

Organizations across finance, healthcare, retail, and especially AI-driven sectors are facing increasing pressure from global regulators. The rapid expansion of AI, increasing cross-border data flows, and the rise of new privacy frameworks demand more structure and accountability. Regulators increasingly expect organizations to minimize their reliance on raw data with rapid AI adoption.
In this environment, tokenization is becoming the backbone of compliant data architectures. It supports privacy-by-design, reduces the impact of breaches, and enables safe cross border data sharing without sacrificing operational or analytical capabilities.
This article explores the major regulatory shifts, the evolution of tokenization standards, and the best practices companies are adopting to stay ahead.
Why Tokenization Has Become Central to Compliance
Tokenization replaces sensitive data like names, financial identifiers, and personal health information with a non sensitive, meaningless placeholder known as tokens. These irreversible placeholders are same for each preserves format and usability. The original data is stored securely in a vault or transformed in a way that prevents unauthorized recovery.
It also enables consistent compliance across jurisdictions. With the rise of data residency laws, organizations need a way to run global operations without moving raw personal information across borders. Region-specific tokenization has emerged as one of the most effective answers.
Global Regulatory Forces Shaping Tokenization in
1. GDPR and the Push Toward Pseudonymization
The GDPR remains the gold standard for privacy regulation, and its requirements continue to expand. Regulators now expect companies to demonstrate concrete steps they have taken to minimize the presence of personal data during processing, especially in AI and analytics workflows.
Tokenization supports this expectation by enabling pseudonymization by turning personal data into a non-identifying symbol unless reconnection is intentionally allowed. This significantly reduces risk and simplifies compliance audits.
2. The EU AI Act and High-Risk AI Systems
The EU AI Act is now fully active, and it places new expectations on companies building AI products. High-risk systems, such as those used in healthcare, finance, hiring, and government, must show that they reduce unnecessary exposure to identifiable information.
Tokenization is a structural requirement here. It allows models to use relevant features of the data without retaining the identity of the individual. It also helps organizations produce transparent audit trails, which the AI Act now requires.
3. Expanding US State Privacy Laws
The patchwork of state privacy laws in the US continues to grow, with more than a dozen states now requiring role-based access controls, data minimization, and purpose limitation. Tokenization unifies compliance across these laws by creating a standardized layer of protection that applies regardless of jurisdiction.
4. India’s DPDP Act
India’s privacy regime emphasizes consent and purpose-driven processing. Tokenization supports both by ensuring that any processing done outside the original purpose, such as analytics, support workflows, or AI training, happens on tokens rather than raw data.
5. APAC Privacy Momentum
Countries such as Japan, South Korea, and Singapore are refining privacy frameworks to emphasize pseudonymization. Tokenization fits directly into these models and is often explicitly cited as an acceptable control.
The Evolution of Tokenization Standards
Tokenization has matured dramatically in the past few years. Companies are no longer content with tokenizing only structured fields in relational databases – they need broad, intelligent tokenization that works across entire data ecosystems.
