
Most teams learn the OWASP Top 10 as a list of application security failures. Injection flaws. Broken access control. Security misconfiguration. Items to scan for, remediate, and close before the next audit or penetration test.
But data exposure rarely arrives neatly packaged as a single OWASP finding.
When sensitive data leaks, it is almost never because one category failed in isolation. It happens because several of them quietly overlap, reinforcing each other across systems that were never designed with data boundaries as the primary concern.
The OWASP Top 10 is not a catalog of data risks. It is a catalog of ways modern systems lose control. When you map those failures to how data actually moves, persists, and gets reused, a different picture emerges. One where exposure is not an anomaly, but a predictable outcome of architectural assumptions.
This is the gap many security programs fall into. They remediate vulnerabilities but never follow the thread all the way to data.
Data exposure is a systems problem, not a single mistake
Post-incident analyses tend to focus on the final failure. An endpoint that returned too much data. A permission check that wasn’t enforced. A misconfigured storage bucket that was left public.
Those details matter, but they rarely explain why the data was reachable in the first place.
Long before data is exposed, it has usually been collected more broadly than intended, retained longer than necessary, copied into multiple systems, and made accessible to identities that were never meant to see it. These decisions often feel harmless at the time. They make development easier, analytics richer, and debugging faster.
None of them appear explicitly in the OWASP Top 10. Yet almost every OWASP category accelerates these conditions when it fails.
Understanding that relationship is the difference between fixing a vulnerability and reducing actual exposure risk.
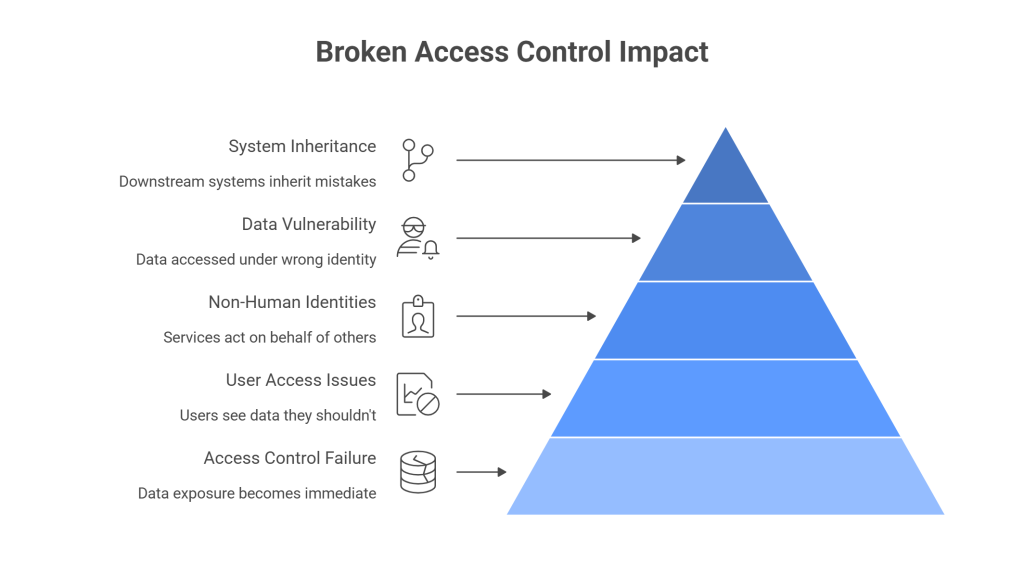
Broken Access Control is where data exposure becomes immediate
Broken Access Control consistently ranks at or near the top of the OWASP list, and for good reason. When access controls fail, data exposure stops being theoretical.
Most teams associate access control failures with users seeing data they should not. A user accessing another account. An admin-only endpoint being reachable by a regular role. These are real issues, but they represent only part of the problem.
Modern systems rely heavily on non-human identities. Services, APIs, background jobs, agents, webhooks, and third-party integrations all act on behalf of something else. When access controls fail in those contexts, the blast radius is often larger and harder to detect.
A service account intended to read masked data gains access to raw records.
An internal API token gets reused in an external workflow.
A backend endpoint returns full objects instead of filtered fields because the caller is assumed to be trusted.
In each case, the vulnerability is categorized as access control. The impact is always data. What data can be accessed, under what identity, and with which implicit assumptions.
Once access control boundaries erode, every downstream system inherits that mistake.
Injection creates unplanned data paths, not just code execution
Injection vulnerabilities are commonly framed as a way to run unauthorized commands. That framing understates their impact in data-driven systems.
