

AI systems are no longer experimental. They sit at the center of product experiences, internal workflows, and customer-facing automation. As soon as an AI feature ships, it starts handling real data. Customer messages. Internal documents. Support tickets. Logs. Training samples.
That’s when AI data security stops being an abstract concern and becomes a product requirement.
What we’ve learned working with teams deploying AI in production is that most data security issues don’t come from dramatic failures. They come from small, invisible gaps. An unfiltered prompt. A verbose log. A dataset copied for testing. Individually harmless. Collectively risky.
The good news is this: AI data security does not require slowing down innovation. With the right strategy, it becomes a quiet, reliable layer that supports scale, compliance, and trust—without constant intervention.
Why AI Data Security Is Different From Traditional Data Security
Traditional applications process data in predictable ways. Inputs are structured. Outputs are stored in known locations. Access paths are well defined.
AI systems behave differently.
They ingest unstructured data, reason across multiple sources, and generate new content dynamically. A single prompt can include personal data, internal context, and derived insights—all blended together. That data may flow through models, tools, vector stores, logs, and analytics systems in ways that are hard to track retroactively.
This creates three fundamental challenges for AI data security:
- Visibility gaps: Teams often don’t know where sensitive data enters or spreads.
- Propagation risk: Once personal data enters an AI pipeline, it tends to replicate.
- Delayed discovery: Issues are often found during audits or customer reviews, not during development.
The goal of modern AI data security is to prevent these problems by design, rather than reacting to them later.
What “Good” AI Data Security Looks Like
Before diving into solutions, it helps to define the outcome.
When AI data security is working well:
- Sensitive data is minimized before it reaches models
- AI outputs don’t leak personal or regulated information
- Logs and traces are safe by default
- Training pipelines don’t accidentally absorb PII
- Compliance questions can be answered with evidence, not assumptions

Most importantly, teams feel confident shipping AI features without worrying about what they might have missed.
Solution #1: Control Data at the Entry Point
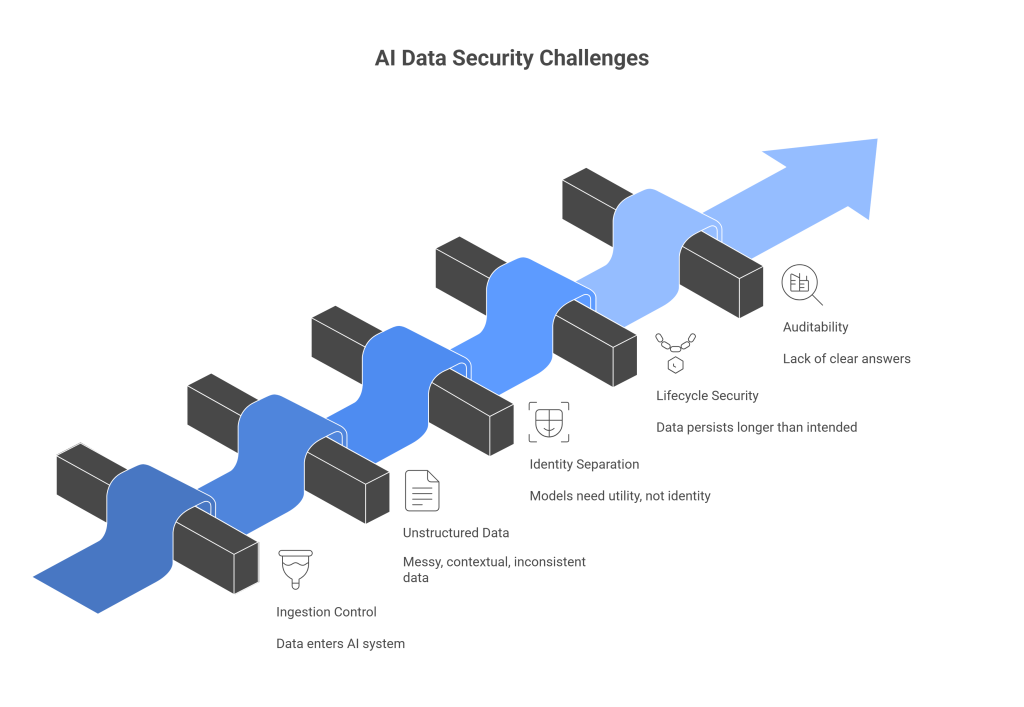
The most effective AI data security strategies focus on prevention at ingestion.
