There’s a claim gaining traction in the market: homomorphic encryption can preserve data privacy in AI workflows. Encrypt your data, run it through a language model, and never expose a single token. Sounds bulletproof.
It isn’t.
Homomorphic encryption (HE) was built for math, not language. Applying it to LLM pipelines is like encrypting a book and asking someone to summarize it without reading a word. The problem isn’t efficiency. It’s a fundamental mismatch between what HE does and what LLMs need.
Where Homomorphic Encryption Actually Works
HE allows computation on encrypted data without decrypting it. For structured, numerical operations, it works well.
In healthcare analytics, you can compute average patient ages across hospitals or sum total claims without exposing individual records. In financial analysis, you can add population counts across regions, calculate income averages, or run risk scoring on numeric features.
In every case, the data is structured. The operations are deterministic. The computation is pure math — addition, multiplication. The system never needs to “understand” anything. It processes numbers, and that’s exactly what HE was designed for.
Why Homomorphic Encryption Fails for LLM Security
LLMs don’t operate on math. They operate on meaning. And that’s where the entire premise falls apart.
A typical LLM pipeline takes free text — emails, logs, documents, chat messages — tokenizes it into embeddings, runs attention and reasoning across those tokens, and generates new text based on context. Every step depends on semantic relationships between words.
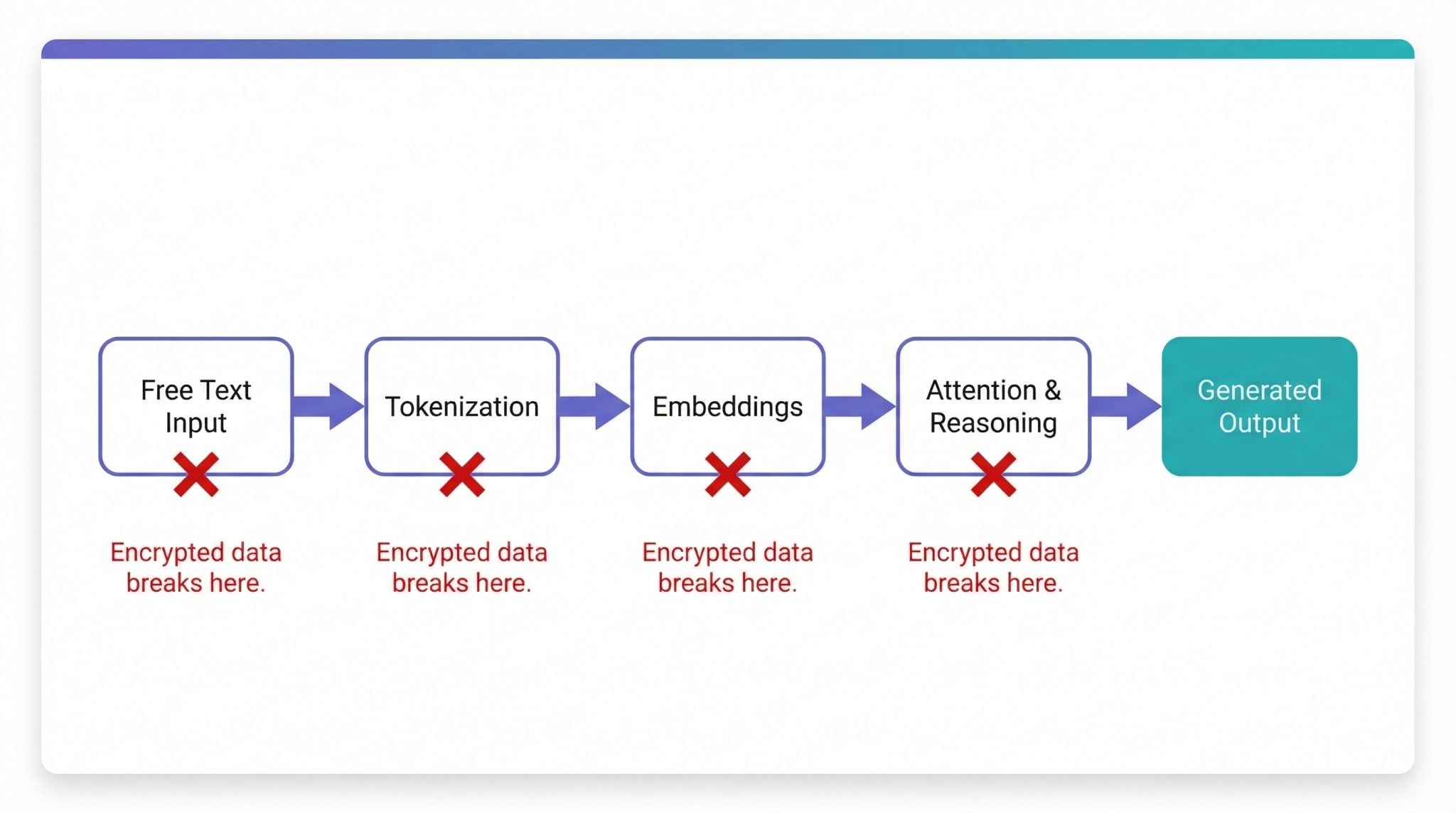
Language is not just numbers
Yes, text gets converted into tokens and vectors. But the model relies on relationships between those tokens — context, position, probability. Encryption destroys that structure. The numbers are still there, but the meaning is gone.
LLM operations go far beyond simple arithmetic
HE supports addition and multiplication, with significant constraints. LLMs require non-linear activations like GELU and softmax, attention mechanisms, normalization layers, and high-precision matrix operations at massive scale. Running these over encrypted data is computationally infeasible today, balloons latency and cost, and frequently breaks numerical stability.
Context is everything
Consider this sentence: “John transferred $5,000 to his sister Mary last Friday.”