In practice, injection often creates new, unplanned paths through which data can be retrieved, combined, or revealed. SQL injection is the most familiar example. A crafted input alters a query and exposes records that were never meant to be returned.
But the same pattern shows up elsewhere. Template injection, command injection, and prompt injection all allow external input to influence how a system interprets data boundaries.
In AI-enabled systems, the effect is magnified. A single injected instruction can cause a model to retrieve additional context, surface conversation history, or expose embedded documents pulled from vector stores. These systems are designed to be flexible, which makes them especially sensitive to instruction manipulation.
The OWASP category names the technique. The real risk lies in what data becomes reachable when those instructions are followed.
Insecure Design makes data exposure inevitable over time
Insecure Design is one of the most misunderstood OWASP categories. It does not point to a missing patch or a misconfigured setting. It points to an architectural decision that assumed trust where none should exist.
This is where data exposure becomes structural rather than accidental.
Examples tend to sound reasonable when they are introduced. Storing raw PII in logs temporarily for debugging. Passing full data objects between services for convenience. Letting downstream systems decide how to filter sensitive fields. Training or prompting models directly with live customer data.
None of these decisions break a specific rule on day one. They often pass reviews because they solve an immediate problem. But they create systems where a single failure elsewhere leads to large-scale exposure.
Insecure Design is not about attackers being clever. It is about systems being fragile under real-world conditions. Once data flows are overly broad, every other OWASP category becomes more dangerous.
Security Misconfiguration determines how far data spreads
Security Misconfiguration rarely causes data exposure on its own. Instead, it determines how contained or widespread the exposure becomes.
An overly permissive storage policy turns a private mistake into a public one.
A default cloud setting allows internal services to be reached externally.
A misconfigured CORS policy exposes APIs to unintended origins.
These issues often sit outside the application code. They live in infrastructure, deployment pipelines, and managed services that teams assume are already handled. Because of that, they persist longer and are harder to audit comprehensively.
When misconfiguration overlaps with insecure design or broken access control, the result is rarely subtle. Data that should have been difficult to reach becomes trivially accessible.
Identification and Authentication Failures undermine every data control
Authentication failures are usually discussed in terms of account takeover. While that risk is real, the quieter danger lies in what happens after identity is misattributed.
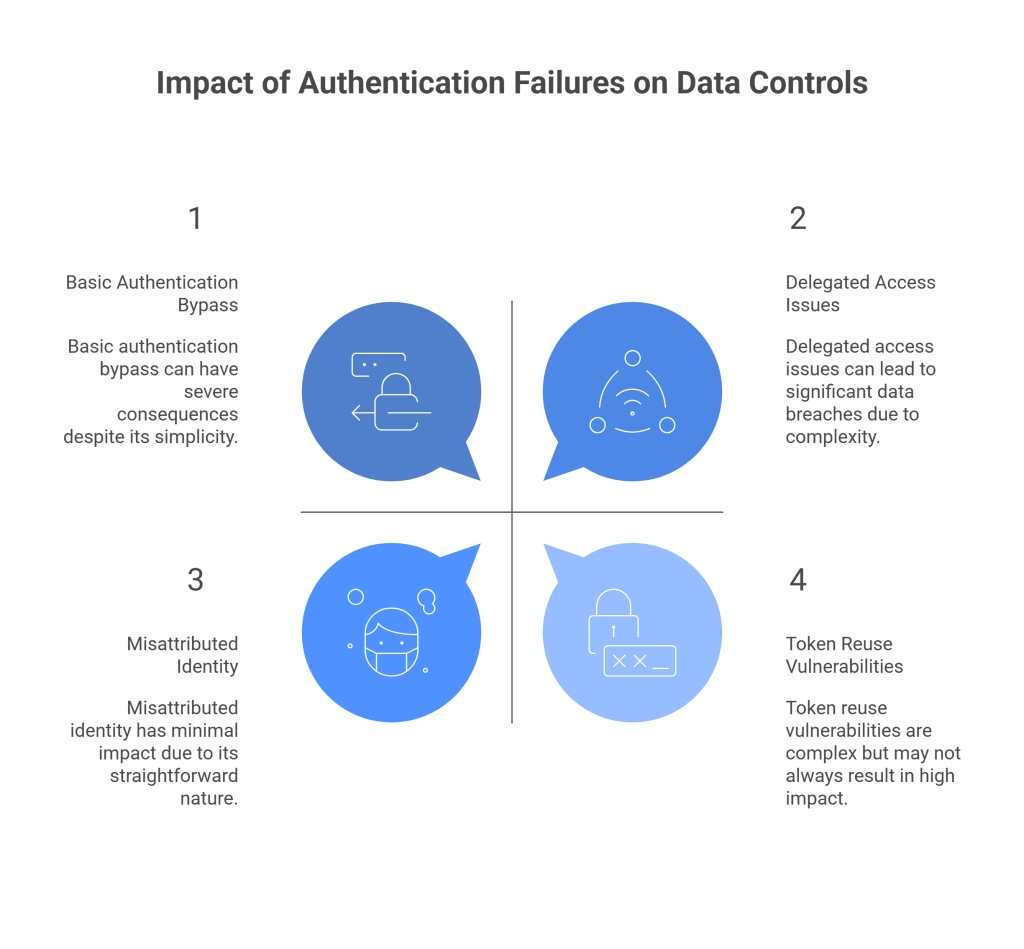
Every data control assumes identity is correct. Row-level security. Data masking. Consent enforcement. Audit logging. All of them rely on the system knowing who or what is making a request.
