designs generate tokens via cryptographic functions without a central store. Great for scale, but revoke and deletion workflows get trickier.
Best practice: use a hybrid model. Vault for high-risk identifiers that may require reversible access and deletion receipts. Vaultless for high-volume, low-risk attributes where you only need stable matching.
Format-preserving, value-preserving, and constraints
- Format-preserving tokens match patterns like 16-digit cards, email syntax, or E.164 phone numbers so downstream validation passes.
- Value-preserving properties like ordering or numeric ranges matter for analytics. For example, preserving the last 4 digits for customer support.
- Constraints: ensure tokens never collide with real values and maintain checksums (Luhn for card numbers) when required.
Best practice: treat each field as a product requirement. Write a mini spec: format, deterministic scope, which parts to preserve, and which contexts may detokenize.
Token domains and scoping
- Domain-scoped tokens prevent correlation across regions, products, or tenants. The same email can map to different tokens in EU vs US.
- Key rotation and re-tokenization must be possible without breaking joins or history.
Best practice: bake domain and version into token metadata. When you rotate, you can re-tokenize selectively and keep lineage.
Where tokenization belongs in modern architectures
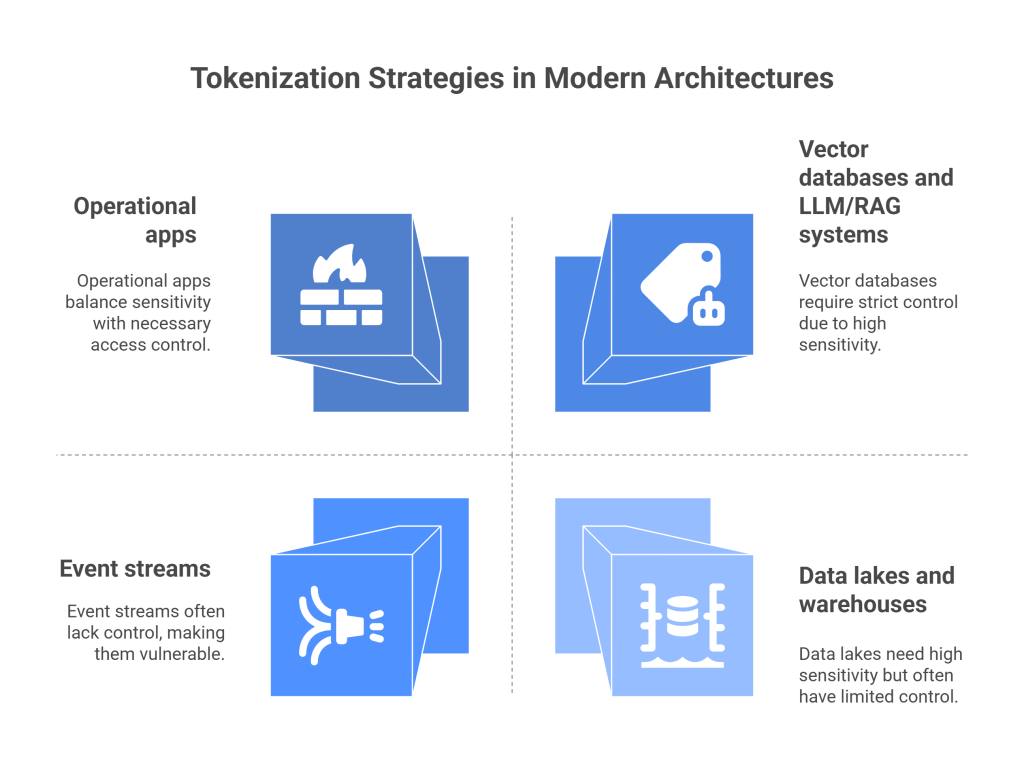
Operational apps
APIs, microservices, and databases should store tokens by default. Only specific, audited paths detokenize, and only for roles that truly need raw values.
