
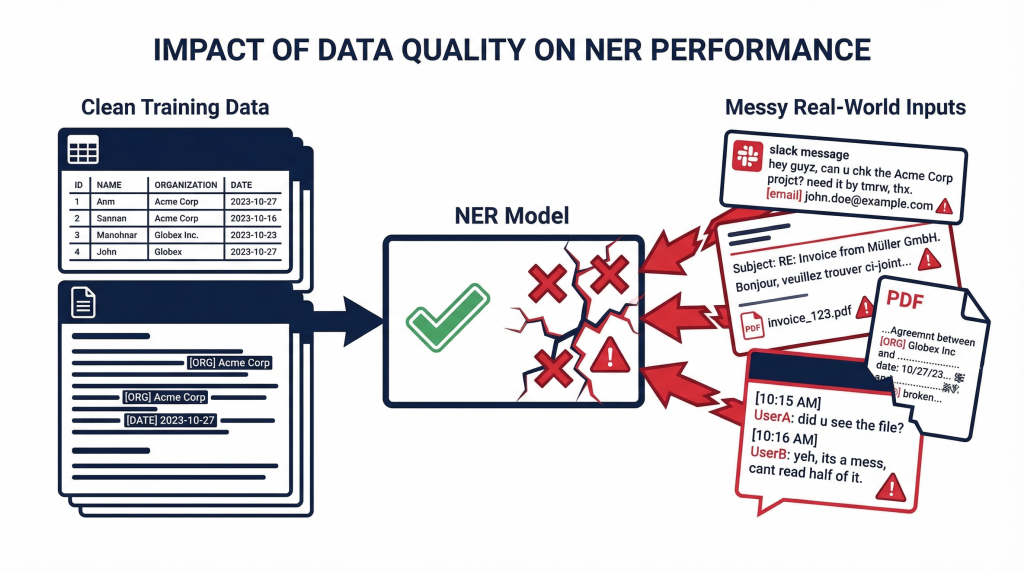
PII detection is the first thing that has to work in AI workflows
In AI systems, PII detection is the first step. Not the most glamorous step. But the one that, when it fails, takes everything else down with it.
Identifying sensitive data (names, Social Security numbers, financial records, health information) has to happen before any of it reaches an LLM. Get this wrong, and you’re looking at one of two bad outcomes:
- False negatives mean sensitive data leaks into LLMs, logs, or external systems.
- False positives mean useful context gets stripped out, and the model starts hallucinating or giving shallow answers.
Traditional DLP systems could afford to be aggressive with detection. LLMs can’t. They depend on full context to generate correct outputs. Remove too much and the model produces garbage. Miss a single entity and you’ve got a compliance exposure.
PII detection in LLM pipelines has to be accurate and context-aware. Pattern-based detection alone doesn’t cut it — as we’ve also seen with why regex fails at PII detection in unstructured text. Most organizations are learning this after deploying, not before.
The assumption that breaks: “NER is enough for PII detection”
Named Entity Recognition (NER) models are the default approach to PII detection at most companies. They’re trained to spot entities like names, emails, phone numbers, and government IDs.
In controlled environments with clean datasets, predictable formats, and a single language, NER works fine. LLM workflows are none of those things. The inputs come from real users typing real messages, and the outputs flow into tools, APIs, and downstream systems that NER was never designed to monitor.
That mismatch between what NER was built for and what LLM workflows actually look like is where PII detection falls apart.
7 places where NER-based PII detection fails in practice
1. Real inputs are messy, not clean
NER models are trained on well-structured, clean datasets. Real LLM inputs look nothing like that. You get typos, abbreviations, partial data references, chat logs pasted in from Slack, broken sentences.
Example:
A user pastes a Slack message into an LLM-powered support tool:
“pls check acct …4321 for J. Smith-Rodriguez, he’s the one from the onboarding thread last wk”
A traditional NER model may miss “J. Smith-Rodriguez” as a name because of the non-standard format. It may fail to flag “acct …4321” as a partial account number. And it will almost certainly ignore “onboarding thread” as a contextual reference to a specific customer record.
The input is real. The PII detection gaps are real. Every abbreviation, typo, or partial reference is a potential missed entity that slips past NER and into your LLM.
2. Multilingual and mixed-context inputs
Users in LLM workflows don’t stick to a single language or format. A document might be in English while the query is in Spanish. Mixed-language prompts are common.