An LLM needs to understand who John is, how Mary relates to him, what the intent behind the transfer was, and when it happened. Encrypt that input, and entity relationships vanish. Token patterns become noise. Attention can’t function. You don’t just lose visibility into the data — you lose the model’s ability to reason about it.
HE vs LLMs: A Quick Comparison
| Use Case | HE | LLM |
|---|---|---|
| Add patient ages | Works perfectly | Not needed |
| Compute averages | Works perfectly | Not needed |
| Summarize patient notes | Doesn’t work | Core strength |
| Detect fraud from narratives | Doesn’t work | Core strength |
| Answer questions from documents | Doesn’t work | Core strength |
The Core Misconception About Privacy Preserving AI
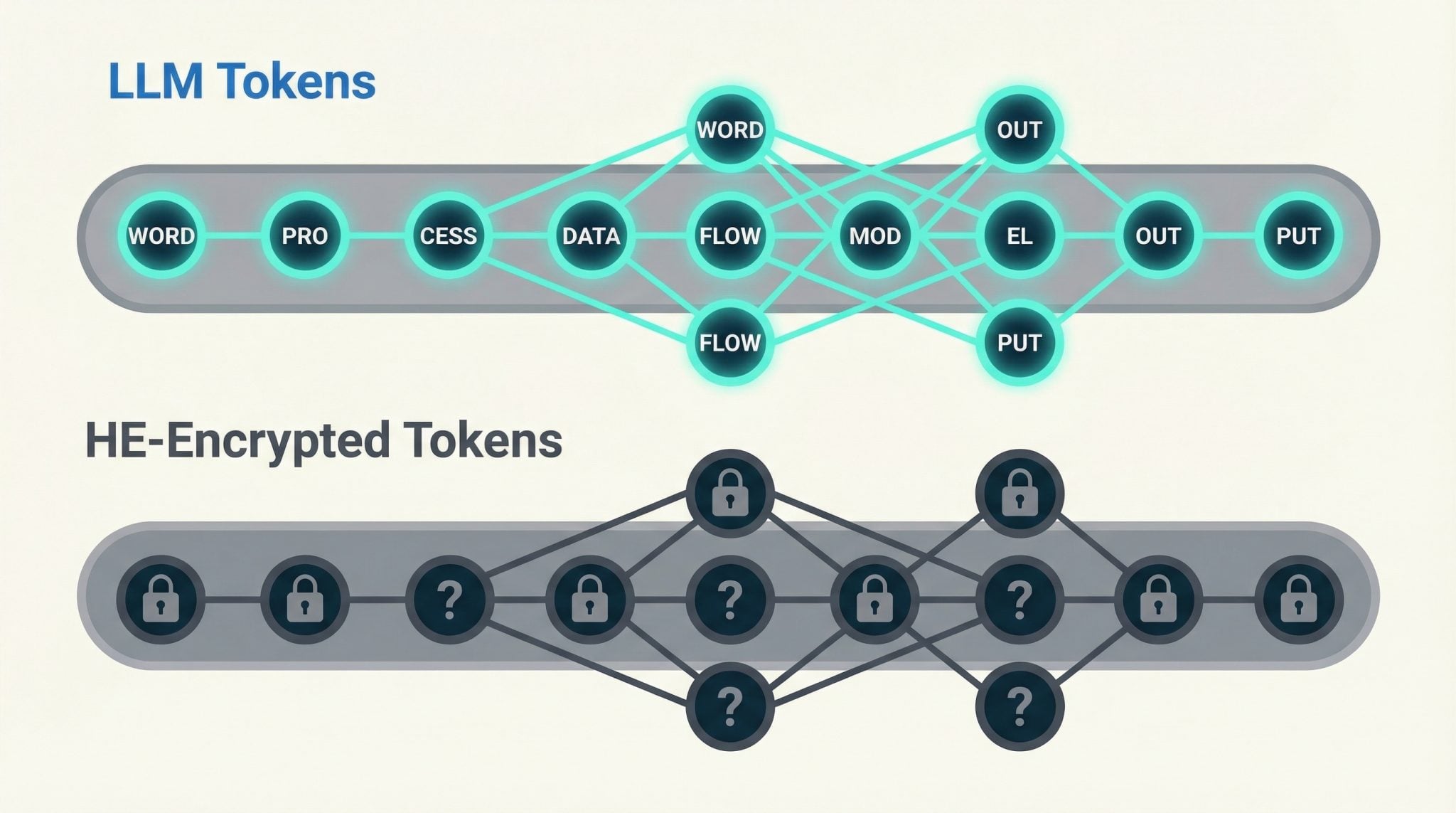
The confusion starts with a reasonable-sounding idea: “LLMs operate on tokens, which are just numbers, so encrypted numbers should work.”
That’s technically true at a surface level, but misleading. LLMs operate on tokens that encode meaning. HE turns them into numbers that hide meaning. You can’t reason over data you’ve deliberately made unreadable. That’s the contradiction at the heart of every “HE for LLMs” pitch.
