
If you’re building AI applications that touch sensitive data, tokenization isn’t optional. It’s the layer that decides whether your pipeline leaks PHI, PII, or financial data to your LLM, or keeps it protected.
But here’s where most teams stop thinking: not all tokenization is the same. Two approaches you’ll encounter most often are entropy-based tokenization and polymorphic tokenization. They sound similar. They serve completely different purposes. And picking the wrong one for your use case can break your entire data workflow.
Let’s break both down.
First, a Quick Recap: What Is Tokenization?
Tokenization replaces a sensitive value with a non-sensitive stand-in called a token. The original value is stored securely. The token flows through your system, your LLMs, your logs, your analytics pipelines. Nothing sensitive leaks.
A basic example:
| Original Value | Token |
| john.doe@example.com | <EMAIL>0gN3SkjL@0ffM3CDS</EMAIL> |
| John Doe | <PERSON>FreTdf VJYe03W</PERSON> |
| 4111 1111 1111 1111 | <CREDIT_CARD>0743-2291-5567</CREDIT_CARD> |
Clean. Safe. Reversible only when you explicitly allow it.
The question is, how are those tokens generated? That’s where entropy-based and polymorphic tokenization split apart.
What Is Entropy-Based Tokenization?
Entropy, in the security sense, means randomness drawn from unpredictable system-level sources, things like hardware noise, OS-level random number generators, or cryptographic entropy pools.
Entropy-based tokenization uses this randomness to generate tokens that are virtually impossible to reverse-engineer. Even if an attacker knows your tokenization scheme, they can’t reconstruct the original value by brute force.
The key property: deterministic output, entropy-secured generation.
Given the same input, the same namespace, and the same policy, the token is always the same. But the token itself was seeded with high entropy at creation time, so it doesn’t look like the original value, doesn’t contain fragments of it, and can’t be predicted.
“Entropy-based tokenization generates secure tokens based on entropy from system noise, which are virtually impossible to reverse-engineer, delivering maximum security.” — Protecto Privacy Vault Datasheet
This is what Protecto uses under the hood.
What Is Polymorphic Tokenization?
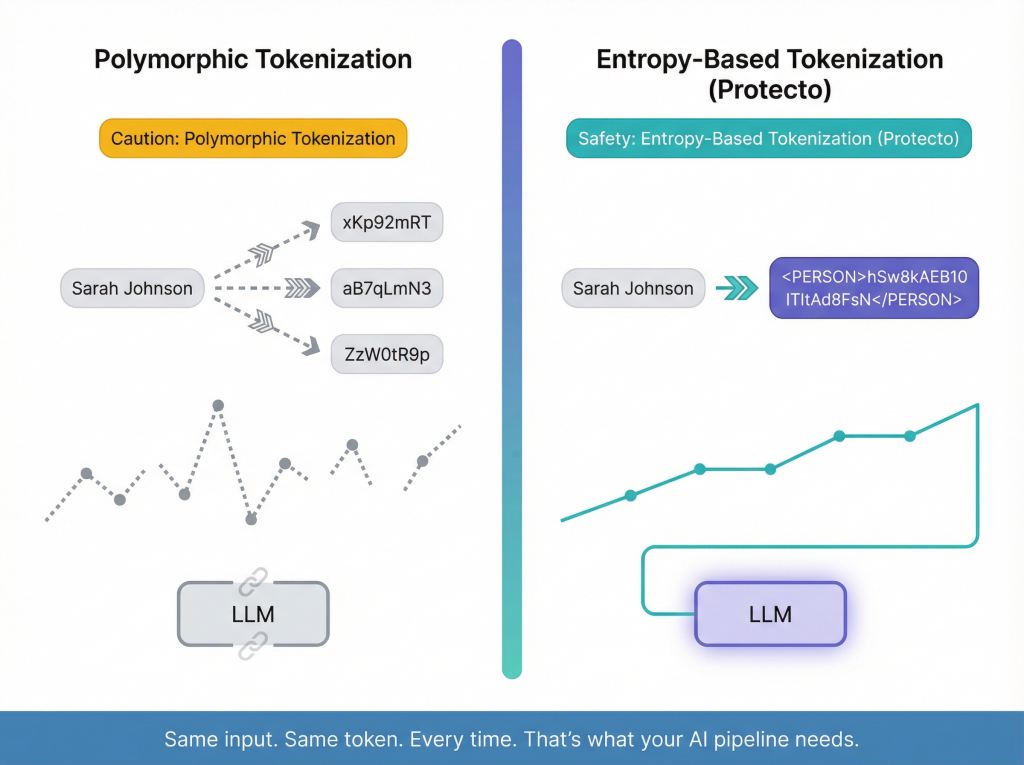
Polymorphic tokenization takes a different approach. Every time you tokenize the same value, you get a different token.