Example:
A user sends this to an LLM summarization tool:
“Can you summarize the PII in this doc? El cliente Juan Perez tiene SSN ending 4589.”
An NER model trained on English misses “cliente” as a person-reference signal. It may not connect “Juan Perez” and “SSN ending 4589” as linked PII because they span two languages. Cross-language entity linking is a known weak spot for single-language NER models, and most PII detection pipelines don’t handle it well.
For global enterprises with multilingual customer bases, this isn’t an edge case. It happens every day, and each missed connection is a PII detection failure that your compliance team won’t hear about until it’s too late.
3. One model can’t handle data variety
Enterprise data is heterogeneous. Structured tables, PDFs, support tickets, chat logs, financial documents. A single NER model rarely works across all of them.
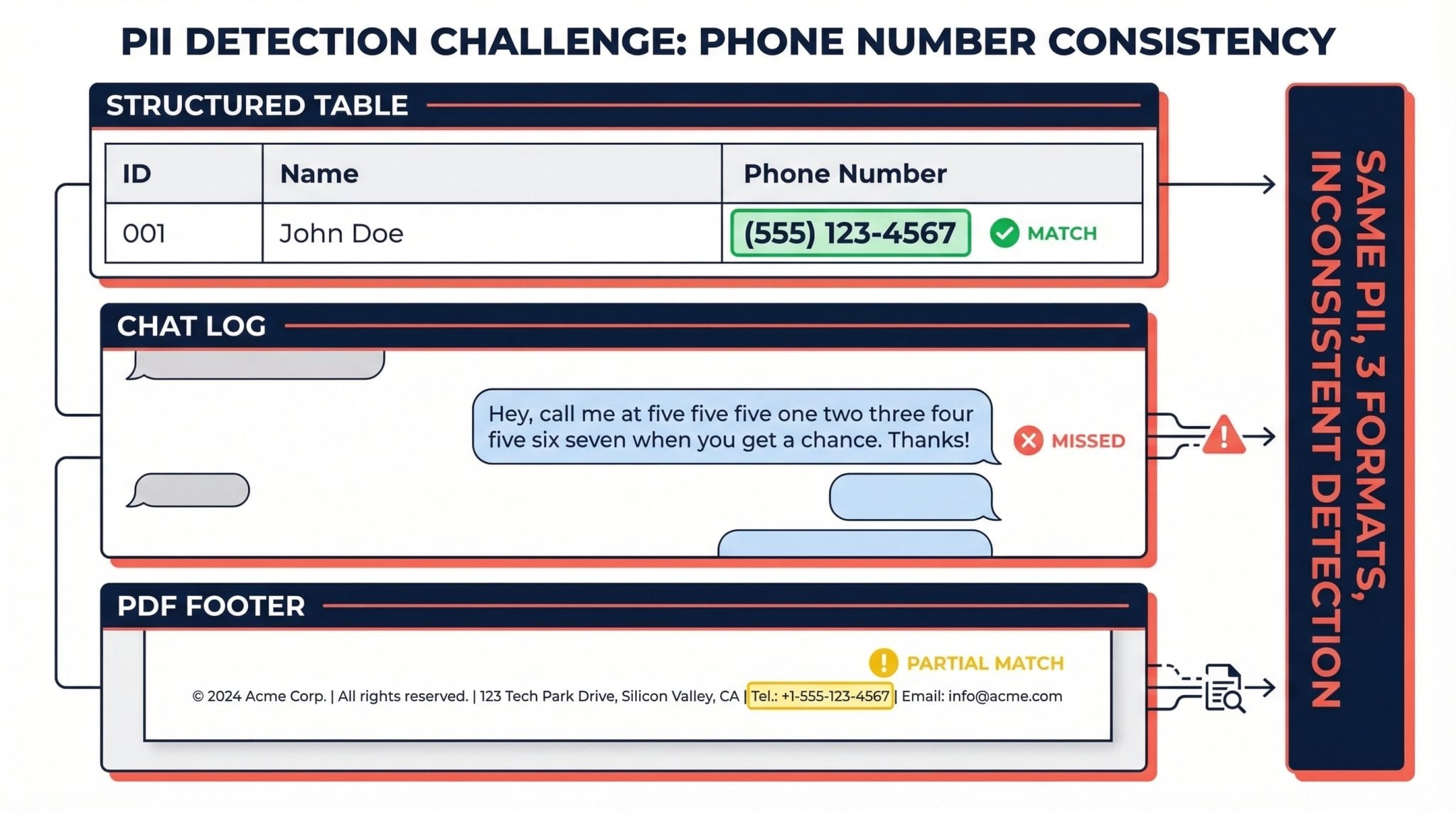
The same phone number looks different depending on where it appears:
- In a table:
(555) 123-4567 - In a chat log:
"call me at five five five one two three..." - In a PDF footer:
Tel.: +1-555-123-4567
What actually happens: teams stack multiple NER models, each tuned for a specific data type. This creates inconsistent PII detection across sources and real operational headaches. One model catches what another misses, and nobody has a unified view of what sensitive data exists in the pipeline.