Data lakes and warehouses
Keep raw zones strictly controlled. Land sensitive fields as tokens in curated zones. For analytics that need buckets or order, use derived tokens that encode ranges but never raw values.
Event streams
Kafka and pub/sub topics often leak. Tokenize at producers to ensure downstream consumers rarely touch raw values.
Vector databases and LLM/RAG systems
Never embed raw PII or secrets. Tokenize identifiers before chunking and embeddings. Keep reversible mappings out of the AI path. Retrieval returns masked text, and the app re-links identifiers only for authorized viewers.
Where Protecto helps: discovery and masking at ingestion, token vaults for reversible IDs, and policy-aware enforcement across RAG, prompts, and outputs.
Advanced Data Tokenization vs encryption: when each wins
| Goal | Tokenization | Encryption |
| Limit who can ever see raw data | Strong. Reversible only via policy-gated detokenization | Weak after decryption in app memory |
| Preserve format for downstream systems | Strong with FPE-style tokens | Weak unless you decrypt first |
| Enable joins and analytics without raw values | Strong with deterministic domains | Weak. Requires decrypt or preprocessing |
| Prove deletion and honor DSARs across derivatives | Strong with token vault lineage | Mixed. Keys and multiple copies complicate proof |
| Minimize cross-border exposure | Strong via domain-scoped tokens | Mixed. Decryption in wrong region is easy to mess up |
You still encrypt disks, backups, and pipes. Tokenization sits closer to business logic and user journeys.
The 2025 trends changing tokenization programs
1) Multi-region by default
Data residency rules and customer expectations push teams to scope tokens per region and keep mappings local. Expect region-aware token domains with automated routing.
2) AI-native tokenization
LLMs are now part of everyday workflows. Teams sanitize content at ingestion, generate embeddings only from tokenized text, and add policy checks at inference to prevent detokenization in model context. RAG retrieval filters out chunks that contain tokens a viewer isn’t allowed to re-link.
3) Policy-as-code
Instead of PDF policies, organizations ship YAML or JSON rules that define which fields are tokenized, how detokenization is authorized, and what audit events must fire. CI/CD runs privacy tests to block releases when token coverage drops.
4) Deterministic matching with noise controls
To curb linkage risk, teams combine deterministic tokens with salted scopes, time windows, or k-anonymity thresholds for analytics exports.
5) Lifecycle receipts
Regulators and customers want proof. Token services now emit receipts for creation, access, detokenization, and deletion. Auditors get IDs, timestamps, reason codes, and actors.
6) Streaming and edge
Mobile and IoT apps tokenize on device or at the edge gateway, cutting risk before events hit the core. Edge vaults cache short-lived maps with strict eviction.
7) Vendor-neutral control planes
Heterogeneous stacks need one brain for discovery, tokenization, DLP, and audit. Neutral layers like Protecto sit above clouds and model providers to keep rules consistent.