When authentication fails, those controls do not degrade gracefully. They fail completely.
This problem becomes more complex in systems that rely on delegated access, tokens, and agents. An agent acting on behalf of a user may inherit more privileges than intended. A token reused across contexts may bypass checks that were never designed for that scenario.
The OWASP category highlights the identity failure. The damage shows up as data being returned under false assumptions.
Vulnerable and Outdated Components leak data indirectly
Outdated components are often treated as an infrastructure hygiene issue. Patch the library. Update the dependency. Move on.
From a data perspective, their risk is often indirect. Vulnerable analytics SDKs may capture more metadata than expected. Client-side scripts may exfiltrate request payloads. Logging libraries may transmit sensitive fields to external services.
These components are trusted because they are common and widely adopted. When they fail, data leaves quietly, often without triggering traditional alerts.
The vulnerability exists in the component. The exposure happens at the edge, in the browser or across third-party networks that security teams do not fully control.
The recurring pattern across the OWASP Top 10
When you map the OWASP Top 10 to data exposure, a consistent pattern emerges. Data leaks when systems lose control over who can see what, when, and under which assumptions.
That loss of control happens when access boundaries are weak, data flows are too broad, systems trust downstream enforcement, and runtime visibility is limited.
OWASP describes how applications break. Data exposure describes what escapes when they do.
Treating these as separate concerns leads to security programs that look strong on paper but remain fragile in practice.
Why this mapping changes how teams prioritize risk
Teams that treat OWASP strictly as an application security checklist often miss the bigger picture. They fix vulnerabilities, pass scans, and still experience data incidents that feel surprising.
Teams that understand how OWASP failures translate into data exposure start asking different questions. Where does sensitive data flow when something goes wrong? What data is available by default rather than by exception. Which failures expose metadata first, and how does that compound over time.
The OWASP Top 10 is not outdated. But it is incomplete if you stop at the category level.
The real work begins when each category is traced to the data it can reveal, intentionally or otherwise. That is where vulnerability management turns into actual risk reduction.
How Protecto Bridges the Gap Between Application Failures and Data Reality

The OWASP Top 10 remains a useful lens for understanding how applications fail. But on its own, it stops short of explaining what organizations actually lose when those failures occur.
Data exposure is rarely the result of a single vulnerability. It is the cumulative outcome of design decisions, access assumptions, identity models, and data flows that were never revisited as systems grew more complex. OWASP categories describe the mechanics of failure. They do not account for how widely data is copied, how long it persists, or how many systems quietly depend on it being available by default.
Modern architectures amplify this gap. Data moves continuously between services, third parties, analytics tools, and AI systems. Once sensitive data enters those paths, every access control failure, misconfiguration, or injection flaw carries more weight. What might have been a contained issue in a simpler system becomes a cross-system exposure event.
This is why reducing risk today requires a shift in perspective. Instead of asking whether an application complies with OWASP guidance, teams need to ask what data is reachable when something inevitably breaks. Which systems hold raw data versus derived data. Which identities can reassemble sensitive information. Which failures expose metadata first, and how that metadata can be combined.
OWASP does not need to be replaced. It needs to be grounded in data reality.
When security programs connect vulnerability categories to actual data exposure paths, priorities change. Controls become less about preventing every failure and more about limiting what any single failure can reveal. Over time, that shift is what separates organizations that repeatedly react to incidents from those that quietly reduce their impact.
In the end, application security is about how systems behave when they fail. Data security is about what escapes when they do.