The burden compounds over time. Each new data source requires evaluation, model selection, testing, and integration. Security teams end up maintaining a patchwork of detection systems, and the gaps between those systems are exactly where sensitive data leaks through.
4. Data formats evolve, NER models don’t keep up
NER models assume relatively stable data distributions. LLM workflows break that assumption constantly. New formats appear as users adopt new tools. New entity types emerge as business processes change. Prompts shift daily.
Example:
Today your system encounters “customer ID” as a field label. Tomorrow the same data shows up as “client ref,” “user token,” or “membership code.”
They all refer to the same thing, but a model trained last quarter doesn’t know that. Keeping PII detection current requires continuous retraining and constant tuning. That’s not scalable in real-time AI systems. Your NER-based detection is always at least slightly behind the data it’s supposed to protect.
5. NER models miss long-range context in PII detection
NER models typically operate at the sentence or short-text level. But sensitive data often depends on context spread across multiple paragraphs or pages.
Example:
- Page 1: “Customer discussed loan restructuring”
- Page 3: “Account number referenced above is 7842-3391”
The account number on page 3 is sensitive because of the financial context on page 1. You only see that when you connect both. NER models see each fragment in isolation. They can’t do the cross-paragraph reasoning needed for accurate PII detection in long documents.
This matters especially in enterprise workflows where LLMs process contracts, legal filings, medical records, and financial reports. In these documents, sensitive context builds across pages, not sentences. An account number by itself might be harmless. An account number three pages after a discussion about loan restructuring for a named individual is a different story entirely. NER doesn’t understand that distinction.
6. Context-based sensitivity that no standard NER model catches
NER models detect predefined categories: Name, Email, Phone, Location. Real enterprise sensitivity goes well beyond those standard PII types. Think contract clauses with confidential terms, financial thresholds, internal identifiers, project codenames.
Example:
“Project Titan launches Q3”
To a standard NER model, this looks like a harmless project update. But internally, “Project Titan” is a codename for an unannounced acquisition. That’s information that could move markets or violate disclosure rules.
Sensitivity here is organization-specific, not category-specific. Neither NER nor a standalone LLM will flag it without enterprise context. You need a configurable policy layer where you define org-specific terms, codenames, and sensitivity rules, and the detection system uses those as context.
This is one of the most overlooked gaps in PII detection. Most discussions focus on standard entity types like names and SSNs. But in practice, the data exposures that cause board-level incidents often involve information that doesn’t fit any standard category. A leaked codename. A deal value shared in the wrong context. An internal identifier that maps to a real customer. Static pattern matching can’t catch these. An LLM-based approach, paired with enterprise-specific policies, can.
7. Latency from multi-model PII detection pipelines
To compensate for the gaps above, teams often chain multiple NER models in their PII detection pipeline. Model A catches names. Model B handles financial data. Model C covers domain-specific entities.
Each model adds 50-200ms of latency. Chain three and you’re adding half a second per request. At 10,000 daily queries, that’s real compute cost and noticeable user friction.
In LLM workflows, PII detection has to happen inline. In real-time applications like customer support bots or co-pilot interfaces, half a second matters. Users notice. Throughput drops. Operations teams start looking for shortcuts that compromise security. When the choice is between a slow, secure workflow and a fast, unprotected one, speed usually wins.
What happens downstream when PII detection fails
When PII detection fails, the damage isn’t contained. It ripples across the entire AI system:
Missed entities lead to data exposure and compliance violations. Regulators don’t accept “our NER model missed it” as an excuse under HIPAA, GDPR, or PCI-DSS. (For a deeper look at what’s required, see our LLM privacy compliance guide.)
