
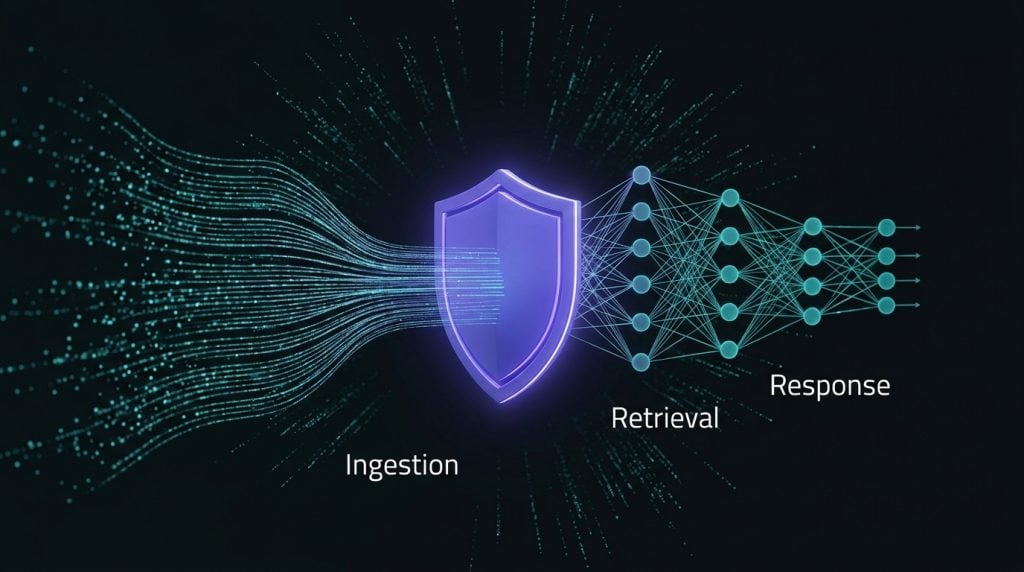
Every enterprise wants to use AI on its most valuable data — customer records, financial documents, clinical notes, legal files, engineering IP. The problem is simple: the moment that data enters an AI workflow, traditional security stops working.
Firewalls protect the network. Encryption protects data at rest. Access controls protect the database. But none of them protect what happens when an AI agent retrieves five documents, synthesizes an answer, and delivers it to a user. That is the context layer. AI context security is the discipline that secures it.
What AI context security is?
AI context security is the runtime layer that protects sensitive data as it enters, flows through, and exits AI systems.
It answers a question no other security category addresses: given who is asking, what they are working on, and why they need the answer, what is this AI system allowed to know, use, and reveal?
This is not a policy you write once and audit quarterly. It is enforcement that happens in milliseconds, on every query, across every user and every agent, at the point where data becomes a response.
AI context security covers four functions.
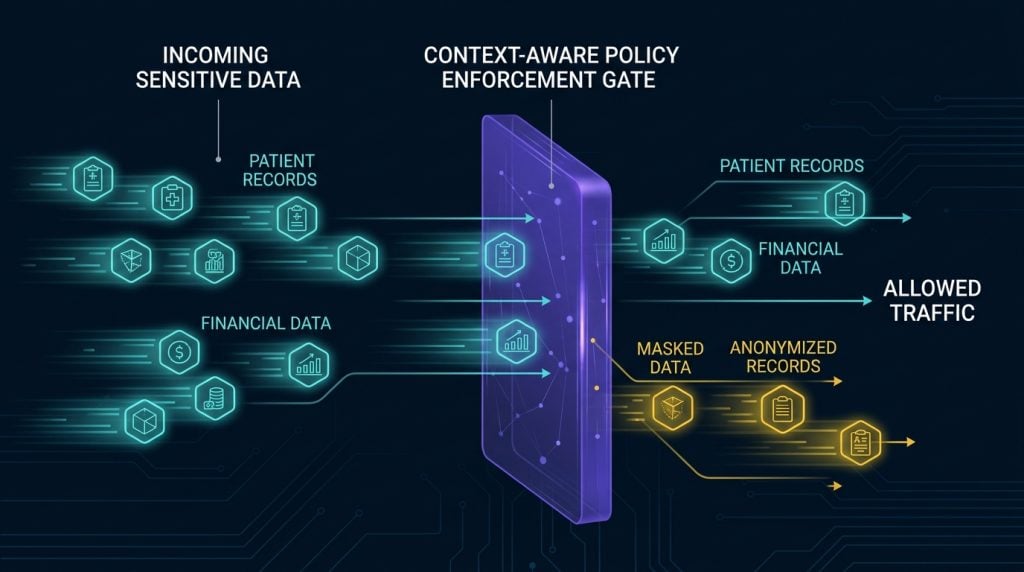
Protecting data at ingestion. Sensitive data is tokenized and policy-tagged before it enters the vector store or knowledge base. Protection starts from the moment data arrives, not after.
