

In most startups building or using AI, privacy often gets treated like a checkbox that legal or security will “handle later.” That mindset quietly kills deals, scares off enterprise buyers, and limits your access to the very data your models need.
Here is the truth that more founders and CTOs are embracing. Privacy makes your product easier to buy, models better to train, and business more valuable.
If you want an AI privacy advantage, start designing privacy now to turn privacy from a hurdle into a flywheel that drives growth. Here’s why it matters:
1. Privacy Builds Customer Trust
Customer data is your most valuable asset. Your users and enterprise buyers are aware of it. If your product touches sensitive information, then every conversation is a trust test.
Buyers want to know what data you collect, why you need it, and how you are protecting it. If you give them clarity, it helps to close faster. Teams that dodge end up losing customers to competitors or a longer sales cycle.
A privacy-first position differentiates you in a crowded market. Most AI tools promise smarter, faster, cheaper. Few lead with “we collect less,” “we protect more,” and “you control your data.” That message lands with both admins and end users and makes security reviews less adversarial. When you demonstrate privacy by design, the tone of the conversation shifts from suspicion to partnership.
Practical steps you can take this quarter:
- Collect only the minimum data you need. Explain why in the UI.
- Offer clear in-product controls for data retention, export, and deletion.
- Document your data flows. Show customers where their data goes and who can access it.
- Prove it with audit logs that customers can see during security reviews.
2. Privacy Enables Better AI Training
Better data makes better models, yet many teams often ignore privacy until it is too late. Enterprises wont share real data unless you can demonstrate strong security measures. Without that trust, you are stuck with thin samples, noisy exports, or purely synthetic data. Your models learn less – the results look nice in a demo and fall apart in production.
When you build privacy into your data pipeline, new doors open. You can negotiate data access that competitors cannot match because your system limits who sees raw data, applies masking and tokenization automatically, and supports purpose-based access. That is a capability that lets you train on high-quality, representative data with lower risk.
Privacy-first pipelines also reduce label noise and speed up iteration. You can share data with external experts under tighter controls. You can run experiments without duplicating raw data across environments.
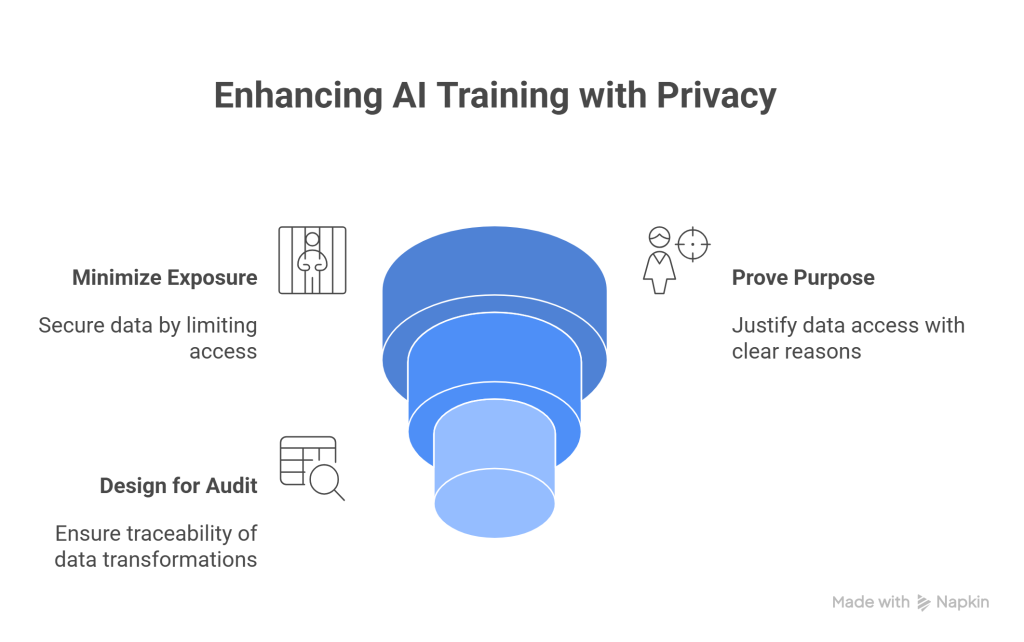
To move in this direction, focus on three pillars:
- Minimize exposure. Keep raw data in locked zones. Use masking, tokenization, and role-based de-tokenization. Do not copy raw data into notebooks and temp buckets.
- Prove purpose. Bind access to a declared purpose like training, evaluation, or support. Log it. Review it. Remove access when the purpose ends.
- Design for audit. Every transformation should be traceable. When a partner asks “who touched my data,” you should have the data ready.