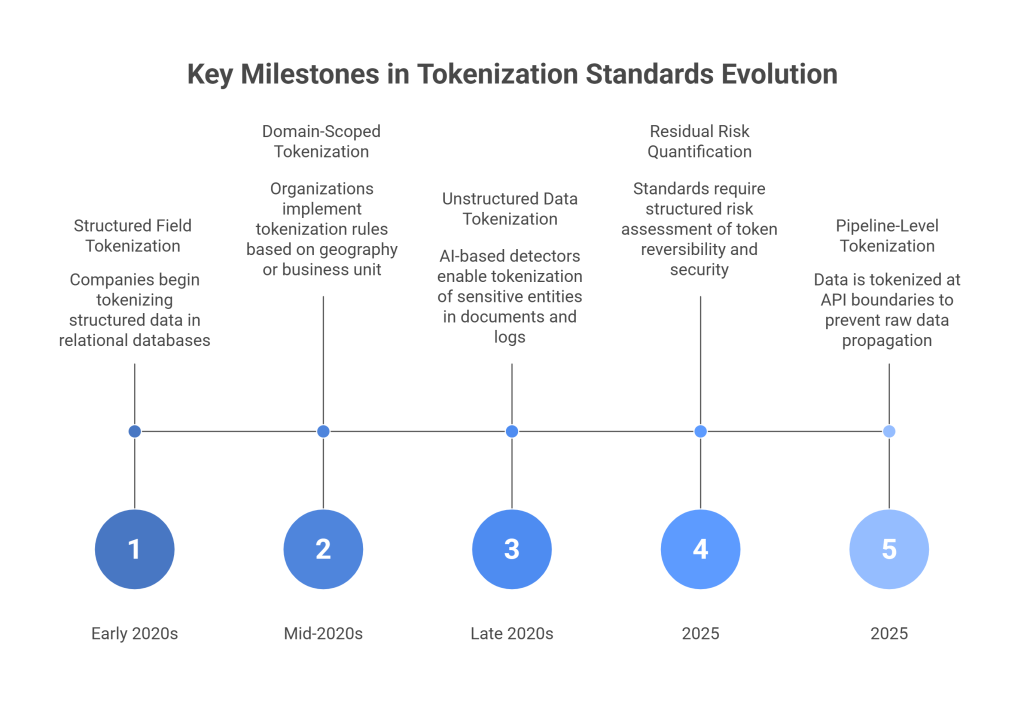
Domain-Scoped Tokenization
Organizations are now implementing tokenization rules that vary by geography, business unit, or system domain. This prevents unwanted correlation across environments.
For example, a customer’s email address might produce different tokens in EU and US systems, making cross-region re-identification impossible without proper authorization.
Tokenization for Unstructured Data
Support transcripts, legal documents, emails, PDFs, and chat logs contain enormous amounts of personal information. Traditional tools, such as regex, fail to detect PII at scale in these sources. Modern tokenization systems use AI-based detectors to identify sensitive entities and apply contextual tokenization.
Residual Risk Quantification
Standards now expect organizations to analyze how reversible tokens are, how secure their vaults are, and how salts and keys are rotated. This structured risk assessment is becoming a normal part of both compliance and enterprise procurement processes.
Pipeline-Level Tokenization
Companies increasingly tokenize data before it enters data lakes or training pipelines. By introducing tokenization at the API boundary or event-stream level, organizations prevent raw data from ever propagating into downstream systems.
How Tokenization Strengthens Regulatory Compliance
Tokenization aligns naturally with core regulatory principles, and that alignment is why it’s becoming mainstream.
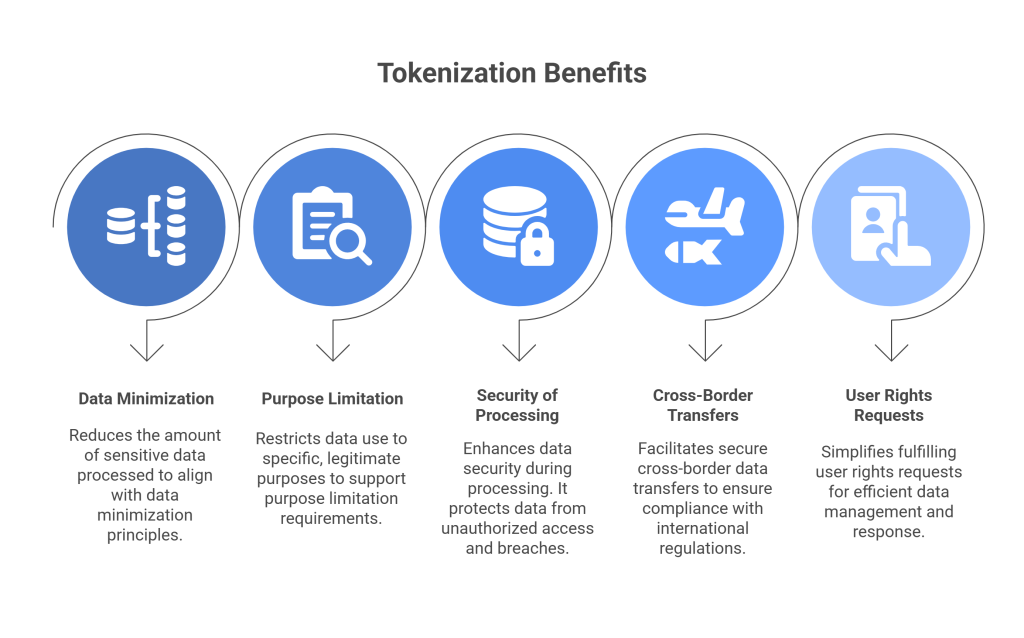
Data Minimization
Tokenization ensures only necessary data is accessible in its raw form. When only tokens move through your analytics, BI, or AI pipelines, your organization drastically reduces its exposure. This matches GDPR’s expectation that organizations process the minimum amount of personal data required.