Over-detection breaks context, which leads to poor AI outputs. LLM workflows punish both false positives and false negatives. Unlike traditional DLP where you can lean toward over-detection and tolerate the noise, LLMs need full context to reason correctly. Over-redact and you get hallucinations or useless outputs.
Inconsistent detection creates unpredictable behavior across workflows. Teams lose trust in the system and start building workarounds that introduce even more risk.
Bad PII detection means broken AI and increased compliance risk. And unlike a traditional security breach (which is a discrete event), failed detection in LLM workflows creates a continuous leak. Every query with undetected PII is a potential exposure. At enterprise scale, that can mean thousands of exposures per day.
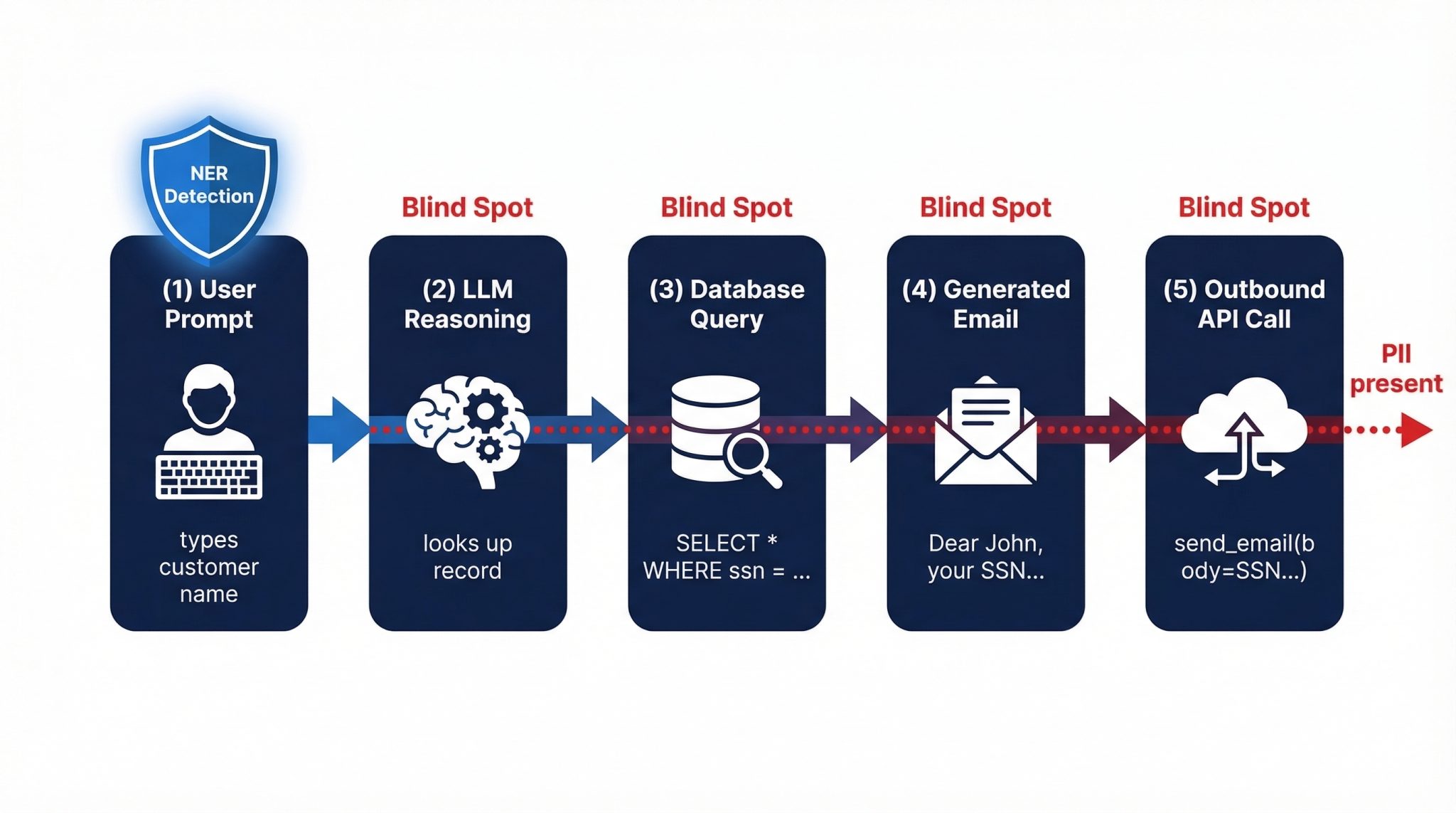
The blind spot: PII in tool calls and agentic actions
LLMs don’t just generate text anymore. They call APIs, write SQL queries, send emails, trigger downstream actions. Sensitive data shows up in places NER models were never designed to look:
- Function arguments:
send_email(to="john@example.com", body="SSN is 412-55-6789") - SQL queries generated by the LLM:
SELECT * FROM customers WHERE ssn = '412-55-6789' - Tool outputs returned to the model for further reasoning
If your NER-based detection only scans the user prompt, you’re missing the surface area where data leaks actually happen. Agentic LLM workflows, where models take autonomous actions, make this worse because every tool call is a potential exfiltration vector.
