

A single day in a modern stack is enough to see the failure modes.
- SQL needs stable joins across fact tables and slowly changing dimensions. If a token is random or per row, analytics goes dark and engineers create back doors to keep their jobs moving.
- JSON evolves without asking for permission. Optional fields, arrays, nested objects, and partner quirks arrive mid-week. If tokenization is not path aware, a value loses meaning.
- Logs flatten context and leak on accidents. If logging is not policy aware, a supposedly masked value sneaks into a line and is shipped to a vendor.
- Prompts are free text. Users paste identifiers into chat. Agents pull context from tools. If you do not scan before and after the model, you will embed secrets.
What “durable” actually means
A durable token keeps usefulness and privacy at the same time.
- Deterministic by domain. The same email becomes the same token inside a defined scope so joins work. Email in Europe for tenant A has a different token than the same email in the United States or in tenant B.
- Format aware when needed. Some systems validate phone numbers or IDs. A format-preserving option keeps those checks happy without exposing the original.
- Scoped keys. Keys and salts are derived by region, tenant, and purpose. A breach in one area cannot be replayed in another.
- Metadata that travels. A sidecar record says what domain and version created the token, which policy applies, and where it may be re-identified.
- Auditable flows. Every transform and re-identification is logged with who, what, when, and why.
These are simple ideas. They only work if enforced on the runtime path and not after the fact.
A token control layer on the hot path
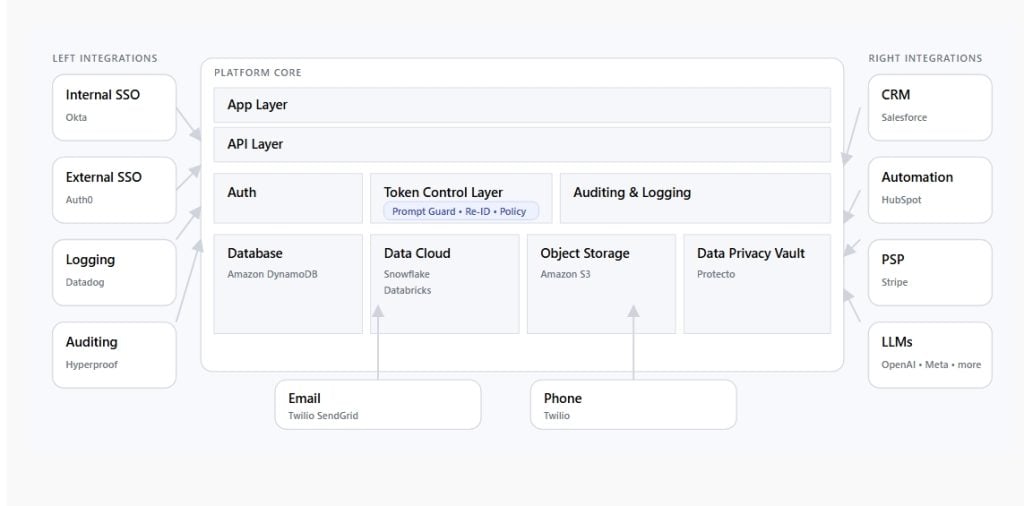
A small control layer keeps tokens honest. It has four responsibilities. Inspect. Transform. Enforce. Log.
flowchart LR
subgraph Edge[“Ingress. APIs. ETL.”]
A[PII arrives] –> B[Inspector]
B –> C[Policy Decision]
end
subgraph TCL[“Token Control Layer”]
C –> D[Tokenizer]
D –> E[Tokens + Metadata]
C –> F[Redactor/Masker]
E –> G[Audit Log]
end
subgraph Use[“SQL . JSON . Logs . Prompts”]
E –> H[Warehouse/OLTP]
E –> I[Event Streams]
E –> J[Vector Index]
H –> K[Analytics/Joins]
I –> L[Services]
L –> M[Prompt Builder]
M –> N[LLM/Agents]
end
subgraph ReID[“Selective Re-identification”]
N –> O{Authorized?}
O — yes –> P[Reveal Minimal Fields]
O — no –> Q[Keep Token/Mask]
end
The control layer sits where data comes in and before prompts go out. It is also the only place that can reveal a token. A short-lived permission grants the minimum plaintext and leaves a paper trail behind. Protecto ships this style of runtime guard so teams do not build it from scratch.
Token types you actually need
You do not need many. You need a small menu with clear rules that everyone understands.
Deterministic domain token
Purpose. Stable joins in SQL and consistent identifiers in events.
Behavior. HMAC or similar keyed function using a per-domain, per-tenant, per-region key version.
Usage. Emails, phone numbers, account IDs where analytics or retrieval must correlate rows.
Format-preserving token
Purpose. Keep validators and legacy systems calm.
Behavior. Format-preserving encryption or a constrained mapping that keeps length and character set.
Usage. Phone, SSN, national IDs when validation would otherwise reject the data.
Context-scoped token
Purpose. Reduce blast radius.
