
Data security is a critical concern for businesses across the globe. Sensitive information, including payment details, customer records, and personal identifiers, faces constant threats from cyberattacks and unauthorized access.
Techniques like data masking vs tokenization offer robust solutions to safeguard this data, ensuring privacy and compliance. Understanding the difference between data masking and tokenization is essential for organizations aiming to implement effective data protection strategies.
Both data masking and tokenization play significant roles in protecting sensitive information, ensuring compliance with regulations like GDPR and HIPAA, and maintaining customer trust. This guide explores their definitions, differences, and practical applications to help businesses make informed decisions. Organizations often compare tokenization vs masking when choosing the right data protection method, as each approach offers different levels of security, flexibility, and usability depending on the use case.
What is Data Masking?
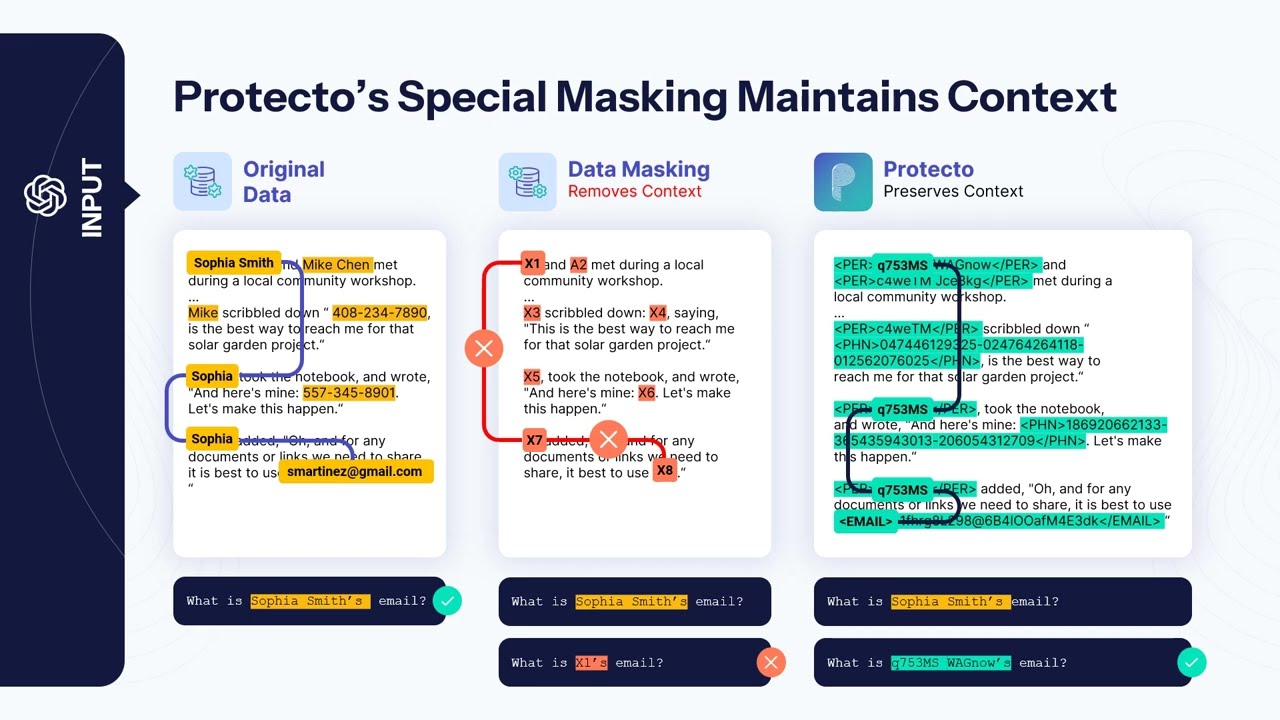
Data masking alters sensitive information to obscure its original value while maintaining its usability for specific purposes. This method ensures that data appears realistic but remains unusable for unauthorized access or malicious activities. It is commonly used in non-production environments where data security is paramount.
Methods of Data Masking
- Static Masking: This technique modifies data at rest in databases. It is ideal for creating secure non-production environments like testing or development systems.
- Dynamic Masking: Applies masking in real-time during data access. This method is often used in live environments to limit exposure to sensitive data.
- On-the-Fly Masking: Masks data during transfers, ensuring secure movement between systems without exposing sensitive information.
Interested Read: Static Data Masking vs. Dynamic Data Masking
Scenarios for Data Masking
Data masking is widely applied in various contexts:
- Testing Environments: Developers can work with realistic datasets without exposing sensitive information.
- Compliance: Ensures that sensitive information remains protected during audits and certifications.
- Training: Provides anonymized datasets for employee training, safeguarding actual data from potential misuse.
- Cloud Migration: Protect sensitive data during transitions to cloud environments.
What is Tokenization?