3. Privacy Attracts Investors
Investors today want to know your privacy strategy as it is directly tied to regulatory exposure, sales velocity, and exit value. If you do not have a real plan, your risk profile is unclear. That means longer diligence and worse terms.
Non compliance leads to hefty penalties. Moreover, remediation work pulls engineers away from the product. This is why investors prefer companies that treat privacy as a product requirement, not as an annual policy update.
A potential buyer will comb through your architecture, data retention policies, vendor list, and incident history for unencrypted data dumps, unclear access rules, or sprawling PII in logs. On the other hand, if your platform ships with data minimization, customer controls, and clean audit logs, it increases your valuation and your options.
Early movers also gain a competitive advantage. When your competitors are navigating endless security reviews, you will be signing enterprise contracts with fewer concessions.
How to present privacy in your next investor conversation:
- Show a one-page architecture that highlights data boundaries and protections.
- Share key metrics: percentage of sensitive fields under policy, median time to fulfill deletion requests, and percentage of access requests tied to a purpose.
- Explain your roadmap for privacy at scale. Controls for new regions, automation for subject requests, training data governance.
- Bring evidence. Anonymized audit logs, policy-as-code samples, and a redacted data map.
Investors look for a leadership team that treats privacy like a lever for growth. Position your AI privacy advantage as a driver of faster sales, better models, and lower regulatory risk.
4. Privacy Makes Scaling Possible
Startups often postpone privacy work because they want to scale first. Ironically, the lack of privacy is what stops them from scaling. Closing enterprise deals raises security questionnaires, vendor assessments, and sometimes on-site audits. Unless you demonstrate controls, those deals stall.
Regulatory requirements are also expanding to broaden definitions of personal data, increase reporting requirements, and raise penalties. Building privacy retroactively across a large codebase means unwinding data sprawl, rewriting pipelines, and rebuilding trust after incidents.
The cost difference is real. Building privacy early is cheap compared with retrofitting. You add a few capabilities to your architecture, enforce data minimization, add governance into workflows. This work compounds like infrastructure. It makes every new feature easier to ship because the guardrails are already in place.
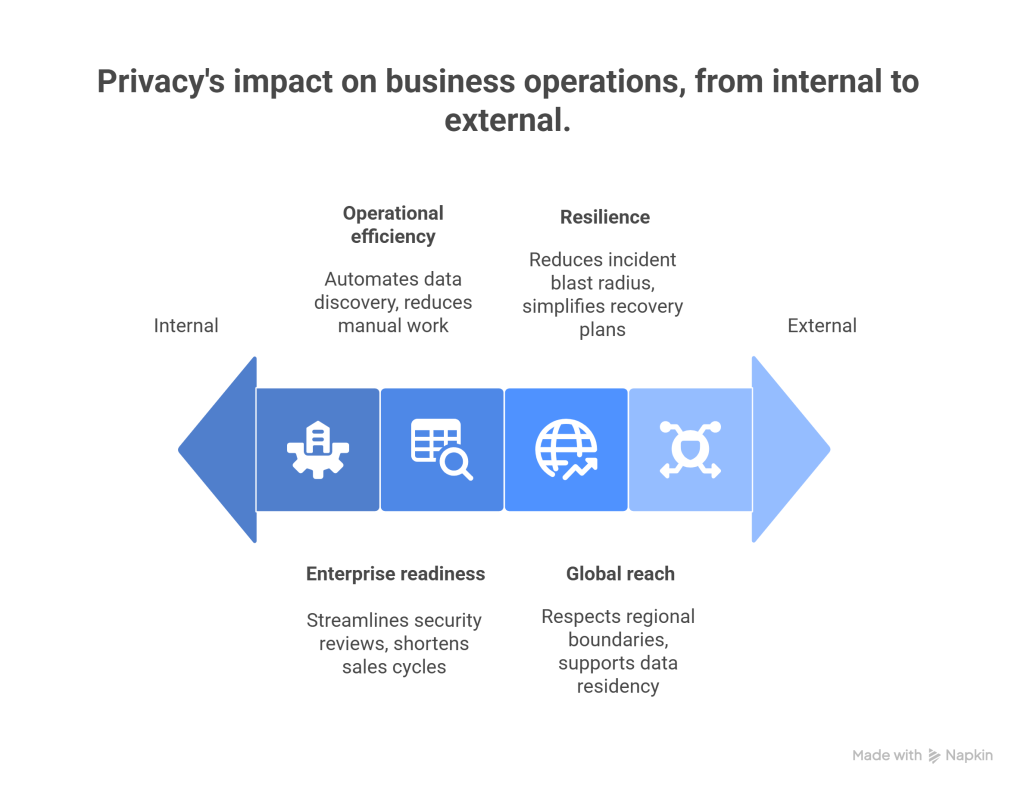
Here is a practical view of what “privacy makes scaling possible” looks like:
- Enterprise readiness. Role-based access, purpose binding, audit logs, and customer-visible controls let security reviews pass faster. Sales cycles shorten. Expansion becomes repeatable.
