

When news broke that the Head of CISA uploaded sensitive data to ChatGPT, the response was predictable: panic, headlines, and renewed questions about AI safety. But this incident reveals more about confusion than actual risk.
The real issue? Most organizations don’t understand what they’re actually risking when they use AI tools. Let’s fix that.
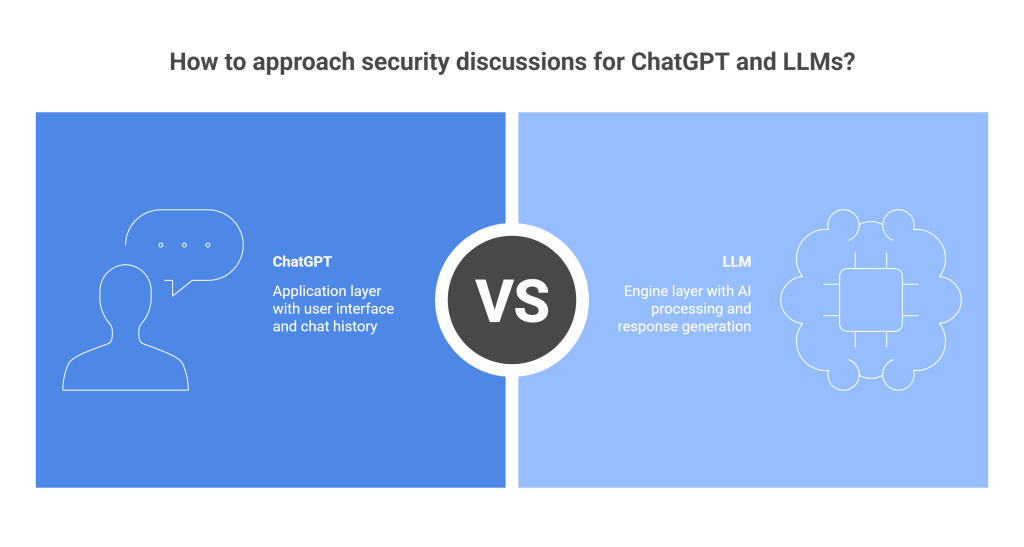
Stop Confusing the Application with the Engine
Here’s what most security discussions get wrong: they treat “ChatGPT” and “the LLM” as the same thing. They’re not.
ChatGPT is the application—the interface you interact with, complete with chat history, settings, and user accounts.
The LLM (Large Language Model) is the engine—the underlying AI that processes your input and generates responses.
Each layer has different risks. Conflating them leads to bad security decisions.
Breaking Down the Real Risks
Risk Layer 1: The LLM Itself
The good news: If you control the settings, sending data to an LLM (GPTs in case of OpenAI) carries low risk.
- Enterprise subscriptions let you disable training on your data
- Your inputs won’t be learned from or retained in the model
- The LLM processes and forgets (when configured correctly)
The exception: Data sovereignty and residency laws. If regulations require your data to stay within specific geographic boundaries, you legally cannot send raw data to external LLMs, no matter how secure the settings.
The solution: Use an intermediary layer that protects data before it reaches the LLM. Tools like Protecto mask, tokenize, or encrypt sensitive information, ensuring compliance while maintaining AI functionality.
Risk Layer 2: ChatGPT as an Application
This is where the CISA incident becomes relevant. As a SaaS application, ChatGPT has two primary exposure points:
Stored Chat History
- Your conversations are saved by default
- If sensitive data appears in your history, it’s now stored on OpenAI’s servers
- Access controls matter—who can see your organizational chat logs?
Model Training Opt-In
- Unless explicitly disabled, your data may be used to train future models
- This means sensitive information could theoretically influence model outputs for other users
- Enterprise accounts can disable this, but many users don’t check
The Bottom Line: Context Determines Risk
The CISA incident isn’t proof that AI is dangerous. It’s proof that AI tools require the same disciplined approach as any enterprise software:
If you can control settings and have no residency restrictions:
- Use enterprise LLM accounts
- Disable training on your data
- Turn off chat history or regularly purge it
- Train employees on what data is appropriate to share
If you’re bound by data residency or sovereignty laws:
- Don’t send raw sensitive data to external LLMs
- Use intermediary tools (like Protecto) to mask/tokenize before processing
- Ensure data stays within required geographic or network boundaries
If you’re unsure:
- Audit your regulatory requirements first
- Implement a data protection system
- Default to the more restrictive approach until you have clarity
What This Means for Your Organization
AI isn’t inherently risky, but uninformed use is. The question isn’t “Should we use AI?”—it’s “Do we understand our data, our regulations, and our controls well enough to use AI safely?”
Before your next ChatGPT session, ask:
- What type of data am I about to share?
- Do I have the right settings enabled?
- Am I legally allowed to send this data externally?
Get those answers right, and AI becomes a powerful tool. Get them wrong, and you’re the next headline.
Need help securing your AI workflows? Protecto provides enterprise-grade data protection that works with any LLM, ensuring compliance without sacrificing AI capabilities.


