

LLMs, agents and retrieval‑augmented models are increasingly being adopted for product analytics, customer support and decision‑making workflows. With that scale comes exposure: AI privacy and security incidents involving customer PII are more common than ever and becoming a compliance issue.
Let’s look at the statistics:
- 13% of organizations reported breaches of ai models or applications, according to IBM’s AI oversight report.
- About 77% of employees share sensitive company data through AI tools like ChatGPT, increasing security and compliance risks.
These underscore the importance of robust guardrails and why relying on privacy tools with mediocre recall is a gamble.
Why Low Recall Is a Compliance Risk
Recall measures the percentage of true PII entities your model actually identifies. If the recall rate is low, it is probably because the tool failed to detect every sensitive entity. Also known as false negatives, it impacts compliance and security in multiple ways.
Missed identifiers leak into downstream analytics, logs, embeddings or responses, putting you out of alignment with regulations and contractual commitments.
For example, if the content reads “call me at 838 374 8377”, most privacy tools may fail to identify the phone number as PII due to the irregular or unstructured formatting. Moreover, it is lacking critical context like “phone” or “number”, which hints the tool towards possible sensitive data.
If unauthorized users gain access, it creates a number of security vulnerabilities. Moreover, if your data is liable to regulations like HIPAA, GDPR, or PCI DSS, legal issues and hefty penalties await your business.
Evidence from recent evaluations shows how often general or open‑source solutions miss the mark:
Low recall in popular tools
Microsoft’s open‑source Presidio scored only 0.39 recall on a curated PII detection benchmark. That means more than half of sensitive tokens were not detected, even though precision was high.
Domain‑specific blind spots
LLM‑based redaction tools like OpenPipe PII‑Redact and GLiNER achieve strong performance on generic text (macro‑F1 scores of 0.62–0.98) but miss over 50 % of clinical PHI; their F1 scores drop to 0.41–0.42 on medical text. In healthcare or finance, that’s unacceptable.
General‑purpose solutions leave large gaps
Independent benchmarking found that general market PII detection services miss 13.8 % – 46.5 % of PII entities, whereas specialized models miss only 0.2 %–7 %. Every missed identifier is a potential breach, regulatory violation or lawsuit.
The Cost of Missed PII
Data privacy laws don’t forgive “honest mistakes.” Under GDPR the cumulative fines have surpassed €5.88 billion, while HIPAA enforcement actions have resulted in penalties ranging from tens of thousands to millions of dollars. The upcoming EU AI Act, effective 2 August 2025, allows regulators to fine companies up to €35 million or 7 % of global turnover for AI‑related infractions.
With the rapid expansion of GenAI and RAG workflows, you have thousands of new touchpoints where data can leak. Incidents often stem from misconfigured storage buckets, leaky retrieval connectors or employees pasting sensitive tickets into public LLMs. Unless your detection engine operates at near‑perfect recall across all those surfaces, you’re betting your compliance.
Recall vs. Precision: Getting the Metric Right
Many teams fixate on precision because false positives add noise. Yet precision only tells you how many flagged tokens are truly sensitive; it says nothing about the sensitive data you missed. Recall is the critical metric because missing even 15 % of PII entities can expose organisations to regulatory fines, data breaches and loss of customer trust.
Purpose‑built approaches recognise this and aim to minimise false negatives. You can always lower the threshold to reduce false positives or add human review for edge cases, but there’s no post‑processing step that recovers data you never detected.
Sample performance comparison
Below is a simplified comparison of different approaches based on publicly reported results. (Each recall value is approximate and summarises multiple sources.)
| Approach | Approx. Recall | Missed PII | Evidence |
| General open‑source models | ~0.39–0.85 | Miss 15–46 % of PII | Presidio recall 0.39; general market solutions miss 13.8–46.5 % |
| Domain‑agnostic LLM redaction (e.g., GLiNER/OpenPipe) | 0.41–0.62 on complex domains | Miss >50 % of clinical PHI | F1 scores drop to 0.41–0.42 on clinical datasets |
| Specialised PII models | ≈0.93–0.99 | Miss <7 % of PII | Purpose‑built solutions miss only 0.2–7 % |
| Protecto DeepSight | ≈0.99 recall (99 %) | Minimal misses; ~96 % precision | Financial services case study reported 99 % recall and 96 % precision |
These figures illustrate why “pretty good” isn’t good enough. Only near‑100 % recall can reliably prevent sensitive tokens from falling through the cracks.