Tokenization replaces sensitive data with unique tokens. These tokens hold no intrinsic value and can only be mapped back to the original data through a secure token vault. Tokenization is particularly effective for securing transactional systems and live environments.
How Data Tokenization Works
- Sensitive data is replaced with a randomly generated token.
- The mapping between the token and the original data is securely stored in a token vault.
- Authorized systems can retrieve the original data when necessary, ensuring secure operations without exposing sensitive details.
Applications of Tokenization
Tokenization is widely used across industries:
- Payment Processing: Secures credit card numbers and transaction details during online and in-store payments.
- Healthcare: Protects PII and PHI to comply with HIPAA and other healthcare data regulations.
- Cybersecurity: Safeguards sensitive customer and employee information from breaches.
- Retail: Secures customer payment details during point-of-sale transactions.
Interested Read: The Ultimate Guide to Data Tokenization
Key Differences Between Data Masking and Tokenization

This comparison highlights the difference between data masking and tokenization, helping organizations choose the right approach based on their data security needs.
Functionality
- Data Masking: Alters data permanently for specific use cases, such as testing, training, or analytics.
- Tokenization: Replaces data with tokens that can be reversed under strict controls, ensuring secure access to the original data when needed.
Reversibility
- Data Masking: Designed to be irreversible, ensuring that masked data cannot be restored to its original form.
- Tokenization: Reversible, allowing authorized systems to retrieve the original data securely.
Use Cases
- Data Masking: Best suited for non-production environments, such as development and testing systems.
- Tokenization: Ideal for securing live data in transactional systems and operational environments.
Compliance Benefits
Both methods support compliance with GDPR, HIPAA, and PCI DSS. However, tokenization provides enhanced security for payment data, making it a preferred choice for financial transactions and e-commerce platforms.
Use Cases of Data Masking
- Software Testing: Protects sensitive information while providing realistic datasets for developers.
- Data Analytics: Enables analysis of anonymized data without compromising confidentiality.
- Employee Training: Ensures that training environments mimic real-world scenarios while safeguarding actual information.
- Research and Development: Provides secure access to realistic datasets for innovation and experimentation.
- Third-Party Collaboration: Ensures that external vendors or partners can work with anonymized data without accessing sensitive details.
Use Cases of Tokenization
- Payment Systems: Protects credit card details and transaction data during payment processing.
- Healthcare Records: Secures PHI and PII while allowing authorized personnel to access necessary information.
- Customer Data Protection: Safeguards sensitive customer information stored in CRM systems.
- E-commerce: Ensures secure handling of customer payment details and personal information during online transactions.
- Fraud Prevention: Reduces the risk of data misuse by replacing sensitive information with tokens.
Data Masking and Tokenization in Cyber Security

Both data masking and tokenization play critical roles in cyber security. Masking ensures that even if unauthorized individuals access data, it remains unusable. Tokenization protects live systems by replacing sensitive data with tokens, rendering the information meaningless to attackers.
These techniques also mitigate risks associated with data breaches, ensuring that businesses can maintain operations without exposing sensitive information. By implementing these methods, organizations can significantly reduce their vulnerability to cyberattacks. Tokenization, in particular, provides an added layer of security for transactional data, making it an indispensable tool for industries like finance and retail.
These methods are often used alongside data privacy controls in AI systems to reduce risks in modern applications
Choosing Between Data Masking and Tokenization
Selecting the right technique between data masking and tokenization depends on several factors:
- Purpose: Data masking is ideal for non-production environments, while tokenization is better suited for live systems.
- Industry Requirements: Payment processors benefit more from tokenization, while testing teams rely on masking for secure development.
- Compliance Needs: Both methods align with regulatory standards, but tokenization offers additional security for financial transactions.
- Data Sensitivity: Highly sensitive data, such as credit card numbers, often requires tokenization for added security.
- Operational Needs: Businesses with frequent data exchanges may find tokenization more practical while masking suits static data scenarios.
Conclusion
Understanding the differences between data masking vs tokenization is essential for adequate AI data protection. Both methods are vital in securing sensitive information, meeting compliance requirements, and maintaining customer trust. Organizations can implement the right solutions to protect their data by evaluating their use cases and benefits.
Embracing these techniques strengthens cyber security strategies, reduces risks, and ensures regulatory compliance. As data security grows, leveraging methods like data masking and tokenization will remain critical for safeguarding sensitive information in an increasingly digital world. Organizations should prioritize these methods and invest in solutions like Protecto to safeguard their data assets and maintain competitive advantages in their respective industries.
FAQs
What is the difference between data masking and tokenization?
Data masking hides sensitive data permanently, while tokenization replaces data with reversible tokens stored securely.
When should you use tokenization vs masking?
Tokenization is used for live systems, while masking is better for testing and non-production environments.
Is tokenization more secure than data masking?
Tokenization is generally more secure for transactional data because it allows controlled access to original values.
Can data masking and tokenization be used together?
Yes, organizations often use both techniques to enhance overall data protection.