Behavior. Deterministic inside a scope like tenant=acme, region=eu, purpose=analytics. Different outside.
Usage. Multi-tenant platforms, data residency, vendor handoffs.
One-way tag
Purpose. Grouping without any possibility of reveal.
Behavior. Hash with a pepper. Not reversible.
Usage. Cohorts, deduplication, experiments.
That is enough for most stacks. If a new token type appears, it should solve a real constraint rather than add complexity.
Practical design rules that hold up
Bind determinism to a domain. There is no global key. Derive keys per domain, region, tenant, and version. Store the version with the token.
Carry small metadata. Keep a sidecar that says domain, scope, version, residency, and allowed actions. Keep it searchable.
Use format-preserving only where required. Default to opaque tokens. Bring format only for strict validators.
Scope hard. Tokens made for analytics stay in analytics. Tokens made for support cannot unlock warehouse data by accident.
Make logging complete. The field. The transform. The requester. The purpose. If it is not in the log, it did not happen.
Guard prompts both ways. Scan inputs before the model and scan outputs before storage or display.
Treat re-identification as a verb. Every reveal is a decision with identity, purpose, and time limits. Default to no.
How this shows up in each data shape
SQL. Keep joins stable and bounded
Tables need predictable joins. Deterministic tokens give you those joins, but the domain and version must be part of every query to avoid silent cross-scope matches. Keep the original restricted table while you roll out protected tables. Then, when tests pass and access policies are in place, retire plaintext. Many teams add a temporary mapping table during key rotation. Old tokens map to new tokens so long windows of data keep joining while you backfill.
JSON. Tokenize with path context
JSON payloads contain arrays, nested objects, and optional fields that appear months after you ship. A path-aware transform maps fields like $.email and $.contact.phone to different token types. The configuration is versioned. That configuration is also policy. If a partner sends a payload that does not match, you reject or quarantine it instead of “best-effort” guesses that drift. When schemas evolve, update the config together with tests that prove the new path mapping is correct.
Logs. Keep secrets out by design
Structured logs are the only reasonable default. If a field is sensitive, strip it at the source or replace it with a token. It is better to log metadata about a token than to log a masked value that tempts people to reverse it. Cross-check logging pipelines, sinks, and vendor destinations. The audit trail for tokenization and re-identification is separate from application logs. That trail is append-only and tamper evident.
Prompts. Free text needs a seatbelt
Prompts blend everything. User inputs, system instructions, tool results, and retrieved context sit side by side. A prompt guard catches identifiers and replaces them with tokens before the request reaches a model. The same guard scans outputs. If a downstream tool asks for data by email, it receives the token instead. Retrieval works because the vector store was indexed with tokens and a token metadata column sits next to embeddings.
sequenceDiagram
participant App
participant Guard as Prompt Guard
participant LLM as Model/Agents
App->>Guard: Draft prompt with user text + context
Guard->>Guard: Detect identifiers. Replace with tokens
Guard->>LLM: Clean prompt + token map
LLM–>>Guard: Response
Guard–>>App: Scan output. Re-tokenize if needed
This is where a managed runtime control like Protecto earns its keep. It sits before and after the model so teams do not reinvent a fragile set of regex rules for every new agent.
One small reference snippet
You asked for fewer code blocks. Here is one compact example that captures the idea without the scaffolding. It shows a deterministic token that binds to a domain and scope so the same value produces different tokens in different contexts.
import hmac, hashlib
def ddt(value: str, *, domain: str, tenant: str, region: str, version: str, master: bytes) -> str:
msg = f”{domain}|{tenant}|{region}|{version}|{value}”.encode()
mac = hmac.new(master, msg, hashlib.sha256).digest()
# 22 chars URL-safe token
return (mac.hex()[:22])
In production you keep the master in a KMS or HSM. You also version and rotate keys, and you log every transform. The concept stays the same.
Re-identification is narrow and short-lived
Re-identification is not a helper function. It is a policy enforcement point that answers a few questions. Who is asking. For what purpose. Which fields. How long is access valid. The system returns a small handle, not raw plaintext, and logs both the authorization and the redemption. A handle expires quickly. The next request repeats the decision. Access in Europe uses European keys and keeps European logs. This is how a global company stays compliant without stopping work.
Validation patterns that keep things from drifting
A handful of patterns keep a token program from slowly tipping over as systems grow.
- Schema contracts. Declare which fields are tokenized, how, and in which version. The contract lives next to code and has tests.
- Canary datasets. Small synthetic payloads exercise path transforms across edge cases like nested arrays and missing fields. The suite runs in CI.
- Round-trip tests for re-ID. A test proves that an unauthorized identity fails and an authorized identity reveals only the requested fields.
- Leak canaries. Plant fake values that should never appear. If they show up in embeddings, logs, or prompts, the guard missed them.
- Operational baselines. Dashboards show tokenization counts by field, re-ID approvals vs denials, and region boundaries. Spikes trigger alerts.
None of these add friction when they are part of the control layer. They prevent emergency rewrites later.
