
Synthetic data has been fine for testing software for decades. Traditional apps follow rules. You check inputs, check outputs, file a bug when something breaks.
AI is different. AI gets deployed into the situations where the rules aren’t clear and context is everything. The edge cases aren’t exceptions. They’re the whole point.
That changes what your test data needs to look like.
Most teams building AI right now face this choice quietly: synthetic data for ai or real enterprise data that’s been properly masked. Synthetic wins on convenience. It’s easy to generate, dodges privacy headaches, and lets you move fast without touching production. I get it.
But I keep seeing the same thing play out at enterprises shipping AI into real workflows. Synthetic data gives you a false sense of readiness. The system works in dev. It demos great. Then it hits production and falls apart.
Real data is messy, and that’s the whole point
Enterprise data is full of garbage. Documents have typos. Fields are half-filled. Formats change between departments, between years, between whoever was entering records on a random Tuesday afternoon.
Synthetic data generators smooth all of that away. They produce statistically plausible records that look fine row-by-row but miss the texture that makes real data hard to work with.
Healthcare is a good example. A synthetic patient dataset gives you clean records with reasonable values in every field. Real patient data has age-dosage mismatches, incomplete diagnostic codes, and free-text notes that directly contradict the structured fields. Those aren’t bugs. That’s what your AI will actually face. If it’s never seen any of that, you haven’t tested it.
The relationship problem
This one burns teams the hardest.
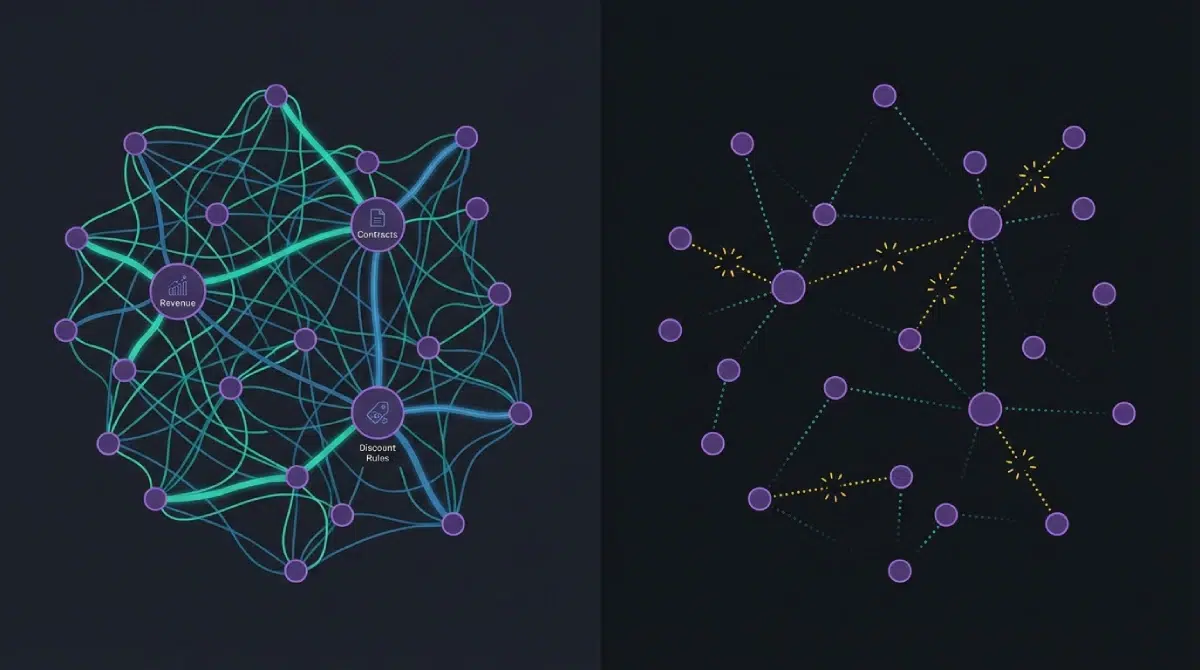
Enterprise data is deeply connected. Customer revenue ties to contract size. Contract size ties to discount rules. Discount rules feed into lifetime value calculations. Pull on one thread and everything shifts.
Synthetic generators usually produce values independently, or with simplified statistical models at best. Check one record at a time and it looks fine. But the relationships between fields quietly fall apart. Discount percentages that violate pricing policies. Revenue figures that can’t coexist with the contract terms. Lifetime values that exist nowhere in reality.
When an AI agent reasons over this kind of data, it inherits those broken relationships. The decisions it makes are wrong in ways you can’t easily trace back, because every individual record looked perfectly fine.
Edge cases aren’t optional
In traditional software, a missed edge case gets you a bug ticket. In AI, a missed edge case means the system fails in the exact situation where it was supposed to help.

A contract written under unusual legal terms. A financial transaction sitting right at a compliance threshold. A healthcare case with overlapping conditions that don’t fit any standard category.
Rare in any dataset. Also exactly where your AI has to perform.
Synthetic data optimizes for the average. Rare scenarios get dropped or simplified. You end up with a system that passes every test you throw at it and then fails on the cases that actually matter.
RAG and agents make this worse
When AI systems use enterprise data for live reasoning, the stakes go up fast. In RAG, retrieved documents become the context for answers. With agents, enterprise data drives planning and automated actions.
If the underlying data is synthetic, the reasoning environment is artificially clean. Your agent looks reliable in dev because it’s never dealt with a messy contract, an ambiguous invoice, or a compliance doc with conflicting clauses. Put it in front of real enterprise data and it stumbles in ways you didn’t predict. Debugging that is expensive, and explaining it to stakeholders is worse.
The liability angle
Here’s something I don’t see discussed enough.
In regulated industries like healthcare, financial services, and insurance, the quality of your test data isn’t just an engineering concern. It’s a liability concern.
Say you trained and tested your AI on synthetic data that didn’t capture real-world complexity. That system then makes a decision affecting a patient or a customer. You now have a problem that goes well beyond a production bug. Regulators are starting to ask how AI systems were validated. “We tested on synthetic data” is a weak answer when the system missed something that real data would have caught.
You can use real data without the risk
I know the pushback here. Real production data carries privacy and security risk. You can’t hand it to a dev team or pipe it into a model. That’s fair.
It’s also what we built Protecto to solve. We mask and tokenize sensitive information while keeping the structure and relationships that AI depends on. Names, identifiers, financial values get replaced with consistent tokens that behave the same way across documents, databases, and workflows. What comes out is data that’s safe to use but still acts like the real thing.
You don’t have to choose between synthetic data that lacks depth and raw data that carries risk. You can work with real-world data safely, messiness and edge cases included, so your AI actually learns from the environment it’ll operate in.
Synthetic data is fine for early experiments. But when the goal is reliable AI in production, you need data that started in the real world. There’s no shortcut around that.
