

Every few weeks, a new story surfaces: an AI agent deletes a production database, an autonomous coding tool racks up a five-figure cloud bill, or a chatbot exfiltrates internal documents through a prompt injection attack.
The reaction is predictable. “AI is dangerous.” “LLMs can’t be trusted.” “We need better guardrails on the model.”
But if you look at the root cause of these incidents, the model is rarely the problem. The system around it is. These are failures of privilege management, access control, and architectural discipline. Problems that distributed systems engineers solved decades ago.
What Actually Went Wrong
Let’s look at the common pattern behind MCP-related incidents:
An LLM connected via MCP to a database generates a DELETE statement. The MCP server executes it because the database connection has write access. There was no confirmation step, no scope restriction, no read-only enforcement. The failure was not that the LLM generated a bad query. The failure was that a destructive operation was reachable at all.
The root cause is the same: the MCP server had more privileges than it needed, and nothing in the pipeline enforced boundaries.
This is the architectural equivalent of giving every microservice in your backend a root database password and hoping nothing goes wrong.
The Least Privilege Principle Is Not New
Least privilege is one of the oldest principles in computer security, formalized by Saltzer and Schroeder in 1975. The concept is simple: every component in a system should have only the minimum access required to perform its function, and no more.
In traditional systems, this shows up everywhere: database users get SELECT on specific tables instead of DBA access, API keys are scoped to specific endpoints, service accounts have narrowly defined IAM roles, and deploy pipelines use short-lived credentials.
The principle also distinguishes between deploy-time privileges and runtime privileges. A CI/CD pipeline might need broad access to deploy infrastructure, but the running application should operate with a fraction of those permissions. These are different trust boundaries with different risk profiles.
MCP systems need the same discipline. But in practice, most MCP implementations skip it entirely.
The Common Failure Flow
Here is exactly how it plays out at runtime:
- The LLM receives a user prompt and determines it needs to call an MCP tool
- The LLM generates a tool call with parameters (e.g., update_customer_record with a SET clause)
- The MCP server receives the tool call and forwards it to the backend system
- The backend system executes the operation with whatever privileges the MCP server’s connection has
- Results flow back to the LLM, which incorporates them into its response
At no point in this flow does anything ask: “Should this operation be allowed?” “Is this within the scope of the current task?” “Does the user have authorization for this action?” “Is this a destructive operation that needs confirmation?”
The MCP server acts as a blind relay. The backend system trusts the caller. The LLM has no concept of authorization. Every safety-critical decision falls through the cracks.
System Failures, Not Model Failures
The next time an AI agent causes a production incident, look past the model. Look at the system:
| Question | What You’ll Usually Find |
|---|---|
| What credentials did the MCP server use? | × Admin or overly broad service account |
| Was the tool call validated before execution? | × No validation layer existed |
| Was there a confirmation step for destructive operations? | × Direct execution, no gates |
| Were permissions scoped to the current task? | × Full access to all resources |
| Was there an audit log? | × No logging of tool invocations |
If the answer to most of these is “no,” you don’t have an AI problem. You have a systems engineering problem.
Why This Keeps Happening
Two forces drive this pattern:
Rapid prototyping pressure. MCP servers are often built during hackathons, proof-of-concept sprints, or early integration phases. The fastest path to a working demo is to give the MCP server full access to everything. “We’ll lock it down later” is the standard refrain. Later never comes, or it comes after the first incident.
Lack of architecture discipline in agentic AI. Many engineers building agentic solutions and MCP integrations don’t have distributed systems or security engineering experience. They are experts in model behavior or agentic workflow but may not have deep experience with access control design, threat modeling, or defense-in-depth architecture. The result is systems that are sophisticated in their AI capabilities and naive in their security posture.
This is not a criticism of AI engineers. It is a reflection of how fast the field is moving and how little the tooling and best practices have caught up.
Correct MCP Architecture
A correct architecture requires two things: proper controls before the MCP tool call, and proper design principles inside the MCP.
