

Being semantically valid, synthetic data makes it a great pick but many teams get blindsided in production. The model behaves until a rule holds, corner cases break it, or a regulator asks, “Where did this value come from?”
This piece explains why Protecto uses tokens instead of synthetic data. It explains what fails in the field, what scales, or what stands up during an audit. So if you want a blueprint that survives a Tuesday outage and a Friday board meeting, read on.
1) Synthetic data is semantically valid. This is a problem.
Synthetic data is designed to look right. It preserves structure, types, formats, and rough distributions. That surface-level validity gives a sense of safety.
The problem sits under the surface. The model learns from patterns, not just from types; synthetic address hints at neighborhood signals, synthetic names hint at ethnicity and gender, and synthetic claim amounts hints at fraud cues. Semantics leak back into decisions and go unnoticed until those decisions are challenged.
What looks valid can still be harmful. Unlike tokens, synthetic data cannot differentiate between patterns and people. Tokens represent a value without revealing it, retaining the original link, policy, and purpose. Protecto attaches purpose and policy to the token at creation that travels with the token when used.
For example, A real name like “Tom” is replaced with “John.” Another real name, “John,” is replaced with “Mike.”
Each synthetic value is valid, plausible, and indistinguishable from real data – creating semantic collision.
Now “John” refers to two different people depending on context. Systems can no longer tell whether “Raja” is a real individual or a stand-in. Humans reading the data may assume it is factual while it is actually reinterpreted.
Tokens avoid this entirely. A token like <NAME_TOKEN_91af> carries no meaning. It doesn’t resemble a real name or invite assumptions. It exists only as a placeholder.
2) Synthetic data can distort system behavior
Models and downstream logic are sensitive. Synthetic data introduces shifts in ways that are easy to miss. Distortion creeps in:
- Boundary rarity. Generators under-sample rare but legal values. Systems then fail when those values appear.
- Correlation decay. Weak but meaningful correlations vanish. Features look independent and the model overfits or underreacts.
- Temporal drift. Synthetic snapshots freeze history whereas real data evolves. Retrains on synthetic data teach the model yesterday’s weather.
- Policy blind spots. Business rules reference attributes that synthetic data approximates. The rule triggers at the wrong time.
- Edge-case poverty. Real logs have messy edge cases. Synthetic sets are neat. The mess shows up in production, not staging.
Tokens keep the original distribution intact. You feed the model the same shape, timing, and correlation while retaining the raw values. The system learns from what happened, not from a statistically polite imitation. With Protecto, you tokenize sensitive spans in text and fields in tables. You keep the sequence and frequency without exposing sensitive data.
Quick checklist to spot distortion
- Compare rare value rates against production logs.
- Track pairwise correlations for key features.
- Validate temporal patterns like day-of-week and seasonality.
- Run policy unit tests on guardrail rules with your training set.
- Run a canary. Fine-tune on real tokens and on synthetic. Compare behavior, not only metrics.
3) Synthetic data introduces false equivalence
A synthetic record looks like a record but is not the same thing. Teams forget the difference, creating false equivalence. When you run a POC (proof of concept), the audit trail says you used “non-sensitive synthetic data.” A month later, the same pipeline runs in production. When regulators ask how you validated fairness, you reference the POC but the answer does not hold.
False equivalence appears in three flavors. Teams assume
- So we safe because we validated on synthetic data
You validated on lookalikes. Not on the thing itself. You proved a shape, not a behavior under stress. - We trained on synthetic, so no personal data touched the model.
You trained the model to respect patterns that map back to people. The model still holds a decision boundary learned from the real world. While the exposure path changed, the risk posture did not. - We shared synthetic data. So we can skip DPA and DPIA.
Synthetic data is an engineering technique that only shifts responsibility but does not vanish.
With tokens, you keep a one-to-one relationship with the original that proves lineage, answer hard auditor questions, maintain records influencing this prediction, and track policies that allowed access. Protecto maintains that chain automatically. The token removes the “as-if” thinking that derails reviews.
A simple table for clarity
| Question | Synthetic data | Tokens |
| Can I explain where a value came from | No. You can only explain the generator. | Yes. You can trace to the original under policy. |
| Does my model see real distribution | Maybe. Often partially. | Yes. Same shape, timing, correlation. |
| Can I redact or revoke later | No. Data is minted and spread. | Yes. Revoke or rotate tokens. Policies apply post-hoc. |
| Can I pass an audit without gymnastics | Hard. Lots of caveats. | Straight. Provenance rides with tokens. |
4) Synthetic data causes collisions and confusion at scale
One synthetic dataset is manageable. Chaos increases as the number of datasets go up. Here is what happens when you scale.
- Naming sprawl. Each team generates a slightly different flavor. Columns drift. Documentation drifts faster.
- Collision risk. Two synthetic records claim the same ID. Two datasets disagree on a household. Cross-system joins break in quiet ways.
- Reconciliation pain. Environments do not match. Bugs appear in one place and vanish in another.
- Knowledge debt. The person who tuned the generator leaves. No one knows which knobs matter.
- Governance theater. Everyone spends time proving that “this synthetic dataset is close enough.” That time should have gone into real testing.
At scale, tokens simplify due to consistency. Due to its stable nature across systems, teams can run E2E tests and revoke globally if policy changes.
Protecto offers differential visibility to engineers and analysts while the LLM sees only what its prompt policy allows.