Think about a typical enterprise use case: an LLM-powered assistant that helps customer service agents draft responses. The agent types a customer name. The LLM looks up the customer record, drafts an email, and calls an API to send it. PII has now traveled through the prompt, the model’s reasoning, a database query, the generated email body, and an outbound API call. A PII detection system that only monitors the first step is blind to the other four.
Why NER alone can’t solve PII detection in LLM workflows
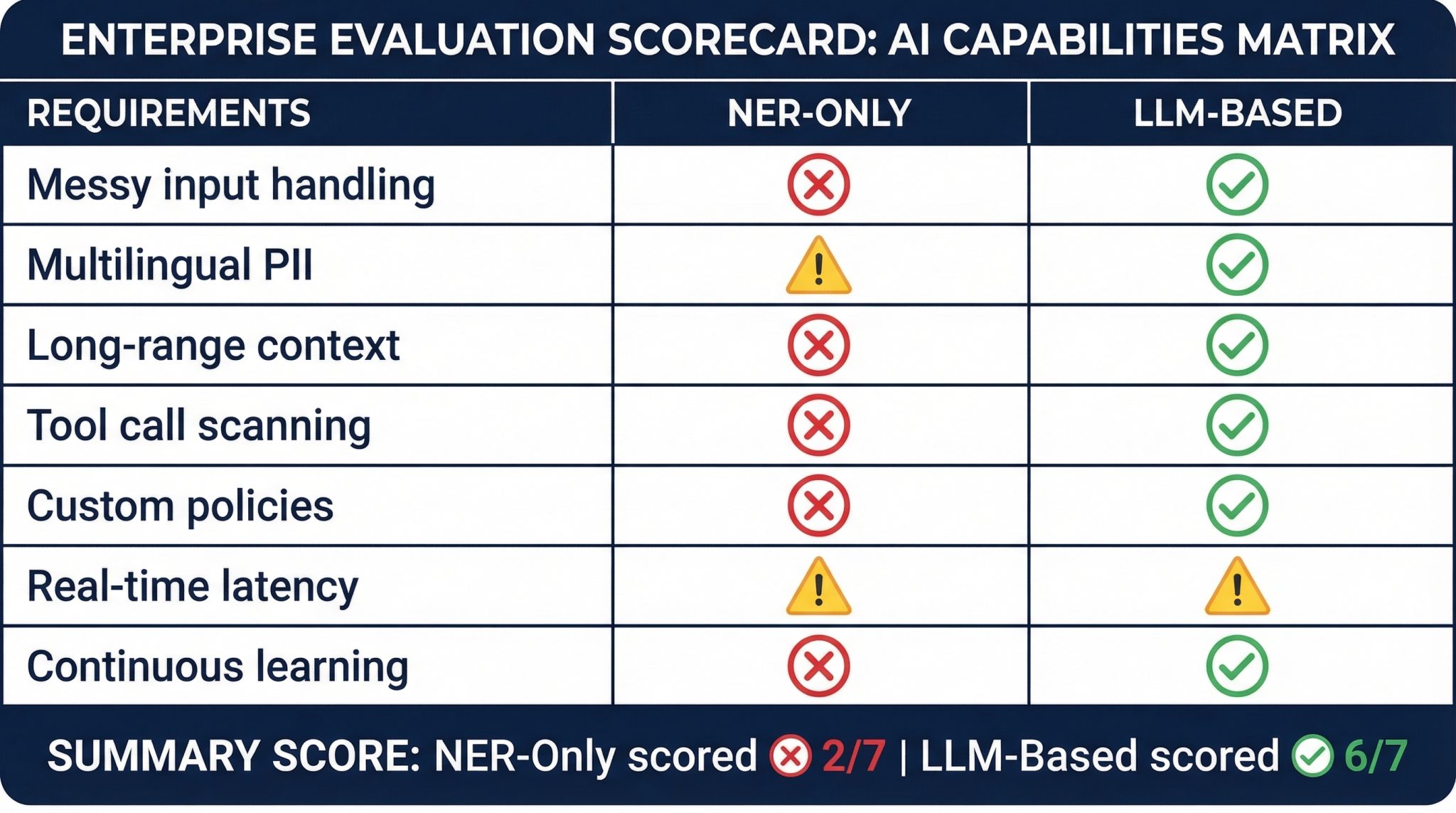
NER models were built for structured NLP tasks. LLM workflows need something different:
- Handling messy, user-generated inputs with typos, abbreviations, and mixed formats
- Understanding domain-specific data that changes faster than models can be retrained
- Preserving context across long documents and multi-turn conversations
- Detecting sensitive data in tool calls, API responses, and agentic actions
- Supporting organization-specific policies, codenames, and custom sensitivity rules
These aren’t the problems NER was designed to solve.