Real scenarios that recur
1) Warehouse analytics with event joins
Marketing wants multi-touch attribution. Data sits in OLTP, events, and a warehouse. Deterministic tokens on emails and phones enable joins. Every query filters by token version and region to avoid mismatched scopes. During key rotation, a small mapping table allows old and new tokens to co-exist while you backfill.
2) Partner CRM that rejects anything not shaped like a phone
A partner system validates phone numbers. You keep default opaque tokens everywhere else. On the partner edge, you apply a format-preserving token so the partner’s validator passes without ever seeing the original. Per-country constraints are pulled from standard phone metadata so output length and digits line up.
3) Support agents and free-form notes
Support teams paste identifiers into notes without thinking about it. A prompt guard scrubs inputs and replaces emails with deterministic tokens. When the agent asks a tool to fetch documents “for this user,” the tool looks up by token. No plaintext crosses the model boundary. If the agent truly needs to see an email, a short-lived reveal is authorized with identity and purpose, and the audit log records it.
4) Residency and sovereignty controls
Keys are scoped by region. A token created in Europe is useless in the United States. A global fraud team with a European legal basis receives a European re-identification path with European logs. Short windows. Minimal fields. Full audit. The default for cross-region requests is deny.
5) Vector search that keeps secrets
You remove identifiers and replace them with tokens before creating embeddings. Retrieval still correlates because the vector row includes token metadata. When a downstream application wants to put a label next to a result, it asks for a short-lived reveal for a single field and a single user. The handle expires quickly. The audit trail proves it happened.
The operating model that makes this stick
A durable token program is part technology and part habit. The technology is the control layer, scoped keys, and logging. The habit is to treat tokens as first-class data, not as a patch.
- Ownership. One team owns the token policy, config, and keys. Application teams consume them through the control layer.
- Policy as code. Tokenization paths, allowed re-ID fields, and residency rules live in version control. Changes require reviews and tests.
- Short feedback loops. Every change runs canaries and round-trip tests. Every incident includes proof that the right alerts fired.
- Education. Engineers know the four token types and when to use each. Analysts know to filter on version and region. Support knows that a reveal is a request, not a right.
With this operating model, you do not hold up shipping. You keep privacy and velocity on the same path.
Where Protecto fits
If you want this design without building every part yourself, Protecto provides a runtime control layer that inspects inputs, applies policy, creates scoped deterministic or format-preserving tokens, and logs at the field level.
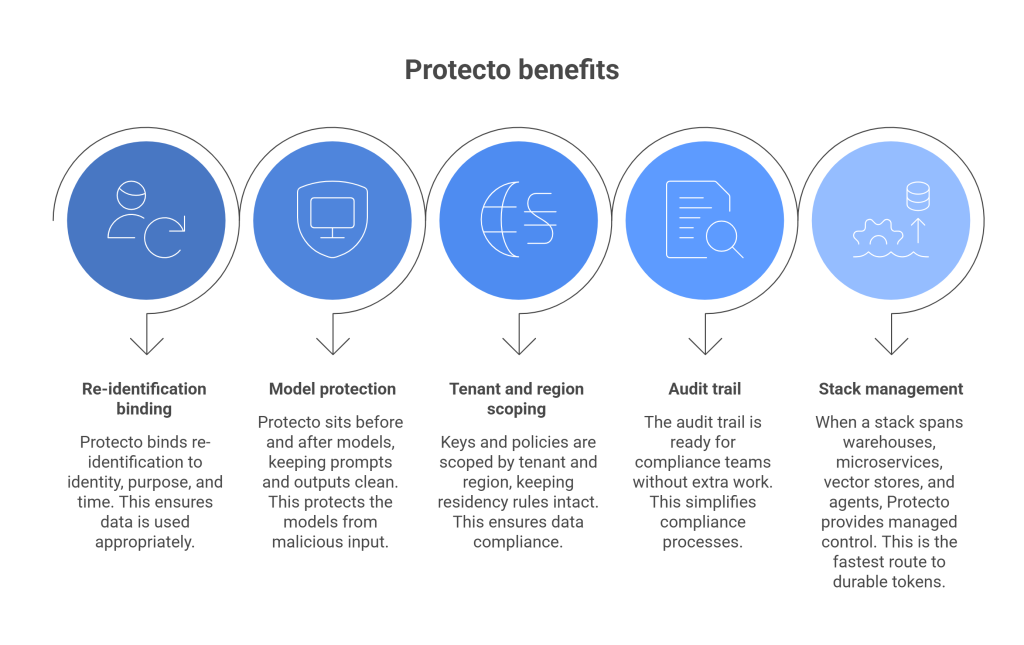
- It binds re-identification to identity, purpose, and time.
- It sits before and after models so prompts and outputs remain clean.
- Keys and policies are scoped by tenant and region, which keeps residency rules intact.
- The audit trail is ready for compliance teams without extra work.
- When a stack spans warehouses, microservices, vector stores, and agents, this kind of managed control is often the fastest route to durable tokens.


