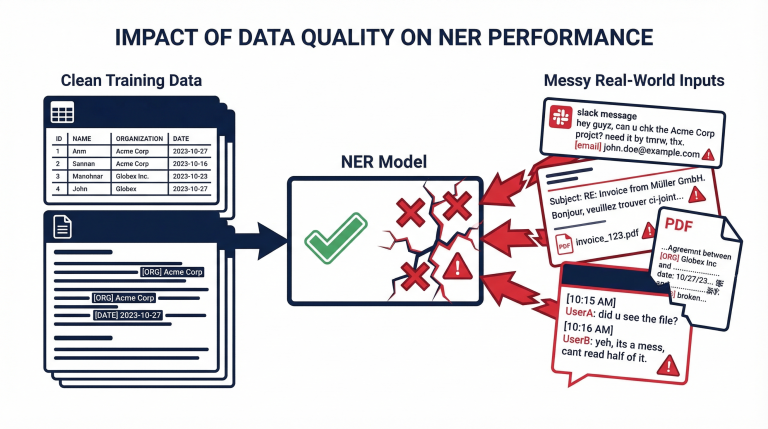
Identifying and redacting personally identifiable information (PII) is a critical need for enterprises handling sensitive data. Over 1000 NLP models and tools claim to solve this problem, but an infinite number of options opens a paradox of choice.
We compiled this comprehensive comparison of 10 notable PII detection solutions, including their features, use cases, pros/cons, and reported success rates. The goal is to help you choose the right tool for workflows like compliance, data anonymization, or content moderation.
1. ab-ai/pii_model (BERT-Based PII Entity Extractor)
The ab-ai/pii_model is a fine-tuned BERT-base model specifically trained to tag PII entities in text. It recognizes a broad array of entity types like names, addresses, financial details, credentials, birth dates, account numbers, credit card info, SSNs, URLs, emails, and even passwords and PINs. This makes it a general-purpose PII extractor useful in many domains.
Capabilities/ Use Cases: Performs token-level NER to identify PII spans. Its high accuracy (self-reported F1 around 96%) on custom dataset and detects dozens of PII categories, covering most common sensitive fields. Suitable for data preprocessing pipelines where raw text needs anonymization, it simplifies compliance workflows by automatically masking PII before sharing data into analytics.
| Pros | Cons |
|
|
PII Detection: The developers report ~96% F1-score and >99% token-level accuracy on their test data, which suggests excellent success rates in controlled evaluations and depends on how closely data matches the training distribution.
2. Roblox PII Classifier (PII v1.1)
Roblox’s PII Classifier is a recently open-sourced AI model originally developed for moderating chat on the Roblox platform. Unlike token-level NER, it performs multi-label classification to detect when a user is asking for or giving PII. It leverages context beyond individual tokens to catch subtle or obfuscated attempts to share PII.
Features/ Use Cases: Rather than labeling specific words, Roblox classifies text into two categories: PRIVACY_ASKING_FOR_PII and PRIVACY_GIVING_PII, allowing it to filter based on context. For example, it can flag messages like “DM me your number on Insta” even if no explicit phone number appears.
It considers conversation context and recognizes adversarial lingo (e.g. users saying “five” as “5ive” or using code-words) and supports multiple languages. It’s also useful in audit logs to find cases of policy violations.
| Pros | Cons |
|
|
Success Rates: Roblox’s focus was maximizing recall (catch all violations) – their report says it detects 98% of potential PII disclosure instances in English chat. On an internal eval set it scored 94.3% F1 versus <30% for various Llama-based models and 13.9% for a Piiranha NER tool. If you need a contextual PII filter (specific to user communications) this model is impressive. However, those simply needing to extract obvious PII tokens from documents might prefer a more traditional NER approach.
3. HydroX AI PII Masker
The PII Masker by HydroX AI is an open-source tool that combines advanced NER with out-of-the-box data masking capabilities. It uses a fine-tuned DeBERTa-v3 Transformer to detect PII and supports sequences up to 1024 tokens.
Uniquely, PII Masker directly produces masked output: it replaces detected entities with placeholders (e.g., “John Doe lives at 1234 Elm St.” → “[NAME] lives at [ADDRESS]”) and also returns a structured dictionary of the found entities. This makes it very convenient for anonymizing text on the fly.
Features/ Use Cases: HydroX’s model is fine-tuned specifically for high precision, multiple PII types and minimize false positives. It provides a simple Python API for integration and is designed to scale (supports GPU acceleration and 4096-token Longformer-based model).
PII Masker is useful for automated data anonymization pipelines. Organizations can plug it into ETL processes to redact PII before indexing documents in a search system or feeding data to generative AI models. Healthcare and finance industries can de-identify records for analytics and detect or replace sensitive entities with placeholders.
| Pros | Cons |
|
|
Reported Success: In demos and user feedback, PII Masker demonstrates high precision detection. It reduces false positives significantly versus some rule-based approaches; a quote from MarkTechPost noted “PII Masker’s performance [indicates] a significant reduction in false positives compared to other PII detection tools”. Users note fewer needless redactions and more trustworthy masking.
4. OpenPipe PII-Redact (Generative Redaction Models)
OpenPipe’s PII-Redact models use a fine-tuned generative language model to rewrite text and remove PII. Instead of tagging entities, these models are given raw text and produce an output where PII is masked or replaced. The LLM acts as a smart text anonymizer, learning to output “[REDACTED]” or similar tokens in place of sensitive info.