Operational pattern that works
- Identify sensitive spans and fields.
- Tokenize at ingestion.
- Enforce policies in the token service.
- Keep non-sensitive data raw for fidelity.
- Log token creation, access, and reversal attempts.
- Rotate or revoke on policy change.
- Audit with reports that reference tokens, not raw values.
5) Reversibility is not enough. Intent matters.
A common misconception held by businesses is that their synthetic data is irreversible. On a surface level, it sounds logical, but does not solve the real problem. The question is not only “Can you reverse the sample.” The question is “Should the system have seen any personal signal in the first place.” Also, “Can you prove the purpose limitation?”
Three intent questions to answer
- Purpose. Why did this model or person see this information?
- Proportionality. Did they see more than needed for that task?
- Provenance. Can we show what was used to reach a decision.
Tokens carry intent. A token can encode purpose. It can enforce proportionality at read time. It can show provenance on demand. Synthetic data does not carry intent. It is just another dataset with a backstory.
For example, if your LLM agent reads tickets from a support queue, it needs context, not full PII. Feeding it synthetic tickets will result in hallucinations on order numbers and fail on returns that link to a payment dispute. With tokens, order numbers or customer emails are tokens. Policies allow a just-in-time detokenization of that one field in a controlled function without broad exposure.
Protecto enforces intent into the token lifecycle. Creation encodes purpose. Access requires purpose. Audits prove purpose.
6) Where synthetic data does belong
Synthetic data is not a villain. It shines in particular use cases but cannot be used as a universal solvent. Use it in –
- UI and workflow development. Designers and frontend engineers need screens filled with safe examples.
- Load and performance testing. You need volume and variety, not personal truth.
- Chaos drills. You want to inject odd shapes to stress error handlers.
- Simulation and what-if analysis. You want to imagine new futures and see if systems hold.
- Education and demos. You want to teach without exposing real data.
Rules of thumb for using synthetic safely
- Label it loud. Keep it out of training and decision pipelines.
- Do not mix synthetic and real data in the same store.
- Do not use synthetic outputs to validate fairness or safety.
- Do not treat synthetic as a governance shortcut.
- Consider tokens when behavior, lineage, or intent matter.
A blended strategy often works. Use tokens to protect real data in production and model development. Use synthetic data to mock UIs, generate scale tests, and explore edge shapes. Keep the lines clean. Protecto supports both. We prefer tokens for anything that touches decisions, users, models, or audits.
How Protecto’s tokenization works without breaking your stack
A token replaces a sensitive value with a non-sensitive surrogate. The surrogate is format-aware that retains length, checksum, or structure while the original value sits behind a policy and a control plane.
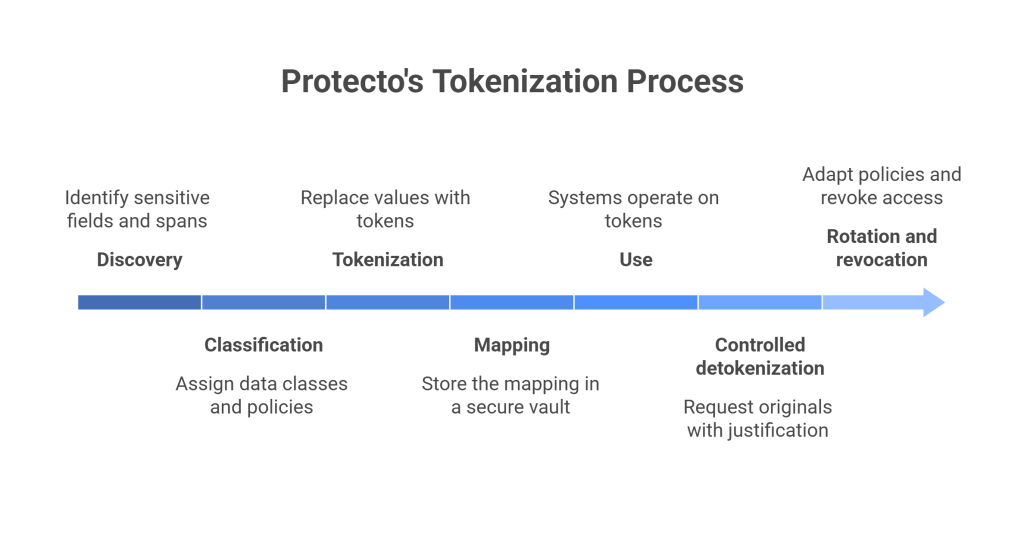
Core mechanics
- Discovery. Identify sensitive fields and spans. Structured and unstructured.
- Classification. Assign data classes and policies. Personal, financial, health, confidential.
- Tokenization. Replace values with tokens. Preserve formats for compatibility.
- Mapping. Store the mapping in a secure vault with role and purpose controls.
- Use. Systems operate on tokens. Models train on tokens. Analytics run on tokens.
- Controlled detokenization. Functions with a justifiable purpose can request originals. Every request is checked and logged.
- Rotation and revocation. Policies change. Tokens adapt. The mapping can be rotated or access revoked without rewriting datasets.
Protecto’s token service plugs into data lakes, warehouses, message buses, vector databases, and LLM pipelines. You can tokenize at ingestion, at query, or at prompt time. The system enforces purpose, scope, and retention automatically.