Best practices that stand up under real load
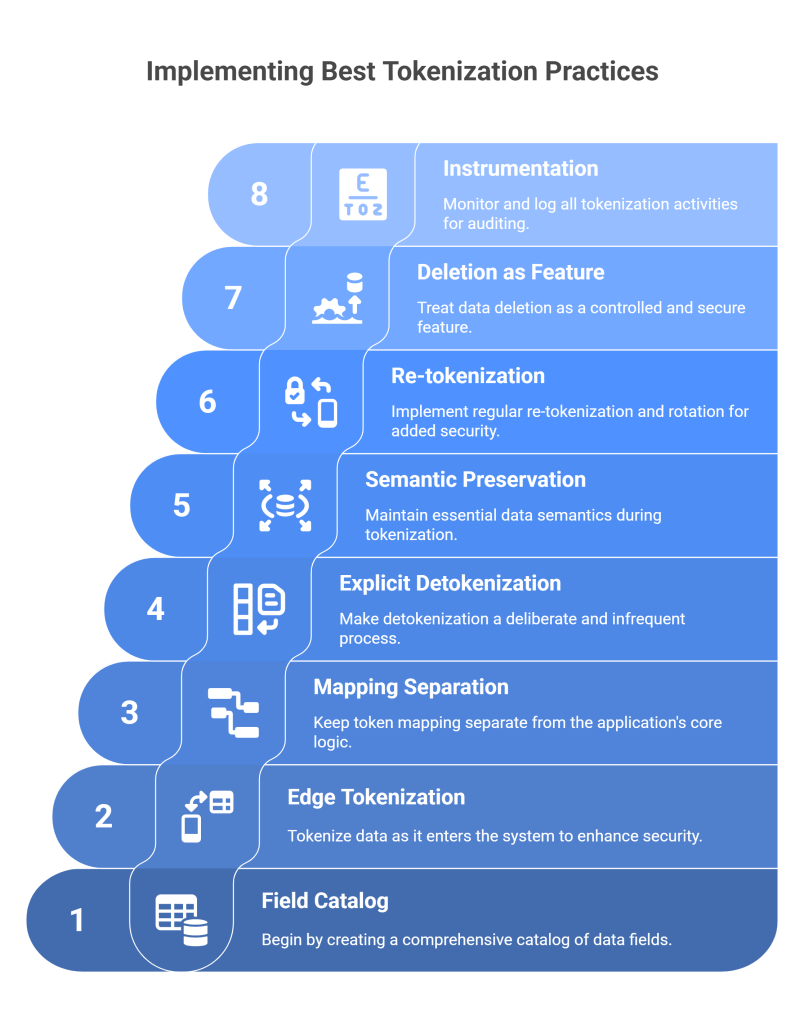
Start with a field catalog, not a tool
List fields that carry risk: emails, phones, national IDs, card numbers, bank accounts, addresses, usernames, device IDs, session cookies, OAuth tokens, API keys, health codes, payroll fields. For each, decide format, domain scope, persistence, and who can detokenize.
Tokenize at the edge of intake
Shift left. Tokenize when data enters your system: API gateways, ETL ingestion, file upload services, event producers. Store tokens, not raw values, from day one.
Keep mapping away from the app brain
The token vault lives on its own trust island with separate IAM, monitoring, and keys. Apps call it through a narrow API that enforces purpose, role, and region.
Make detokenization explicit and rare
Detokenization requires: authenticated user, approved role, documented purpose, and ideally a short-lived just-in-time grant. Log every access with a reason code and ticket link.
Preserve just enough semantics
Use format-preserving tokens when downstream validators would otherwise reject records. Keep the last 4 digits or first letter where needed for UX, not for convenience.
Bake in re-tokenization and rotation
New versions of token schemes happen. Maintain versioned tokens and a re-tokenization job that runs without downtime. Tag data with both old and new tokens during migration windows.
Treat deletion as a feature
When a user asks to be forgotten, remove raw values from the vault, expire tokens, and purge derived artifacts like embeddings and caches. Emit a deletion receipt that you can show to the user and to auditors.
Instrument everything
Dashboards should show token coverage by field, detokenization events by purpose, failures, latency, and unusual patterns (for example, a sudden spike in detokenization from a single service).
Architectures you can lift and adapt
1) Payments and PCI with omnichannel support
- Intake: API gateway runs Luhn checks and tokenizes PANs with format-preserving tokens; last 4 kept for UX.
- Apps: order systems store tokens; charge flows call a payment processor that recognizes tokens or requests detokenization via service account with least privilege.
- Data: warehouse stores tokens only; analysts use buckets for spend without raw PANs.
- AI: LLMs for support never see real PANs; retrieval excludes any chunk with token types that map to PANs.
- Proof: vault emits creation, usage, and deletion receipts tied to order IDs.
2) Healthcare notes with LLM drafting
- Intake: dictation pipeline extracts text, Protecto detects PHI and tokenizes identifiers (patient ID, phone, address), then stores only tokens in the doc store.
