

Tokenization isn’t new, but 2025 forced everyone to rethink it. You’ve got AI pipelines ingesting messy text, microservices flinging data around like confetti, and regulators asking for deletion receipts like they’re Starbucks orders.
Most companies slap together a regex mask and call it “privacy.” Spoiler: it isn’t. Real data protection often hinges on choosing the right type of tokenization for the job. That’s the part people skip, and it’s exactly where things break later.
Let’s walk through the major tokenization methods and how they actually show up in real systems.
1. Vaulted Tokenization
Vaulted tokenization is the classic model. You replace a sensitive value with a token. The original is stored in a secure “vault,” and only authorized services can detokenize it.
How it works
- Value goes in
- Vault generates a token and stores the mapping
- Token goes everywhere else
- Detokenization allowed only for roles and purposes you’ve approved
Pros
- Great for compliance (PCI, HIPAA, DPDP, GDPR)
- Easy to revoke or delete because mappings live centrally
- Strong auditability
Cons
- Vault adds latency and becomes a dependency
- Not ideal for very high-scale analytics workloads
Best use cases
- Payment cards
- Healthcare identifiers
- ID verification workflows
- Any workflow where you absolutely must be able to “undo” the tokenization
2. Vaultless Tokenization
Vaultless tokenization generates tokens using cryptographic methods rather than storing mappings. No lookup tables. No centralized vault.
How it works
- Input value is transformed deterministically
- Output token can be consistently recreated
- No reverse lookup table required
Pros
- Extremely scalable
- No single centralized dependency
- Great for event streams and high-volume ingestion
Cons
- Harder to revoke or delete
- You must plan for versioning and domain scoping
- If someone compromises the algorithm and keys… well, you know
Best use cases
- Streaming ingestion (Kafka, Kinesis)
- Behavioral analytics
- Large-scale segmentation workloads
3. Deterministic Tokenization
Deterministic tokenization always returns the same token for the same input value. This makes joins, deduplication, and identity stitching possible.
How it works
- Input “ashley@example.com” → Token A
- Next time → still Token A

Pros
- Enables analytics
- Joins across datasets just work
- Perfect for customer 360, churn modeling, and fraud scoring
Cons
- If not scope-bound, can enable unwanted correlation
- Must carefully isolate domains (EU vs US, product A vs product B)
Best use cases
- Customer behavior modeling
- Identity resolution
- Multi-table joins in a data warehouse
- Tokenized AI training sets
4. Non-Deterministic Tokenization
Non-deterministic tokenization outputs a different token every time, even for the same input.
How it works
- “mary.smith@example.com” → Token X
- Later → Token Y
Pros
- Amazing for privacy and unlinkability
- Hard to correlate tokens across datasets
- Useful when you don’t want downstream teams over-linking data
Cons
- Kills joins
- Makes analytics harder
- Must maintain mapping somewhere for reversibility
Best use cases
- Sharing datasets externally
- Security-sensitive environments
- Temporary or session-level anonymization
Protecto angle
Protecto uses non-deterministic tokens for external sharing or tight-privacy pipelines, while using deterministic tokens internally where needed.
5. Format-Preserving Tokenization
Some downstream systems refuse to work unless data “looks” right. Enter format-preserving tokens: values that behave and validate like real data.
How it works
- Token matches pattern of original field
- Phone number remains +1-xxx-xxx-xxxx
- Email remains @domain.com
- PAN obeys Luhn check (if required)
Pros
- No breaking downstream validators
- Great for legacy systems
- Smooth migration with zero schema changes
Cons
- Higher implementation complexity
- Must ensure tokens never collide with real data
- Still need vault or a deterministic scheme
Best use cases
- Payments
- Telecom systems
- Legacy apps with brittle validation logic
- Any system where schemas are painful to update
Protecto angle
Protecto generates format-preserving tokens for structured fields, making old systems cooperate without exposing sensitive data.