Instead of trying to clean up data everywhere it might go, mature teams control what enters the AI system in the first place. This includes user prompts, uploaded documents, tool responses, and system-generated context.
Practically, this means applying detection and transformation steps before data is passed to the model. Personal identifiers can be masked or tokenized. Irrelevant fields can be removed entirely. The model still receives the information it needs to function, but without unnecessary exposure.
The outcome is immediate. Sensitive data never reaches downstream systems, which means it can’t leak into logs, embeddings, or outputs later.
Solution #2: Treat Unstructured Data as the Primary Risk Surface
Most AI systems today operate on unstructured text. Chat messages. Emails. PDFs. Notes. Transcripts.
This is where traditional security approaches fall short. Pattern-based rules catch only the most obvious cases. Real-world data is messy, contextual, and inconsistent.
Effective AI data security strategies use contextual understanding to detect sensitive information in text. Not just email addresses and phone numbers, but names paired with locations, health references, financial context, and internal identifiers.
When teams adopt this approach, they stop playing whack-a-mole with edge cases. Detection becomes reliable, and false positives drop. That reliability is what allows security controls to stay enabled in production without disrupting users or developers.
Solution #3: Separate Identity From Utility
A key insight in AI data security is that models rarely need to know who someone is. They need to know what to do.
For example, a support agent doesn’t need a customer’s real email address to draft a response. A summarization model doesn’t need real names to extract key points. A recommendation engine doesn’t need raw identifiers to detect patterns.
Tokenization makes this separation possible. Identifiers are replaced with consistent tokens that preserve relationships without exposing identity. Re-identification is possible when necessary, but only through controlled, logged pathways.
This approach dramatically reduces risk while preserving full functionality. It also aligns well with regulatory expectations around data minimization and purpose limitation.
Solution #4: Secure the Entire AI Lifecycle, Not Just Inference
Many teams focus AI data security efforts on prompts and responses. That’s necessary, but not sufficient.
AI systems create and consume data throughout their lifecycle:
- Training and fine-tuning datasets
- Embeddings and vector stores
- Evaluation logs
- Feedback loops
- Monitoring and debugging traces
Each stage introduces opportunities for sensitive data to persist longer than intended.
Strategic AI data security accounts for all of these stages. Data is protected before ingestion. Stored artifacts are governed by retention rules. Logs are scrubbed automatically. Training pipelines enforce strict controls on what data can enter.
The result is consistency. Teams don’t need separate rules for each system. Security becomes part of the lifecycle, not an afterthought.
Solution #5: Make Auditability a First-Class Feature
At some point, every serious AI product faces scrutiny. From customers. From partners. From regulators.
When that moment arrives, the difference between stress and confidence comes down to evidence.
Strong AI data security strategies produce clear answers to questions like:
- What personal data does the system process?
- Where does it flow?
- How is it transformed?
- Who can access the original data?
- How can it be deleted or corrected?
These answers should come from logs and policies, not tribal knowledge. When auditability is built into the system, reviews become routine instead of disruptive.
What Product Managers Should Pay Attention To
For product managers, AI data security is tightly linked to roadmap stability.
Security gaps discovered late often lead to rework, delayed launches, or restricted features. Preventive controls reduce that risk. They also unlock enterprise conversations earlier, because security and privacy questions have clear, consistent answers.
A useful mental model is this: every AI feature implicitly makes promises about how data is handled. Strategic security ensures those promises are kept without constant manual oversight.
What Developers Appreciate About Strategic AI Data Security
From a developer’s perspective, the best security systems are the ones that don’t demand constant attention.
When AI data security is implemented at clear boundaries—such as ingestion points and pipeline interfaces—developers don’t have to reason about privacy inside prompts, chains, or model logic. They can focus on behavior and performance, knowing that sensitive data is handled consistently upstream.
This reduces cognitive load and prevents subtle bugs that only appear under real-world usage.
Where Protecto Fits In
Protecto is built to support these strategic approaches to AI data security.
It provides a unified layer for detecting sensitive data in unstructured inputs, transforming it through masking or tokenization, and enforcing consistent policies across AI pipelines. By operating before data reaches models, logs, or storage systems, Protecto helps teams prevent exposure rather than react to it.
Protecto also maintains audit-grade visibility into how data is handled, making it easier for teams to answer compliance and security questions with confidence.
For developers and product managers, this means fewer surprises and more predictable delivery.