The DeepSight Advantage: High Recall Without the Noise
Protecto’s DeepSight is a privacy‑by‑design platform built to deliver that level of assurance. A financial institution using DeepSight across multilingual Arabic–English prompts achieved 99 % recall while still maintaining 96 % precision and 85 % semantic consistency.
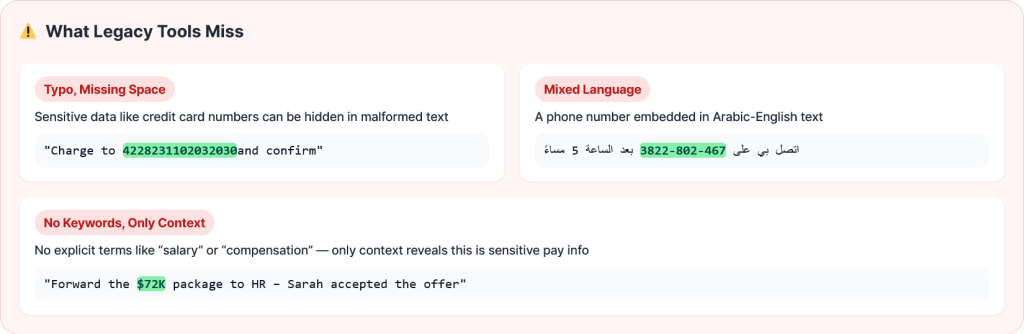
Such recall means the system finds virtually every phone number, social security number or medical term across all data formats – structured tables, PDFs, nested JSON and free‑form text – without drowning users in false positives. DeepSight accomplishes this through:
- Contextual natural language understanding – Instead of brittle regex, DeepSight’s transformer‑based models consider the relationship between words. They distinguish “John scored 555 points” from “Call John at 555‑1234,” reducing false alarms.
- Format‑agnostic, multilingual scanning – The engine scans unstructured docs, logs and nested objects and is trained across multiple languages and formats. It adapts to typos, transliteration or unusual spacing.
- Mixed data format scanning – Scans for sensitive data across mixed formats like log documents, embedded tables, or nested JSONs. Traditional tools don’t grasp semantic relationships in free text and miss subtle references.
- Understanding and scanning typos – Goes beyond rigid pattern matching, regular expressions, and static dictionaries. This helps when enterprise use cases involve typos, incorrect spelling, or character substitutions.
- Custom entity support & sensitivity settings – Organisations can define proprietary identifiers (employee IDs, health insurance numbers) and tune detection thresholds to balance recall and precision.
- Real‑time and batch modes with logging – DeepSight supports streaming detection for chat or voice and batch processing for data lakes, generating detailed audit logs for compliance reporting.
Combined, these features enable near‑perfect recall without sacrificing data utility. In industries like banking or healthcare, that translates to fewer breaches, faster incident response and demonstrable compliance.
Don’t Bet Your Compliance Budget on Chance
The cost of missing PII grows every year. Regulatory fines are escalating, AI privacy incidents are surging, and your data is spreading across more unstructured channels than ever before. Yet many businesses still rely on tools that miss 15–50 % of sensitive data.

Purpose‑built solutions like DeepSight prove that this level of performance is possible, delivering 99 % recall and 96 % precision in real‑world deployments.
AI promises efficiency and innovation, but only if we build guardrails that respect privacy and compliance. Stop leaving data protection to chance. Demand near‑perfect recall and choose tools that deliver it.