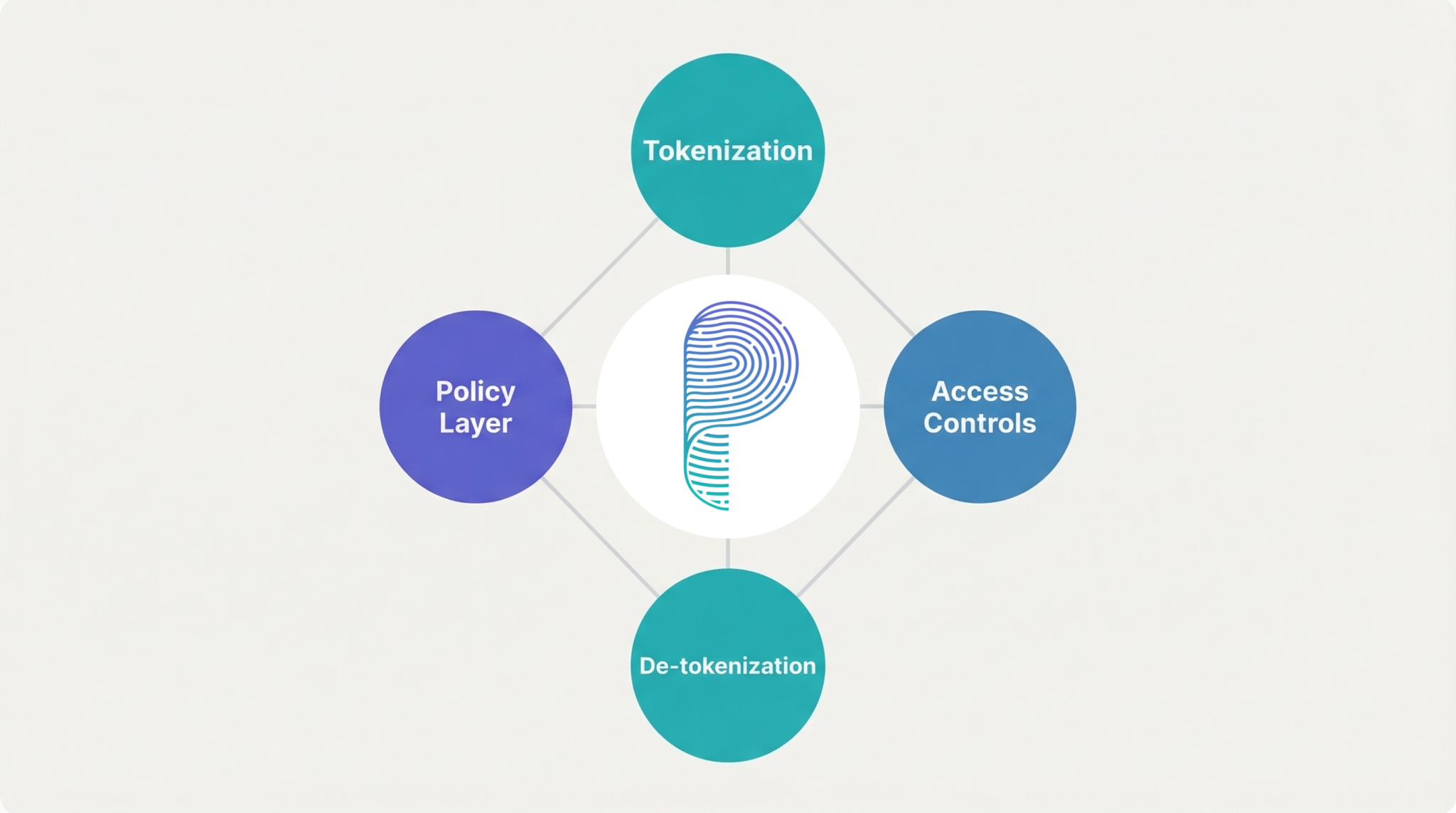
What Actually Works for Data Privacy in AI
Instead of forcing LLMs to process encrypted data, production systems use approaches that preserve both privacy and semantic integrity. Data tokenization vs encryption is the real decision enterprises face today:
- Tokenization and masking — hide sensitive entities like names and SSNs while preserving the structure the model needs to reason. Learn how AI-driven tokenization works.
- Context-aware access controls — decide at runtime what data the model should and shouldn’t see. Explore CBAC for AI systems.
- Selective de-tokenization — reveal sensitive data only when needed and only to authorized users.
- Policy enforcement in the context layer — apply LLM security rules dynamically, not as a blanket encryption layer.
These methods keep the model’s reasoning intact while giving enterprises the data privacy in AI controls they need. That’s the tradeoff HE can’t make.
Final Word
Homomorphic encryption is a genuine breakthrough for secure computation on structured data. LLMs are a breakthrough for reasoning over unstructured language. These two technologies solve different problems, and combining them doesn’t give you the best of both worlds — it gives you neither.
If someone tells you HE can protect your LLM pipeline, ask them to show you it working at production scale, on real text, with acceptable latency. That demo doesn’t exist yet for a reason.