Purpose Limitation
When tokens are tied to specific business purposes or domains, the detokenization process becomes inherently controlled. A token generated for customer support use cannot be detokenized by marketing systems unless explicitly authorized. This mapping between business purpose and data access is becoming an expectation in modern audits.
Security of Processing
Because tokens do not reveal personal information, they decrease the impact of a breach and lower the sensitivity classification of systems that only store tokenized data. Regulators increasingly see tokenization as an indicator of strong processing security.
Cross-Border Data Transfers
Regional token vaults allow global companies to operate without violating residency laws. Raw data stays in its region, while global teams work with safe tokens.
User Rights Requests
Finding and deleting raw data across dozens of services is challenging. When everything downstream uses tokens, organizations keep identifiable data centralized, making subject-access and deletion requests dramatically easier.
Best Practices for PII/ PHI Tokenization
While tokenization used to be an isolated project, it is now an architectural principle. Organizations adopting it in 2025 are focusing on a small set of practices that consistently reduce risk.
Introduce Tokenization Early in Pipelines
Tokenizing at the point of ingestion ensures fewer systems ever encounter raw data. This reduces compliance complexity, breach exposure, and cost.
Use AI-Based Detection for Unstructured Text
Identifying personal data in emails, documents, and chat transcripts requires context. Modern detection systems combine NLP, entity recognition, and pattern matching to understand not just the text but the meaning behind it.
Separate Token Vaults by Region and Business Unit
A distributed vault model makes it easier to comply with data residency laws and prevents internal data correlation.
Maintain Full Audit Logs
Every detokenization attempt, every policy decision, and every data flow should be recorded. Companies that do this well find audits become far more predictable.
Rotate Keys and Review Policies Regularly
Tokenization is not a “set and forget” system. Regular reviews help maintain alignment with evolving regulatory expectations.
Where Protecto Helps
Protecto has emerged as a leading solution for companies facing modern data and AI compliance challenges. Rather than focusing solely on tokenization, Protecto takes a holistic approach that integrates discovery, protection, and enforcement.
Protecto supports compliance strategies through:
- Automated discovery and classification across structured and unstructured systems, helping teams understand exactly where sensitive data flows before implementing controls.
- AI-powered tokenization that applies context-aware transformations to complex text, documents, and communications—far beyond traditional column-level tokenization.
- Domain-scoped and regional token vaults, enabling cross-border operations while supporting strict residency rules.
- Policy-based detokenization controls, allowing organizations to enforce purpose limitation and role-based access consistently across all workflows.
- Audit-grade logging and monitoring, giving teams continuous visibility into data access and policy enforcement for GDPR, the EU AI Act, SOC 2, HIPAA, PCI DSS, and evolving frameworks.
- Integration with AI pipelines, ensuring PII never enters model training or inference layers without intentional approval.