john.doe@example.com → xKp92mRT (first call)
john.doe@example.com → aB7qLmN3 (second call)
john.doe@example.com → ZzW0tR9p (third call)
The idea is that even if someone captures one token, it’s useless the next time the value is tokenized. No two tokens for the same value are linked.
Sounds more secure on paper. In practice, it creates serious problems for AI workflows.
The Core Tradeoff: Determinism vs. Unlinkability
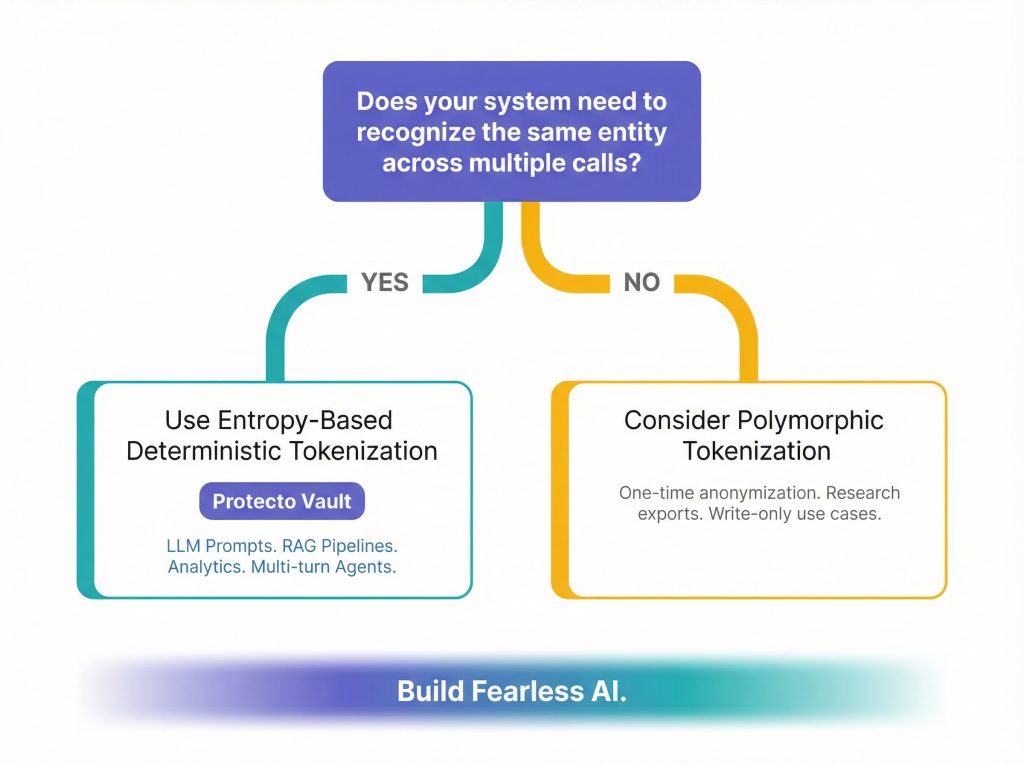
This is the real debate. It comes down to one question: does your system need to recognize the same entity across requests?
| Property | Entropy-Based (Deterministic) | Polymorphic (Non-Deterministic) |
| Same input, same token | ✅ Always | ❌ Never |
| Token reverse-engineering risk | Very low (entropy-secured) | Very low |
| Analytics / BI joins work | ✅ Yes | ❌ No |
| LLM context preserved | ✅ Yes | ❌ No |
| De-duplication possible | ✅ Yes | ❌ No |
| Log consistency | ✅ Yes | ❌ No |
| Ideal for AI pipelines | ✅ Yes | ❌ No |
| Ideal for one-time high-security writes | Possible | ✅ Yes |
Why Polymorphic Tokenization Breaks AI Workflows
Imagine you’re building a RAG-based support chatbot for a healthcare company. A patient named “Sarah Johnson” appears in three documents: her insurance form, a clinical note, and a billing record.
