
From Model-Centric Systems to Intelligent Outcomes
In the evolving landscape of data protection and compliance, data classification is the bedrock of safe AI workflows. Yet legacy approaches rely on singular models that are fixed, rigid, and limited in context. Our agentic data classification approach reshapes this paradigm by not relying on any single model. Instead, we orchestrate a dynamic, intelligent layer that automatically selects the right model for the job. This is a fundamental shift in how classification systems are designed, deployed, and scaled.
The Problem with Legacy Data Classification
Traditional classification tools depend on single models, whether rule-based systems or ML models trained for specific data types. These models often follow a one-size-fits-all approach. If a system is tuned for healthcare data, it performs poorly when applied to financial data. If it is optimized for structured data, it struggles with unstructured documents. Organizations are forced to retrain models, deploy parallel systems, or manually select a model for each workload.
This static architecture creates several limitations:
- Customers must understand and select models themselves
- Adaptation to new data types is slow and expensive
- Performance degrades outside narrow training domains, and often requires tuning and changes
- Scaling introduces operational and cost complexity
As data types evolve and AI use cases expand, this model-centric approach becomes a structural bottleneck.
Introducing Agentic Data Classification
Our approach is fundamentally different. We have built an intelligent, agentic layer that orchestrates a combination of models rather than relying on a single one. Customers no longer need to pick models, manage updates, or worry about tuning strategies. The system itself makes those decisions.
The agentic layer dynamically selects the optimal model or set of models based on context, data type, regulatory requirements, and customer-specific configurations. Model selection happens automatically and continuously, adapting in real time as conditions change.
Instead of designing systems around models, we design systems around outcomes.
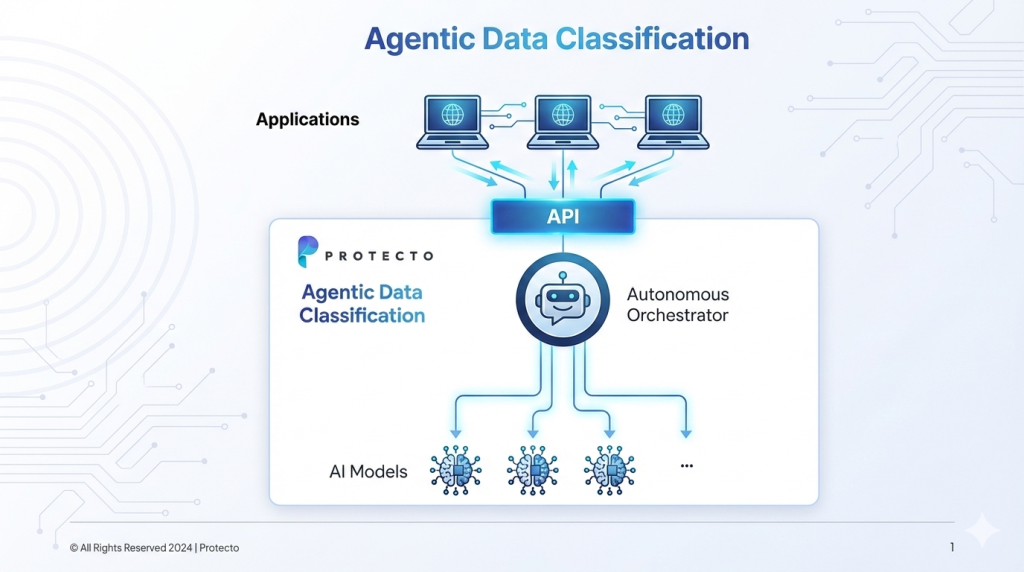
How the Autonomous Orchestrator Works
At the core of the platform is an agentic orchestration layer that fully abstracts model complexity from the customer. Integration happens once through a simple API. Everything else is handled by the classification intelligence layer.
For every classification task, the agentic layer evaluates multiple dimensions, including:
- Context: personal data, regulated data, enterprise data, industry-specific data
- Regulatory policies: healthcare, financial services, government, enterprise compliance frameworks
- Data type: structured, semi-structured, unstructured, documents, logs, streams
- Operational needs: latency sensitivity, batch vs real-time
Based on these inputs, the system routes the task to the most appropriate model or ensemble of models. One request may use a lightweight classifier for fast pattern recognition. Another may use a highly tuned deep semantic classification model. Another may use multiple models in sequence for validation and confidence scoring.
All of this happens automatically. No manual configuration. No model selection. No operational complexity for the customer.
Flexibility and Future-Proofing
This architecture creates a system that evolves without disruption.
New models can be added without changing customer integrations. Existing models can be retired without breaking workflows. Tuning strategies can evolve without code changes. Routing logic can improve continuously without redeployment.
Within the same environment, multiple models operate with different tuning parameters. Some are optimized for detecting personal data. Others for enterprise-specific data. Others for regulatory classification. Others for semantic understanding in unstructured data.
Customers are not locked into any model, vendor, or architecture. The system evolves independently of customer applications, ensuring long-term adaptability and performance improvements without migration costs.
The Hidden Complexity We Handle
Building an agentic classification system requires solving problems that legacy architectures never address:
- Model diversity management: maintaining and orchestrating multiple models across domains
- Context-aware routing: real-time decision systems for model selection
- Policy-driven intelligence: classification logic driven by governance, not just data
- Zero-code-change evolution: platform-level updates without application-level changes
This complexity is intentionally absorbed by the platform so customers do not have to manage it.
Cost and Scalability Benefits: The Right Tool for Every Job
Agentic classification is not only more intelligent but also fundamentally more efficient.
Traditional systems default to large, resource-heavy models for all tasks, even when simple classification would suffice. This creates unnecessary compute costs, higher latency, and poor scalability economics.
Our agentic system selects models based on actual task requirements. Lightweight models are used for simple classification tasks. More powerful models are used only when complexity demands them.
It is the difference between choosing a bicycle, an SUV, or a truck for a job, rather than always driving a truck for every task.
This approach delivers:
- Lower infrastructure costs
- Reduced compute consumption
- Faster response times
- Better horizontal scalability
- Sustainable long-term economics
As data volumes grow, the system scales intelligently. Lightweight models scale horizontally for high-volume workloads, while heavyweight models scale only where necessary. Organizations pay only for the intelligence they actually need.
Why Agentic Classification Wins
Static models cannot keep pace with evolving data, regulations, and AI use cases. Model-centric systems create operational friction, technical debt, and long-term rigidity.
Agentic data classification shifts the paradigm:
- From model-centric -> outcome-centric
- From static -> adaptive
- From manual -> autonomous
- From rigid -> flexible
- From costly -> efficient
Customers get better accuracy, lower cost, higher scalability, and long-term future-proofing without complexity.
Agentic data classification is not an incremental improvement. It is a structural shift in how classification systems are designed.
This is not just the next version of data classification. This is the future architecture of intelligent data protection systems.