Controlling what flows into reasoning. When an AI system retrieves documents to build an answer, AI context security enforces which content can participate in that synthesis, based on the user’s role, clearance, or purpose. This is not document-level access control. It is content-level policy enforcement on the reasoning path.
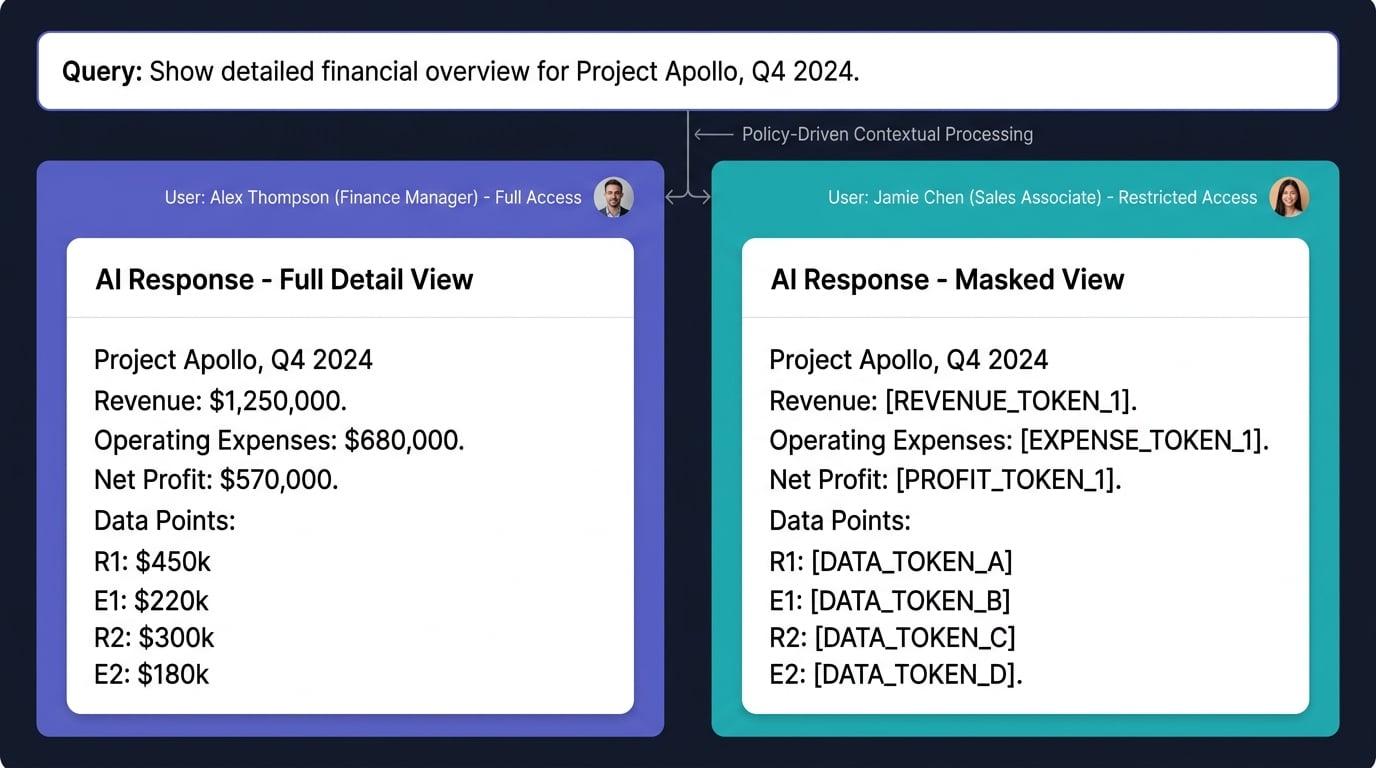
Shaping the output. The same query from two different users can produce two different answers from the same underlying data. One user sees full detail. Another sees de-identified patterns. A third sees nothing. No separate data copies, no duplicated corpus — policy-driven views applied at the response layer.