Capabilities/ Use Cases: End-to-end redaction via text generation. Removes or obfuscates text containing PII across unstructured text with complex grammar or formatting. It is useful for plug-and-play redaction components.
You can deploy it as a microservice: send in free-form text and get back a sanitized version like preparing a dataset of customer interactions by removing names and contact info without manually defining regexes.
| Pros | Cons |
|
|
Effectiveness: User feedback suggests they perform well on typical PII and have become a popular solution. Users also noted that for LLM-based PII redaction, while LLMs might miss some tokens, a carefully fine-tuned model (like OpenPipe’s) can achieve high recall for common entity types, with the benefit of simplifying deployment.
5. GLiNER for PII
GLiNER (Generalist Lightweight Named Entity Recognizer) is a family of models that detects virtually any entity type – including 60+ categories of custom PII types by specifying the labels at runtime. GLiNER’s zero-shot capability: you can provide a list of entity labels you care about (e.g., [“first name”, “last name”, “credit card number”, “SSN”]), and the model will find those in text without needing to retrain.
Core Features: GLiNER uses a prompt-style input to identify spans; it isn’t limited to a fixed set of tags. For PII, the fine-tuned versions (like Knowledgator/Wordcab and Nvidia) come with predefined catalogues of sensitive entities (60+ types).
Its zero-shot nature is useful for enterprises that might define custom data types. It’s used in privacy compliance tools to automatically label data for GDPR/CCPA and in pipelines where you might need to mask or remove PII across many categories before analytics.
| Pros | Cons |
|
|
Performance: The fine-tuned GLiNER PII models show strong performance across the board. Tests on a multi-domain PII dataset showed GLiNER-base topping the F1 charts at ~81%, whereas a standard spaCy or regex approach would typically be much lower and flexible. GLiNER’s recall is impressive – it catches ID numbers and dates that some generic NER models miss, thanks to its training on synthetic data. In summary, it is highly versatile and fairly efficient.
Challenges with Hugging Face models
1. Deployment: Scale, Latency, and Infrastructure Cost
- Most models like ab-ai/pii_model, DeBERTa PII, and GLiNER require custom setup, GPU/CPU tuning, and manual orchestration.
- Frameworks like Microsoft Presidio need containerization, service orchestration (Analyzer + Anonymizer), and tuning regex + ML combo—resulting in DevOps overhead.
- OpenPipe and LLM-based redaction tools are computationally heavy and less suitable for real-time or batch-scale usage without significant GPU infra.
- Tools like flair and Minibase are faster but often sacrifice deep coverage and accuracy.
How Protecto Solves This:
- Offers a fully managed SaaS or on-prem deployment with enterprise-grade scalability.
- Optimized pipelines can process millions of records with low latency—Protecto’s anonymization is tailored for real-time streaming (Kafka, Snowflake) as well as batch jobs (S3, BigQuery).
- Built-in connectors reduce engineering lift—enterprises don’t need to wrap multiple models or build orchestration layers.
2. Data Coverage: PII Types, Multilingual Support, and Context Understanding
- Most NER models are English-only (e.g. flair, DeBERTa, GLiNER in base form).
- Regex-driven frameworks like Presidio can’t detect implicit identifiers (e.g., “the patient in Room 11 with the rare condition”) or coded language in chat.
- Narrow-scope models often miss domain-specific identifiers like internal employee IDs, patient metadata, or platform-specific handles.
- Context classifiers (like Roblox PII) work well in chat but lack span-level tagging or multilingual breadth.
How Protecto Solves This:
- Protecto supports multilingual PII detection (20+ languages) with deep semantic modeling—covering European, Asian, and MENA locales.
- Goes beyond surface-level detection with context-aware signals to flag when PII is implied but not explicitly stated.
- Prebuilt and customizable dictionaries and ontologies make it adaptable across verticals: finance, healthcare, ecommerce, and SaaS.
3. False Positives/Negatives: Precision vs Recall Tradeoffs
- NER models tend to lean high recall, low precision (too many false alarms), or vice versa depending on their tuning.
- Regex-based tools flag harmless text as PII (e.g., numeric codes that match SSN patterns).
- LLM-based redactors may hallucinate, redact too much or too little, and do not provide consistency across runs.
- Lack of tuning on enterprise-specific data leads to poor generalization.
How Protecto Solves This:
- Uses a multi-layered detection engine (statistical + ML + rule-based) optimized for both high precision and recall on enterprise data.
- Allows confidence scoring + human review where needed (for regulated workflows).
- Offers smart redaction modes: replace, obfuscate, tokenize—customizable based on risk tolerance.
- Trained on enterprise-grade datasets with ongoing tuning, reducing both leakage and over-redaction.
4. Compliance and Audit: Traceability, Explainability, and Policy Enforcement
- Few tools offer audit logs or explain why something was flagged as PII.
- NER/LLM-based models lack traceability—you can’t easily verify or reverse what was redacted.
- Difficult to enforce per-field policies (e.g., “mask credit cards but retain ZIP codes”).
- No built-in support for regulations like GDPR’s right to explanation or data access review.
How Protecto Solves This:
- Every detection event is logged and explainable—including what was found, why, confidence level, and masking rule applied.
- Audit trails and traceable masking workflows support internal data governance and external compliance audits.
- Comes with policy templates for GDPR, HIPAA, PCI-DSS, etc., and lets you author field-level rules across different data sources (structured and unstructured).
- Integrates with data catalogs and governance tools for lineage and impact analysis.