- Operational efficiency. Automated data discovery and retention policies reduce manual work. Engineers spend less time hunting down sensitive fields and more time building features.
- Global reach. When your architecture respects regional boundaries and supports data residency, you can sell in more markets with fewer product changes.
- Resilience. Clear boundaries and minimal data copies reduce the blast radius of incidents. Recovery plans are simpler. Incident response is faster.
Treat privacy like scalability for your go-to-market. You would not push a service to millions of users without observability and autoscaling. Apply the same thinking to data protection. Bake in the basics, measure the right things, and iterate.
A quick checklist to bake privacy in training pipelines
If you want to implement quickly, use this lightweight checklist:
- Classify sensitive data across your systems. start with customer identifiers, payment info, health or financial details, and user-generated content.
- Limit collection at the source. Avoid capturing fields you do not need for the product to work.
- Segment data by purpose and region. Keep raw data in locked zones. replicate only what is required.
- Add in-product controls for deletion and export. Make it easy for customers to self-serve.
- Adopt policy as code. Version of your rules. Test them in CI. Make privacy changes as safe as feature changes.
Scaling is not just servers and hires. It is also the trust you can extend as you grow. A privacy competitive advantage in AI is the difference between crawling through enterprise sales and running.
How Protecto helps you build privacy into AI workflows
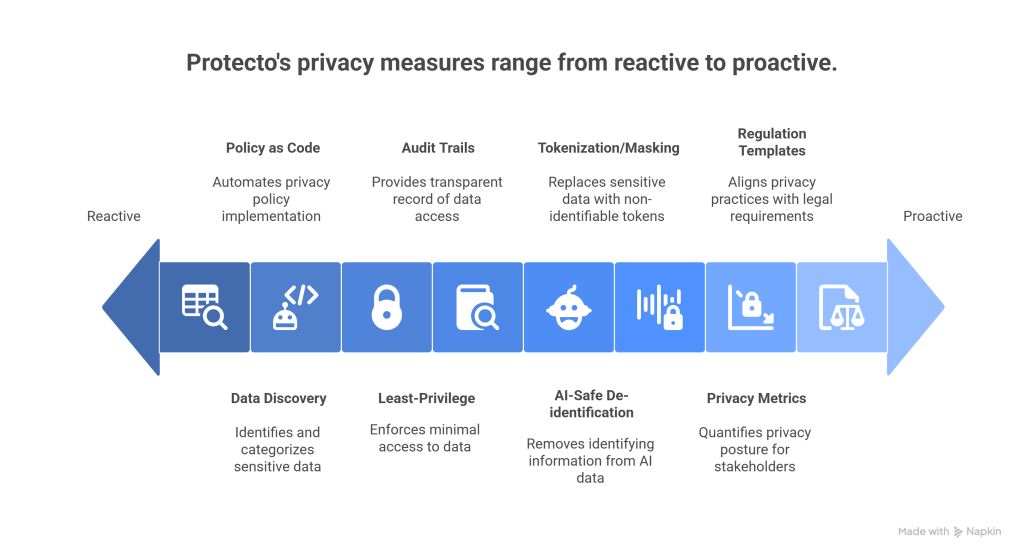
- Data discovery and mapping. Automatically inventories PII, PHI, payment data, and user content across clouds, SaaS, data lakes, and logs. Generates a living data map you can show in security reviews.
- Policy as code. Define what data you collect, where it can live, who can access it, and for what purpose. Versioned policies with CI checks make privacy changes safe and auditable.
- Least-privilege enforcement. Attribute-based access control and purpose binding at detokenization time. Every reveal requires a reason and gets logged.
- Audit trails customers can see. Immutable logs and shareable reports that answer “who accessed what and why.”
- AI-safe de-identification. NLP detection of PII/PHI in text, images, and transcripts. Contextual redaction and reversible tokens for fields you must link later.
- Tokenization and masking pipelines. Stream processors and SDKs that transform data on ingestion. Keep raw data in locked zones and move only protected versions to labeling and model buckets.
- Investor-ready privacy metrics. Coverage of sensitive fields, time to fulfill deletion/export, percentage of access bound to purpose, and PII copies over time. One dashboard for board and diligence.
- Regulation-aligned templates. Prebuilt policies and reports mapped to GDPR, HIPAA, CCPA, PCI. Faster answers in diligence questionnaires.
elementor-template id=”15760″