AI context security enforcing different data views from the same dataset for different usersLogging every decision. Every retrieval, every policy enforcement, every masking decision is traced. Full audit trail of what data was used, what was withheld, and why.
What AI context security is not
Understanding what AI context security covers means being clear about what it does not.
It is not prompt defense
Prompt injection, jailbreaking, and guardrails protect the model from bad inputs. The OWASP LLM Top 10 documents these input-based attack vectors in detail. AI context security is a separate concern — it protects the data from unauthorized use, not the model from adversarial prompts. Different problem.
It is not DLP
Data loss prevention blocks sensitive data from leaving the enterprise. But without data, AI is not useful. The goal is not to block data; it is to allow enterprise data into AI workflows while keeping sensitive information protected. DLP watches the exit. AI context security controls the entire path, from ingestion to retrieval to response, making sure data is usable but never exposed to the wrong user or agent.
It is not AI governance
Frameworks like the NIST AI Risk Management Framework define policies, track model risk, and produce compliance reports. AI data governance says what should happen. AI context security makes it happen — enforcing those policies in real time at the data layer, on every query, for every user and every agent.
It is not traditional masking
Traditional masking replaces sensitive values with random tokens. That works for databases. It destroys AI. Masked names, masked entities, and masked context kill retrieval accuracy because the search engine can no longer match what it needs. AI context security uses context-preserving tokenization that maintains the semantic relationships AI needs to deliver accurate results.
Why sensitive data goes beyond PII
Most AI data security tools stop at named entities: names, SSNs, medical record numbers. In practice, sensitive data is a paragraph about a proprietary pricing strategy, a section describing unreleased product IP, a salary buried in an HR document, or a legal opinion in a privileged memo.
It is not just fields in a database. It is sentences, sections, and context buried in unstructured documents. AI context security has to understand what is sensitive at the content level, not just the entity level, and ensure it stays protected while still letting the right users get the answers they need.
Why it is hard
Any vendor can mask a name. The hard part is masking it consistently across every document in the corpus, maintaining referential integrity so analysis still works, enforcing different views for different users in real time, and doing all of this at the retrieval layer in RAG security architectures so protected data never enters the wrong synthesis path.
Traditional masking gives you security but kills accuracy. Open access gives you accuracy but creates liability. AI context security needs to deliver both.
The complete protection loop covers four stages: secure ingestion, context-aware retrieval, policy-enforced response, and a full audit trail. Solving any one piece in isolation does not work. The ingestion has to know the policies. The retrieval has to respect the policies. The response has to reflect the policies. And the audit has to prove all of it.
Why agentic AI security makes this urgent
Two things changed.
First, enterprises moved from single chatbots to thousands of autonomous agents. Agents retrieve, reason, and act without human review. The security boundary that human judgment once provided is gone. Every agent needs its own policy-enforced view of the data, and agentic AI security starts at the context layer.
Second, the data moving into AI is not public web data. It is the most sensitive information the enterprise owns: client files, patient records, financial models, legal precedents. The industries with the most to gain from AI — finance, healthcare, legal, government — are the same industries where a single data exposure can trigger regulatory action, litigation, or a permanent loss of trust.
AI context security is not optional for these industries. It is the prerequisite that determines whether AI moves from pilot to production.
If you want to see how AI data governance, LLM data security, and context-aware access control work together in a production environment, Protecto’s Secure RAG platform was built specifically for this layer.