A properly designed MCP system inserts control layers between the LLM’s intent and the backend’s execution:
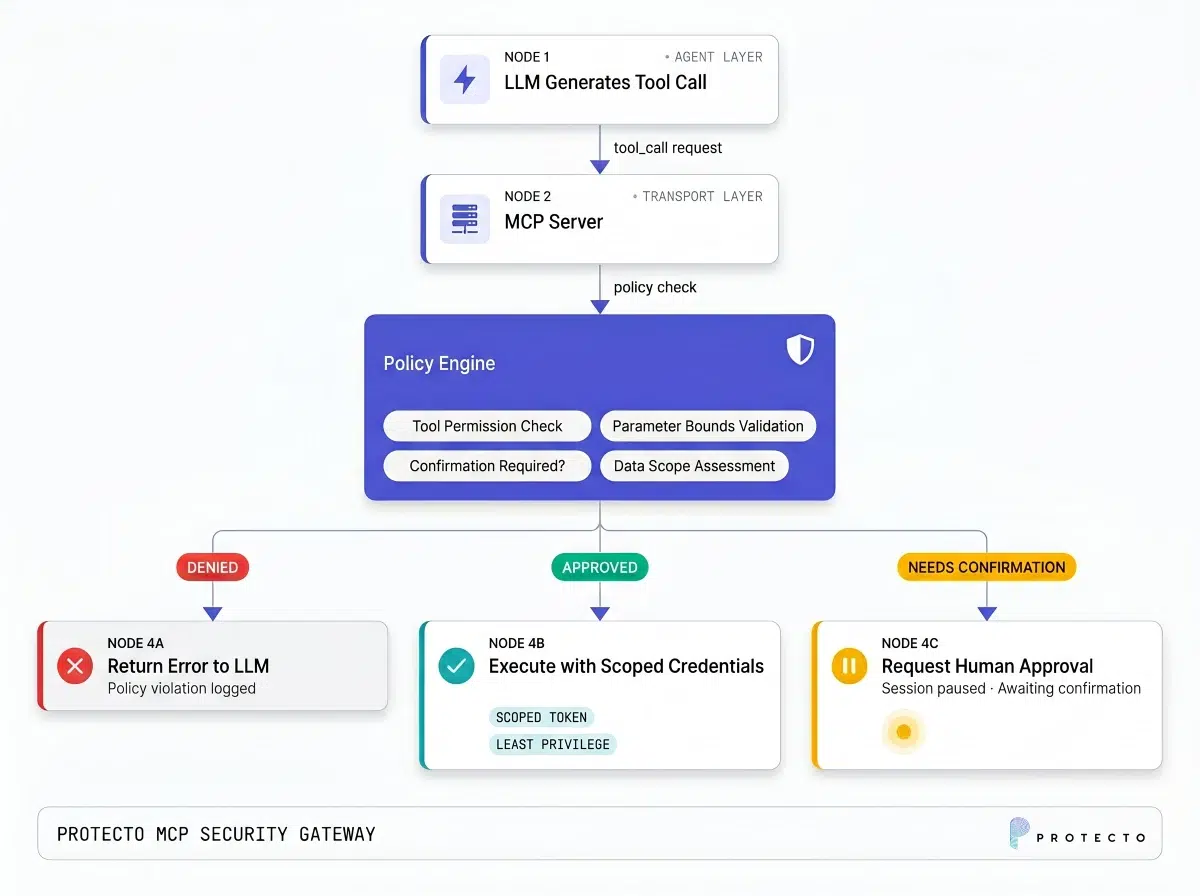
The critical addition is the policy enforcement layer. This sits between the MCP server’s tool dispatch and the actual backend execution. It evaluates every tool call against a set of rules before anything is executed.
Key properties of this layer:
Tool call validation. Check that parameters conform to expected schemas, value ranges, and business rules. If a transfer_funds tool receives an amount of $1,000,000 when the maximum for automated transfers is $10,000, reject it.
Separation of decision and execution. The LLM decides what it wants to do (intent). The policy engine decides whether it is allowed. The backend executes if approved. No single component has both the authority to decide and the power to execute.
Contextual authorization. Evaluate not just “can this role call this tool?” but “can this role call this tool with these specific parameters in this specific session context?”
Dynamic Privilege Control
Static RBAC is a good starting point, but MCP systems benefit from dynamic privilege management:
Context-based permissions. An MCP session handling a customer complaint about Order #12345 should only have access to data related to that order and that task. When the session ends or the context changes, those permissions are revoked. This prevents lateral data access where an agent working on one customer’s issue can access another customer’s records.
Short-lived scoped access. Instead of long-lived API keys or database connections, issue short-lived tokens with narrow scopes for each MCP tool invocation. AWS’s STS (Security Token Service) implements this pattern for cloud resources. The same approach works for MCP: generate a temporary credential that allows a specific operation on a specific resource, and expires after use.
Escalation paths. Some operations legitimately require higher privileges. Instead of granting those privileges by default, implement an escalation flow: the MCP tool requests elevated access, the system routes the request to a human approver or an automated approval policy, and temporary elevated access is granted only if approved.
Solutions like Protecto can complement this architecture by enforcing data-level access controls, ensuring that even when an MCP tool has permission to call a backend API, the data returned is filtered and masked according to the sensitivity classification and the current session’s authorization level.
Discipline in System Design Will Define the Winners
The organizations that successfully deploy MCP-based AI systems at scale will not be the ones with the most capable models. They will be the ones that apply disciplined system design: least privilege, scoped access, validation layers, separation of concerns, and defense in depth.
These are not new ideas. They are the same principles that separate production-grade distributed systems from weekend projects. The only thing that has changed is that AI has raised the stakes. When a human operator has broad access, human judgment provides a (flawed) safety net. When an LLM has broad access, there is no safety net. The system design is the only thing standing between normal operation and catastrophic failure.
Build your MCP systems like you would build any critical infrastructure: with the assumption that every component will eventually do something unexpected, and with controls that limit the blast radius when it does.