- Apps: clinicians view drafts; the app re-links identifiers only for authorized viewers in that care unit.
- AI: RAG index holds tokenized text; the model cannot detokenize.
- Compliance: DSAR deletes vault entries and purges embeddings; receipts attach to the patient’s privacy record.
3) Global SaaS with regional residency
- Domains: email and phone tokens scoped per region. EU and US values generate different tokens by design.
- Pipelines: ETL jobs maintain region tags; cross-region exports carry tokens not useful outside their home vault.
- LLM: retrieval filters by region and sensitivity; cross-region candidates are denied pre-search.
- Audits: quarterly export of token coverage and detokenization logs, with alerting on unusual access.
Measuring success: the metrics that matter
- Coverage: percent of high-risk fields tokenized at intake, by system and region.
- Detokenization rate: events per 1k transactions, broken down by purpose and role. Aim low.
- Latency: p50/p95 for tokenization and detokenization calls. Keep user-facing paths sub-50 ms where possible.
- Residency violations: attempted cross-region detokenizations denied by policy. Zero is the goal.
- DSAR SLA: time from request to purge across vault, warehouse, vectors, and caches.
- Incident MTTR: from detection of misuse to revocation of access and vault rotation.
These numbers move tokenization from a policy idea to an engineering practice.
A pragmatic 90-day rollout plan
Days 1–15: Map and choose
Create a field catalog and risk map. Decide domain scopes and which fields require format preservation. Pick where vaulted vs vaultless applies. Write policy-as-code stubs.
Days 16–30: Edge tokenization
Instrument API gateways, file ingestion, and event producers. Start tokenizing emails, phones, national IDs, PANs, bank accounts, device IDs, and secrets. Block records that fail sanitization.
Days 31–45: Vault and detokenization guardrails
Deploy the vault on a separate trust plane. Implement purpose/role checks, JIT grants, and receipts. Wire least-privilege service accounts.
Days 46–60: Data platforms and AI
Backfill tokenization in curated data sets. Rebuild RAG indexes from tokenized text. Add inference-time policy checks to prevent tokens from being expanded in model context.
Days 61–90: Deletion and proof
Implement DSAR flows that purge vault, warehouse, vectors, and caches in order. Generate deletion receipts. Stand up dashboards for coverage, detokenization rate, and SLA compliance. Run a red-team drill.
FAQ: engineering realities
Will tokenization break joins or analytics?
Not if you use deterministic tokens per domain and preserve required formats. Document which tokens are joinable and where.
How do we rotate without downtime?
Version tokens. Issue dual tokens during migration windows. Run background re-tokenization and switch readers when coverage crosses a threshold.
What about cost and latency
Vaults add calls. Use batched APIs, local caches with strict TTLs, and vaultless paths for low-risk fields. Measure p95 and optimize where it affects UX.
Can LLMs ever detokenize
No. Keep mappings out of the model path. If an answer needs a real value, the app re-links post-generation for authorized users only.
How Protecto accelerates Advanced Data Tokenization
If you want practical help turning plans into running code, Protecto provides a neutral privacy control plane that includes:
- Automated discovery and classification for PII, PHI, PCI, secrets, and domain-specific entities across apps, data lakes, wikis, tickets, and code.
- Tokenization and masking at ingestion with deterministic, format-preserving tokens and domain scopes for regions or tenants.
- Policy-gated detokenization with purpose, role, and region checks, just-in-time grants, and detailed receipts.
- RAG and LLM protection that builds vector indexes only from tokenized text, filters retrieval by sensitivity and region, and applies DLP to prompts and outputs.
- DSAR-grade deletion orchestration across vaults, warehouses, vectors, and caches, with proof you can hand to auditors.
- Dashboards and audit bundles showing coverage, detokenization rates, residency denials, and SLA performance.
Because Protecto is vendor-neutral, you keep your choice of clouds, warehouses, and model providers while enforcing one set of rules everywhere.