Swapping NER for an LLM doesn’t automatically fix all of these. Organization-specific sensitivity requires configurable policies. Long-range context requires pipeline design that preserves document-level relationships. The difference is that LLM-based approaches can be built to handle these cases. NER-only pipelines structurally cannot.
NER has value for well-defined entity types in clean data. The question is whether NER alone is enough for PII detection in production LLM systems. Based on everything above, the answer is no.
Many organizations started by bolting existing NER-based detection onto new LLM pipelines. That was a reasonable first step. But LLM use cases have expanded from simple summarization to multi-step agentic workflows that call tools, generate code, and make autonomous decisions. The requirements for accurate detection have outgrown what NER can deliver. Organizations need data leak prevention designed specifically for AI rather than legacy tools stretched beyond their original purpose.
How to evaluate whether your PII detection approach is ready
If you’re running NER-based detection today, here are the questions worth asking before your next LLM deployment.
Start with coverage. Does your system detect sensitive data across all input types, including structured tables, free-text prompts, chat logs, and pasted documents? Or does it only work reliably on one or two formats? Most NER setups were built for structured data first and everything else second. That’s a problem when your LLM is ingesting Slack threads and email chains.
Then look at language support. Can your pipeline identify PII in mixed-language inputs, or is it English-only? For global enterprises, this is a hard requirement. If your team operates across regions, your data already crosses language boundaries whether your detection system is ready for it or not.
Context window matters too. Can your detection system connect a name on page 1 to an account number on page 5, or does it treat every paragraph as an island? Long-range context is where NER fails most visibly, and where the highest-risk data exposures tend to occur.
Check your output coverage. Are you scanning what the LLM generates, not just what users type? Function calls, SQL queries, API requests, all of these can carry PII. If your detection only covers the input prompt, you’re blind to a growing share of the actual risk surface.
Look at policy flexibility. Can you define custom sensitivity rules covering internal codenames, project identifiers, and business-specific terms? Or are you stuck with whatever entity categories your NER model shipped with? If your detection can’t be configured for your business, it’s solving a generic problem, not your problem.
And finally, latency and freshness. Does your detection pipeline run within your latency requirements? If you’re chaining multiple models and adding 500ms+ per request, your engineering team is probably already under pressure to bypass the detection step entirely. And how often are you retraining? If it’s quarterly or less, your detection accuracy is degrading between updates.
None of these questions are pass/fail on their own. But if several answers make you uncomfortable, NER-only detection probably isn’t the right foundation for your LLM security posture.
What this means for your PII detection strategy
If you’re relying solely on NER models for PII detection in LLM pipelines, you’re operating on assumptions that no longer hold. The data is messier, the formats are more varied, the languages are mixed, and the attack surface now includes tool calls and autonomous actions that NER was never built to inspect.
The choice facing teams today is whether their current approach can handle the realities of modern LLM workflows, or whether they’re carrying a false sense of security based on tools from a different era.
What comes next
The shift from pattern-matching to context-aware detection is already underway. Organizations that recognized these NER limitations early are already building PII detection systems that combine the speed of pattern matching with the contextual understanding of LLMs. The question for most teams isn’t whether to make the move. It’s how quickly they can do it without disrupting the workflows they’ve already deployed.