6. Reversible vs. Non-Reversible Tokenization
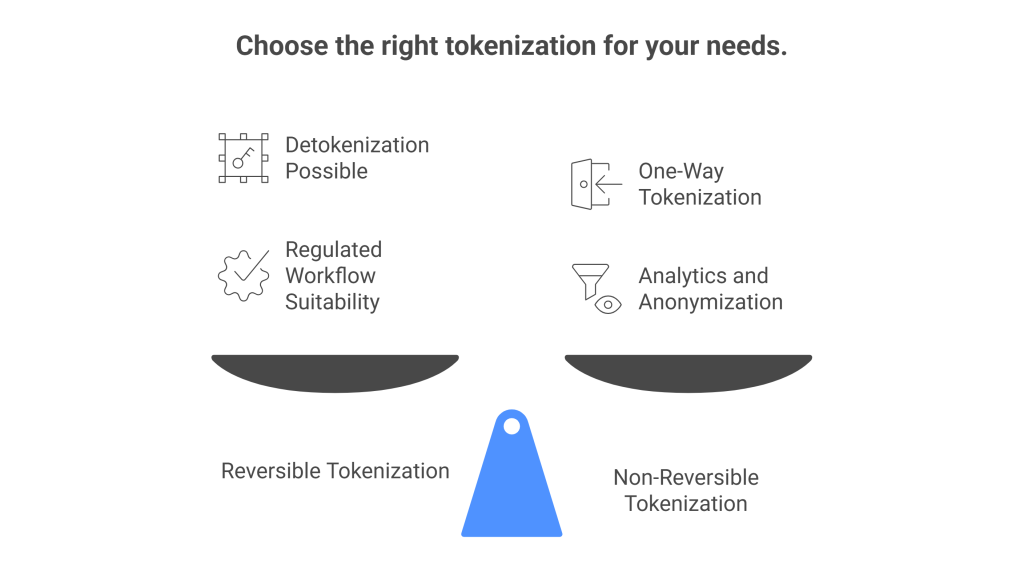
Reversible
- You can detokenize when needed
- Works for regulated workflows
- Backed by a strong vault + purpose-based control
Non-reversible
- One-way tokenization
- Impossible to recover original value
- Great for analytics and anonymization
Most companies mix both: reversible for customer operations, non-reversible for analytics or sharing.
Putting the pieces together: which type should you use?
Here’s the cheat sheet everyone wishes existed:
| Use Case | Recommended Token Types |
| Payments (PCI) | Vaulted + format-preserving |
| Healthcare (PHI) | Vaulted + deterministic |
| Global SaaS (multi-region) | Deterministic per-region domains |
| High-scale events | Vaultless + deterministic |
| AI/RAG data ingestion | Deterministic + non-reversible for embeddings |
| External data sharing | Non-deterministic + non-reversible |
| Customer analytics | Deterministic + domain-scoped |
| Auditable workflows | Vaulted + reversible |
How Protecto simplifies the entire tokenization lifecycle
If you don’t feel like stitching together your own detection, vaulting, token generation, LLM filters, retrieval rules, and deletion logic, Protecto gives you one control plane:
- Automated discovery of PII/PHI/PCI across text, files, logs, tickets, and data lakes
- Deterministic, non-deterministic, reversible, and non-reversible tokenization
- Format-preserving generation for payments and legacy systems
- Domain-scoped tokens for residency and multi-tenant architecture
- Policy-based detokenization with short-lived, just-in-time grants
- Ingestion pipelines that tokenize before chunking or embedding
- RAG filters that hide sensitive tokens
- Deletion orchestration with receipts for audits
Protecto keeps data safe, keeps models clean, and keeps you sane.
Tokenization isn’t one thing — it’s a toolbox
There’s no “one type of tokenization to rule them all.” The smartest organizations pick the right method for each workflow. Vaulted for compliance. Deterministic for analytics. Non-deterministic for sharing. Format-preserving for legacy.
And if you want all of it—without duct taping ten libraries and praying nothing breaks—Protecto gives you the whole thing in one place.
If you want, I can turn this into a downloadable guide, or produce a companion blog comparing tokenization vs hashing vs encryption.

