

As AI steadily percolated into a growing number of use cases, adopting it has been a rollercoaster of confusion, chaos, and conundrums.
One key concern about AI adoption is the increased risk of hosting LLMs on-premises. Issues like sensitive data leakage, AI hallucinations, inability to implement access control, and data breaches lurk in the cloud where LLMs are deployed.
Does shifting the deployment module work?
In a bid to circumvent these risks, enterprises are shifting the deployment module from cloud-based to on-premises. Their reasoning? The cloud is within the scope of exploitation by malicious actors. A successful hacking attempt means they can access and compromise confidential data. So naturally, the solution is to deploy LLMs on-premises as it blocks remote access.
As a result, enterprises spend months on building a secure on-premises LLM infrastructure. However, while the “on-premises = secure” assumption works for regular data, it fails with LLMs. In fact, many of the most critical AI risks have nothing to do with where the model is hosted; everything to do with how data flows into and out of it.
Let’s break this down.
Why don’t on-premises systems prevent AI risks?
To understand why AI risks prevail even without cloud access, first understand how LLMs work.
The misconception
Enterprises often fail to understand how LLMs work. This leads to a misconception that just because it is hosted on premise, it can only access data it’s allowed to. This is a misconception; LLMs don’t function in isolation. It depends on data not just to function, but to improve continuously.
They process dynamic inputs from internal apps, agents, APIs, and employees. These inputs include sources like chat prompts, PDFs, and CRM exports, often containing sensitive data. In fact, some of the most critical AI risks have nothing to do with where the model is hosted but how data flows into and out of it.
Once data leaves your systems, a number of unprecedented risks lurk your data. Let’s break down these risks:
Risk #1: No more RBAC
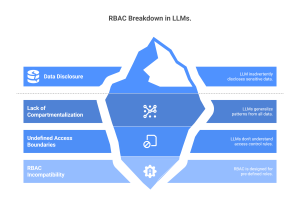
Role-based access control is one of the most widely used traditional security controls that ensures data privacy and confidentiality. While this measure works effectively across on-premises and cloud-deployed solutions, it breaks down in LLMs.
This is because RBAC is designed for systems with clear, pre-defined roles and permissions. However, data fed into LLMs are not compartmentalized. LLMs generalize patterns and relationships from this data, breaking down the “who can access what” logic.
For example, if user A with access to a health report uploads it to an LLM as part of a prompt, it stores the file in its memory. Now, if user B, who is not authorized to view the file, feeds a prompt relevant to the data in the report, it may inadvertently disclose sensitive insights from it. The model doesn’t understand access boundaries in the way an app might enforce a “read-only” database view.
Risk #2: Lost audit trail
In legacy systems, context is easy to track; you know which database a user queried, what table they accessed, and what role they had. But with AI, especially LLMs, a single prompt could reference multiple sources. The LLM processes all that to process a single prompt, without understanding the source of each piece of data or what restrictions might apply.
This is a risk, especially without enforcing security at runtime. During the actual AI interaction, the model might inadvertently surface confidential information it should have never seen.
For example, a seemingly non problematic prompt like “Summarize customer complaints and flag top issues from last quarter” could pull in PHI from one system, PII from another, and confidential product logs from a third – all without honoring any of their individual access rules.
Because the LLM doesn’t inherently recognize or respect data boundaries, context becomes fluid and unreliable. Enforcing policies before or after the interaction isn’t enough. You need to implement a guardrail that detects and governs what the model sees in real time to reduce sensitive data exposure.
Risk #3: Compliance complications
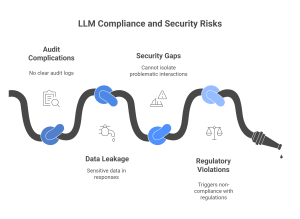
LLMs are essentially a black hole of data. Once data enters the model without any tracking mechanisms, there is no mechanism to keep track of what data is exposed, who can access it, and when. For example, if a prompt containing social security numbers or PHI isn’t logged or classified at ingestion, you cannot retrace it.
In highly regulated industries like healthcare or finance, this creates audit complications. Audit bodies need clear documents of audit and monitoring logs as evidence of compliance. Moreover, if the model’s response contains sensitive data, there is a chance of data leakage.
To add to this complexity, the inability to track data in LLM creates security gaps. If there’s a breach or misuse allegation, you can’t isolate which interactions were problematic because prompts and responses weren’t classified or monitored. While you can track if someone used ChatGPT, there is no record of what they shared or received.
To sum it up, even in an on-prem setting, the LLM can accidentally leak sensitive data, violate data minimization principles, or trigger non compliance with regulations like GDPR, HIPAA, or PCI.
How to secure data on premise LLM models?
One way to secure LLMs hosted on-premises is by using a data guardrail tool like Protecto that addresses these foundational AI risks by reshaping how enterprises manage data flow into and out of LLMs. Instead of retrofitting legacy security frameworks like RBAC into LLM environments, it brings context-aware, real-time enforcement built for how generative AI actually works.
Protecto doesn’t rely on traditional roles and permissions to control what the model can see. Instead, it dynamically classifies data at runtime and applies policy enforcement before that data reaches the LLM.
For example, when users send a prompt, Protecto inspects the data being shared. If it contains sensitive information, the system can tokenize, redact, or block it in real-time. This way, the model never learns or exposes data outside its intended scope, regardless of user roles or whether access boundaries are respected downstream.
Protecto classifies and logs every prompt and response in a structured way, making it possible to see what was shared, when, and with whom. That includes tagging whether a prompt contained PHI, PCI, or other information, and whether it was blocked, tokenized, or allowed. This helps comply with privacy laws like GDPR or HIPAA.
See Protecto’s ability in live. Book a demo now.