With polymorphic tokenization, Sarah becomes three different tokens across those documents. Your LLM sees three different “people.” Context is lost. Relationships are severed. The AI can’t reason across the patient record correctly.
With entropy-based deterministic tokenization, Sarah is always <PERSON>hSw8kAEB10</PERSON>. Every time. Across every document, every API call, every pipeline run. The LLM sees one consistent, stable entity. It reasons correctly across all three records. It never sees her real name.
For AI systems, determinism isn’t a convenience. It’s a correctness requirement.
Where Protecto Lands on This
Protecto uses entropy-based tokenization, and that’s a deliberate product decision.
The use cases Protecto is built for, LLM prompt protection, RAG pipelines, analytics masking, multi-turn AI agents, all require the same entity to be recognized consistently across calls. You’re not just protecting a write-once database. You’re protecting live, flowing, relational data that an AI is actively reasoning over.
Here’s how this plays out in practice with Protecto’s token types:
| Token Type | Example Input | Example Output | Use Case |
| Default Token | George | <PERSON>FreTdf</PERSON> | General text, names by default |
| Text Token | kumar@ss.fss.com | LEFQS@cTdqGVB2Ay | Emails in logs |
| Numeric Token | (408)-426-9989 | (07432)-29915-56713 | Phone numbers in analytics |
| Special Token | john.doe@example.com | xuLDKEM4bAXh8yIEY1L9 | Mixed PII in payloads |
| Person Token | Williams | Cynthia | Synthetic name replacement (explicit opt-in) |
| Date Token | 6/12/1967 | 0001-06-22 | PHI dates |
One thing worth noting: by default, Protecto replaces names with secure random alphanumeric tokens like FreTdf or hSw8kAEB10 ITItAd8FsN. The Person Token type, which generates a realistic synthetic name like “Cynthia” in place of “Williams”, is an explicitly configured option. You choose it when you want the masked output to remain contextually readable for humans, while the default is optimized purely for security and consistency in machine pipelines.
Each token, regardless of type, is generated with high entropy, stored deterministically, and reversible only under explicit policy and permission.
When Would You Actually Use Polymorphic Tokenization?
To be fair, polymorphic tokenization does have a home. It’s useful in situations where:
- You’re tokenizing a value exactly once (write-only, no reads)
- Linkability across records is a privacy risk you want to eliminate (e.g., anonymization for research exports)
- You’re complying with standards that require unlinkable pseudonyms per transaction
For example, if you’re exporting 10 million patient records to a third-party research institution and you never need to track who is who across that dataset, polymorphic tokenization is a valid approach.
But the moment you’re building an AI agent, running analytics, querying masked logs, or sending data through an LLM pipeline, you need determinism. Polymorphism breaks everything downstream.
The Security Question: Is Entropy-Based Tokenization Actually Safe?
The common concern with deterministic tokenization is: “If the same input always gives the same output, can’t someone reverse-engineer it?”
Short answer: no, not if the entropy is properly sourced.
Protecto’s entropy is drawn from system-level noise, not from the input value itself. The mapping from original value to token is held server-side, not derivable from the token. Even if an attacker captures thousands of tokens, they get nothing useful, because the token carries no mathematical relationship to the original value.
It’s the same logic as a keyed hash. Deterministic output, but the key (entropy seed + vault policy + namespace) is what makes it irreversible without authorized access.
Putting It Together: A Quick Decision Guide
| Your Use Case | Recommended Approach |
| Protecting PII in LLM prompts | Entropy-based (Protecto) |
| Masking data in analytics/BI pipelines | Entropy-based (Protecto) |
| Securing multi-turn AI agent memory | Entropy-based (Protecto) |
| Exporting anonymized research datasets | Polymorphic |
| One-time transaction tokenization | Polymorphic |
| Log masking with future query needs | Entropy-based (Protecto) |
| HIPAA/GDPR-compliant AI applications | Entropy-based (Protecto) |
Bottom Line
Polymorphic tokenization is a privacy technique. Entropy-based deterministic tokenization is a privacy + data utility technique. For AI systems, you need both protection and utility. You need your LLM to reason correctly on masked data. You need your analytics to still work. You need your logs to be queryable.
That’s exactly what Protecto is built for. Not just protecting data, but making sure your AI can still do its job with that data.
If you’re building with LLMs and haven’t thought carefully about your tokenization approach, this is worth revisiting before your next deployment.
Try Protecto’s tokenization API free at www.protecto.ai/trial or reach out at sales@protecto.ai.

