
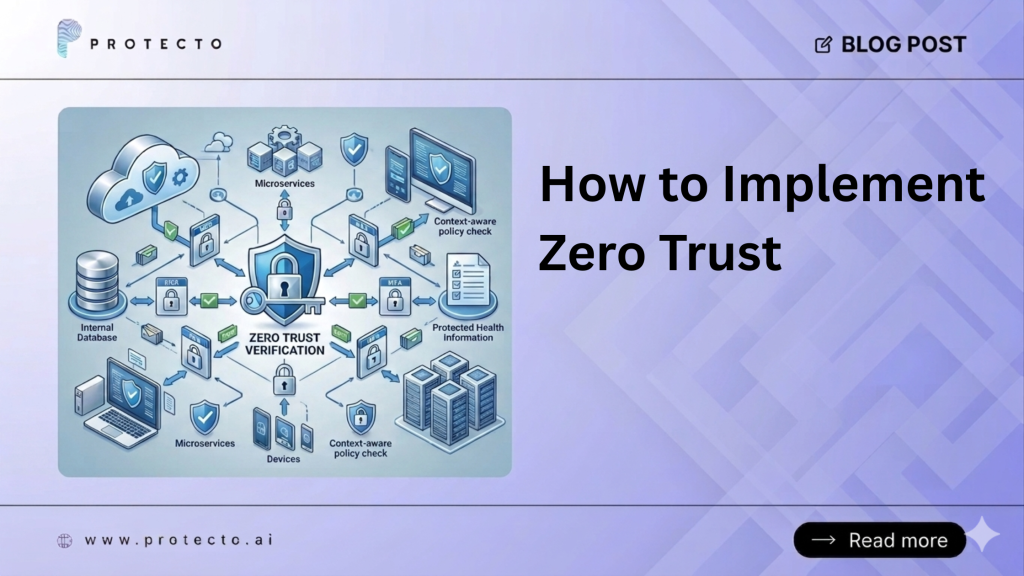
Zero-trust architecture implementation means removing the assumption that anything inside your network is safe. Every request, whether from a user, a device, or an AI agent, is verified before access is granted. The core steps are: define your protect surface, verify identities continuously, enforce least privilege, segment your network, and monitor everything in real time. In AI environments, this requires an additional layer of data-level context control.
Key Takeaways
- Zero-trust implementation starts with defining your protect surface, not your attack surface.
- The three non-negotiable principles are: verify explicitly, enforce least privilege, and assume breach.
- Traditional zero-trust architecture was built for humans and static systems. AI agents break both assumptions.
- Context-based access control enforces data policies when an AI agent uses data, not just at the source.
- Tokenization at ingestion preserves AI accuracy while keeping sensitive values out of the pipeline.
Why Zero-Trust Implementation Matters Right Now
The perimeter is gone.
Most enterprises already know this. But the numbers in 2026 make it impossible to ignore. According to Research and Markets, the zero-trust security market is valued at $54.31 billion in 2026 and is projected to reach $117.94 billion by 2030, growing at a 21.5% CAGR.
According to the Zscaler ThreatLabz 2025 VPN Risk Report, 96% of organizations now favor a zero-trust approach, and 81% plan to implement zero-trust strategies within the next 12 months.
So the question is no longer whether to implement zero trust. It is about doing it without breaking your existing systems or slowing down your teams.
The Core Principles Behind Zero-Trust Architecture
Before walking through the steps, you need to understand what zero trust actually requires. Everything else follows from three principles:
Never trust, always verify. No user, device, or service gets implicit access. Every request is authenticated and authorized, every time.
Enforce least privilege. Entities have access only to what they need for the specific task at hand. Nothing more.
Assume breach. Design your systems as if an attacker is already inside. Limit blast radius. Log everything.
These principles come from NIST Special Publication 800-207, the foundational standard for zero-trust architecture. If your implementation does not map to these three, it is not zero trust. It is just better perimeter security.
How to Implement Zero-Trust Security: A Step-by-Step Guide
Step 1: Define Your Protect Surface
Most teams make the mistake of starting with the attack surface. That is too broad to be useful.
Start with your protected surface first: the specific data, services, applications, and assets that matter most. Patient records. Payment systems. Internal APIs. Source code repositories.
Once you know what you are protecting, everything else gets scoped around it.
Step 2: Map Transaction Flows
You cannot control what you cannot see. Before applying any policy, understand how data moves across your environment. Which users access which systems? What calls what? Where does sensitive data travel?
This mapping exercise is where most organizations first encounter surprises. Systems are communicating with other systems without authentication. Overprivileged service accounts. APIs with broad access that were set up years ago and never revisited.
Step 3: Build a Zero-Trust Architecture
A proper zero-trust architecture implementation includes several layers working together:
Identity and access management (IAM). Every entity, user, service, and device needs a verified identity. Multi-factor authentication is the baseline.
Micro-segmentation. Divide your network into small zones. Lateral movement between zones requires fresh authorization. A breach in one zone does not cascade.
Device health checks. Access decisions factor in device posture, not just credentials.
Policy enforcement points. Access policies are enforced at the point of request, not at the network edge.
Continuous verification. Trust is not granted once at login. It is continuously evaluated based on behavior, context, and risk signals.
Step 4: Apply Least Privilege Access Consistently
Least privilege is one of those principles that sounds simple but is routinely underimplemented. Most environments still have service accounts with admin-level permissions that have gone unaudited for years.
Start with humans. Then move to machine identities, which in most enterprises now outnumber human accounts significantly. Then look at your AI systems, which we will cover separately below.
Step 5: Monitor, Log, and Iterate
Zero trust is not a project you complete. It is a posture you maintain.
Set up centralized logging. Every access request, every decision, every anomaly. Use behavioral analytics to flag deviations from normal patterns. Review access policies quarterly. Revoke what is no longer needed.
Cisco research found that organizations that complete all zero-trust pillars are 2 times less likely to report security incidents, dropping from a 66% to a 33% incident rate. But only 2% of organizations have reached that level of maturity. The gap between starting and finishing is where most teams stall.
Where Traditional Zero Trust Breaks Down: The AI Problem
Here is the thing that most zero-trust guides do not address.
Classic zero-trust frameworks were built for a world of humans and static systems. AI agents do not fit that model.
A Cisco poll of security customers found that 85% of organizations are actively adopting AI agents, yet only 5% report broad production deployments today. The gap exists largely because security teams lack a clear way to govern agent behavior.
AI agents present three specific problems that traditional zero-trust architecture implementation does not solve:
No stable identity. Agents do not log in the way humans do. They chain actions, call APIs, and orchestrate other agents. Traditional RBAC assigns roles based on who is asking. Agents ask on behalf of users, other agents, or automated workflows. The “who” is ambiguous.
Dynamic, non-deterministic access. Static access policies cannot keep up with agents that access data in unpredictable sequences. A sales agent should not see support records. But a standard RBAC rule cannot always catch that in real time.
No audit trail by default. When an agent reads, transforms, and moves data through a pipeline, traditional tools lose visibility into the process. You do not know what the agent saw, what it used, or where it sent it.
The Cloud Security Alliance’s Agentic Trust Framework, published in early 2026, clearly defines the core principle: no AI agent should be trusted by default, regardless of purpose or claimed capability. Trust must be earned through demonstrated behavior and verified continuously.
How to Implement Zero-Trust Security for AI Pipelines
Implementing zero trust in AI environments means adding a data-level control layer on top of your existing network and identity controls.
The goal is to make access decisions when an AI agent requests data, based on identity, role, and context, rather than just whether the agent authenticated successfully.
This is where context-based access control for AI agents comes in. Unlike traditional RBAC, which enforces access at the source, context-based controls enforce access at inference time, the moment the agent actually reads or uses data.
Practically, this means:
Tokenize sensitive data at ingestion. Before data enters your AI pipeline, PII and PHI get replaced with format-preserving tokens. The AI still gets accurate, usable data. The sensitive values never leave your control boundary. This is a core part of secure AI data pipeline design.
Enforce role-based masking dynamically. A support agent sees anonymized records. A supervisor with the right authorization can unmask. The policy applies at the moment of access, not at the database query level.
Log every AI interaction. Who asked, what they saw, when, and why. This is what makes your AI data privacy and compliance posture audit-ready.
Apply data leak prevention at the output layer. Even with good input controls, AI outputs can expose sensitive information. Filtering at the response layer catches what ingestion controls miss. Data leak prevention for AI should be a discrete layer in your stack, not an afterthought.
Protecto applies this approach in production. One example: a global enterprise integrated Protecto across a multi-agent workflow with over 50,000 users. The problem was that standard RBAC controlled database access, but once data entered the AI reasoning layer, role boundaries disappeared. Protecto added real-time context-based masking and a centralized audit trail at the inference layer, without requiring any changes to the underlying data architecture or agent code.
For regulated industries, this is not optional. HIPAA, GDPR, PDPL, and DPDP all assume you know where sensitive data goes and who sees it. In an agentic AI stack, that assumption breaks without an explicit data control layer.
FAQ
What is the difference between zero trust and traditional security?
Traditional security assumes everything within the network perimeter is secure. Zero trust assumes no implicit trust exists anywhere. Every request, internal or external, must be verified and authorized before access is granted.
How long does a zero-trust architecture implementation take?
It depends on the scope. A focused implementation covering identity, access control, and monitoring for a specific environment can go live in a matter of weeks. Enterprise-wide zero-trust maturity across all pillars typically takes 12 to 24 months of iterative work.
Does zero trust work for AI agents and automated systems?
Standard zero-trust frameworks do not adequately cover AI agents. AI agents need context-based access controls that enforce data policies at inference time, not just at the network or database layer. This is a newer layer on top of traditional zero trust.
What is the first step in implementing zero trust?
Define your protective surface. Identify the specific data, systems, and services that carry the most risk if exposed. Then map how they are accessed before building any policies around them.
How does zero trust support compliance with HIPAA, GDPR, or PDPL?
Zero trust creates the audit trail, access logs, and enforcement mechanisms that regulators require. When combined with data-level controls such as tokenization and context-based masking, it provides compliance teams with the evidence they need to demonstrate that sensitive data was accessed only by authorized parties for documented purposes.
